
Dynamiczne skrobanie stron internetowych za pomocą Pythona – poradnik
Opublikowany: 2024-06-08Dynamiczne skrobanie sieci polega na pobieraniu danych ze stron internetowych, które generują treści w czasie rzeczywistym za pomocą JavaScript lub Python. W przeciwieństwie do statycznych stron internetowych, zawartość dynamiczna ładuje się asynchronicznie, co sprawia, że tradycyjne techniki skrobania są nieefektywne.
Dynamiczne skrobanie sieci wykorzystuje:
- Strony internetowe oparte na technologii AJAX
- Aplikacje jednostronicowe (SPA)
- Witryny z opóźnionym ładowaniem elementów
Kluczowe narzędzia i technologie:
- Selenium – automatyzuje interakcje przeglądarki.
- BeautifulSoup – analizuje zawartość HTML.
- Żądania — pobiera zawartość strony internetowej.
- lxml – analizuje XML i HTML.
Python do dynamicznego skrobania sieci wymaga głębszego zrozumienia technologii internetowych, aby skutecznie gromadzić dane w czasie rzeczywistym.
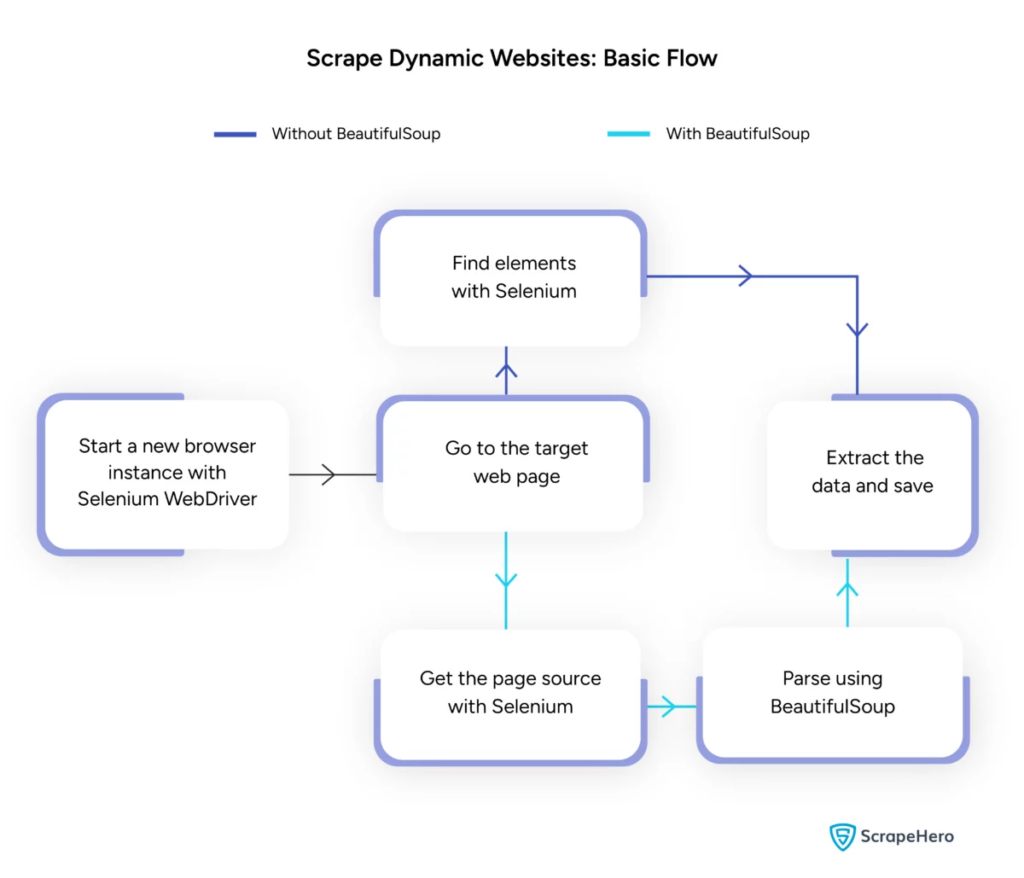
Źródło obrazu: https://www.scrapehero.com/scrape-a-dynamic-website/
Konfigurowanie środowiska Python
Aby rozpocząć dynamiczne skrobanie sieci w Pythonie, konieczne jest prawidłowe skonfigurowanie środowiska. Wykonaj następujące kroki:
- Zainstaluj Python : Upewnij się, że Python jest zainstalowany na komputerze. Najnowszą wersję można pobrać z oficjalnej strony Pythona.
- Utwórz wirtualne środowisko :

Aktywuj środowisko wirtualne:

- Zainstaluj wymagane biblioteki :

- Skonfiguruj edytor kodu : użyj IDE, takiego jak PyCharm, VSCode lub Jupyter Notebook, do pisania i uruchamiania skryptów.
- Zapoznaj się z HTML/CSS : Zrozumienie struktury strony internetowej pomaga w skutecznej nawigacji i wyodrębnianiu danych.
Te kroki stanowią solidną podstawę dla dynamicznych projektów Pythona do skrobania sieci.
Zrozumienie podstaw żądań HTTP
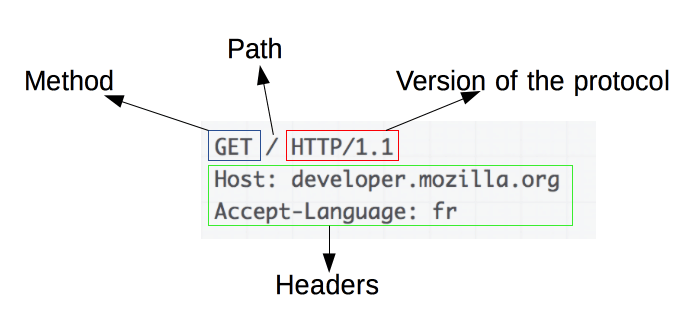
Źródło obrazu: https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview
Żądania HTTP są podstawą skrobania sieci. Gdy klient, na przykład przeglądarka internetowa lub skrobak sieciowy, chce pobrać informacje z serwera, wysyła żądanie HTTP. Żądania te mają określoną strukturę:
- Metoda : Akcja, która ma zostać wykonana, np. GET lub POST.
- URL : adres zasobu na serwerze.
- Nagłówki : metadane dotyczące żądania, takie jak typ zawartości i klient użytkownika.
- Treść : opcjonalne dane wysyłane wraz z żądaniem, zwykle używane przy użyciu metody POST.
Zrozumienie, jak interpretować i konstruować te komponenty, jest niezbędne do skutecznego skrobania sieci. Biblioteki Pythona, takie jak żądania, upraszczają ten proces, umożliwiając precyzyjną kontrolę nad żądaniami.
Instalowanie bibliotek Pythona
Źródło obrazu: https://ajaytech.co/what-are-python-libraries/
Aby uzyskać dynamiczne skrobanie sieci za pomocą języka Python, upewnij się, że język Python jest zainstalowany. Otwórz terminal lub wiersz poleceń i zainstaluj niezbędne biblioteki za pomocą pip:
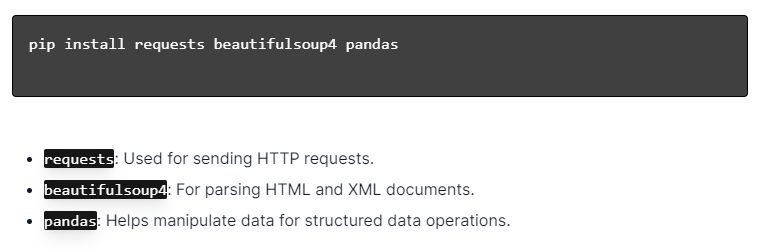
Następnie zaimportuj te biblioteki do swojego skryptu:

W ten sposób każda biblioteka zostanie udostępniona do zadań związanych z przeglądaniem stron internetowych, takich jak wysyłanie żądań, analizowanie kodu HTML i wydajne zarządzanie danymi.
Budowanie prostego skryptu do skrobania sieci
Aby zbudować podstawowy skrypt do dynamicznego przeglądania stron internetowych w Pythonie, należy najpierw zainstalować niezbędne biblioteki. Biblioteka „requests” obsługuje żądania HTTP, natomiast „BeautifulSoup” analizuje zawartość HTML.
Kroki do naśladowania:
- Zainstaluj zależności:

- Importuj biblioteki:

- Pobierz treść HTML:
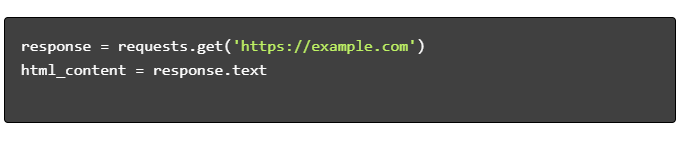
- Przeanalizuj kod HTML:

- Wyodrębnij dane:

Obsługa dynamicznego skrobania sieci w języku Python
Dynamiczne strony internetowe generują treści na bieżąco, często wymagając bardziej wyrafinowanych technik.

Rozważ następujące kroki:
- Zidentyfikuj elementy docelowe : sprawdź stronę internetową, aby zlokalizować zawartość dynamiczną.
- Wybierz środowisko Python : wykorzystaj biblioteki takie jak Selenium lub Playwright.
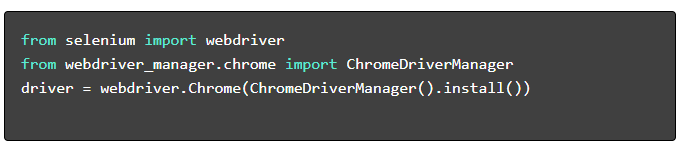
- Zainstaluj wymagane pakiety :
- Skonfiguruj WebDriver :

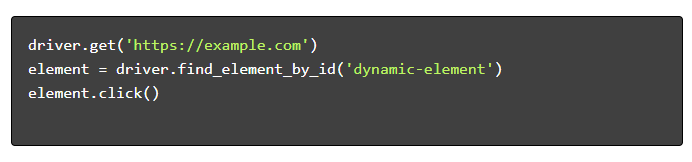
- Nawiguj i wchodź w interakcję :
Najlepsze praktyki dotyczące skrobania sieci
Zaleca się przestrzeganie najlepszych praktyk skrobania sieci, aby zapewnić wydajność i legalność. Poniżej znajdują się najważniejsze wytyczne i strategie obsługi błędów:
- Szanuj plik robots.txt : zawsze sprawdzaj plik robots.txt witryny docelowej.
- Ograniczanie : Implementuj opóźnienia, aby zapobiec przeciążeniu serwera.
- User-Agent : użyj niestandardowego ciągu User-Agent, aby uniknąć potencjalnych blokad.
- Logika ponawiania : użyj bloków try-except i skonfiguruj logikę ponawiania w celu obsługi przekroczeń limitu czasu serwera.
- Rejestrowanie : prowadź kompleksowe dzienniki do debugowania.
- Obsługa wyjątków : w szczególności wyłapuje błędy sieciowe, błędy HTTP i błędy analizy.
- Wykrywanie Captcha : uwzględnij strategie wykrywania i rozwiązywania lub omijania CAPTCHA.
Typowe wyzwania związane z dynamicznym skrobaniem sieci
Captchy
Wiele witryn internetowych używa kodów CAPTCHA, aby zapobiec automatycznym botom. Aby to ominąć:
- Skorzystaj z usług rozwiązywania problemów CAPTCHA, takich jak 2Captcha.
- Wdrożenie interwencji człowieka w celu rozwiązania CAPTCHA.
- Użyj serwerów proxy, aby ograniczyć liczbę żądań.
Blokowanie IP
Witryny mogą blokować adresy IP wysyłające zbyt wiele żądań. Przeciwdziałaj temu poprzez:
- Korzystanie z rotacyjnych serwerów proxy.
- Implementacja ograniczania żądań.
- Stosowanie strategii rotacji agentów użytkownika.
Renderowanie JavaScript
Niektóre witryny ładują treść za pomocą JavaScript. Podejmij to wyzwanie poprzez:
- Używanie Selenium lub Puppeteer do automatyzacji przeglądarki.
- Wykorzystanie Scrapy-splash do renderowania treści dynamicznych.
- Eksploracja przeglądarek bezgłowych pod kątem interakcji z JavaScriptem.
Zagadnienia prawne
Skrobanie sieci może czasami naruszać warunki korzystania z usługi. Zapewnij zgodność poprzez:
- Konsultacje prawne.
- Skrobanie publicznie dostępnych danych.
- Przestrzeganie dyrektyw pliku robots.txt.
Analiza danych
Obsługa niespójnych struktur danych może być wyzwaniem. Rozwiązania obejmują:
- Używanie bibliotek takich jak BeautifulSoup do analizowania HTML.
- Stosowanie wyrażeń regularnych do wyodrębniania tekstu.
- Wykorzystanie parserów JSON i XML do danych strukturalnych.
Przechowywanie i analizowanie usuniętych danych
Przechowywanie i analizowanie zeskrobanych danych to kluczowe etapy skrobania sieci. Decyzja o miejscu przechowywania danych zależy od ich objętości i formatu. Typowe opcje przechowywania obejmują:
- Pliki CSV : łatwe w przypadku małych zbiorów danych i prostych analiz.
- Bazy danych : bazy danych SQL dla danych strukturalnych; NoSQL dla niestrukturalnych.
Po zapisaniu analizę danych można przeprowadzić przy użyciu bibliotek Pythona:
- Pandy : Idealne do manipulacji i czyszczenia danych.
- NumPy : Wydajny w przypadku operacji numerycznych.
- Matplotlib i Seaborn : Odpowiednie do wizualizacji danych.
- Scikit-learn : Zapewnia narzędzia do uczenia maszynowego.
Właściwe przechowywanie i analiza danych poprawiają ich dostępność i wiedzę.
Wnioski i dalsze kroki
Po przejściu przez Pythona z dynamicznym przeglądaniem stron internetowych konieczne jest dopracowanie zrozumienia wyróżnionych narzędzi i bibliotek.
- Przejrzyj kod : zapoznaj się z ostatecznym skryptem i zmodularyzuj, jeśli to możliwe, aby zwiększyć możliwość ponownego użycia.
- Dodatkowe biblioteki : Przeglądaj zaawansowane biblioteki, takie jak Scrapy lub Splash, w przypadku bardziej złożonych potrzeb.
- Przechowywanie danych : rozważ solidne opcje przechowywania — bazy danych SQL lub pamięć w chmurze do zarządzania dużymi zbiorami danych.
- Względy prawne i etyczne : Bądź na bieżąco z wytycznymi prawnymi dotyczącymi skrobania stron internetowych, aby uniknąć potencjalnych naruszeń.
- Następne projekty : Radzenie sobie z nowymi projektami web scrapingu o różnym stopniu złożoności jeszcze bardziej ugruntuje te umiejętności.
Chcesz zintegrować profesjonalne, dynamiczne skrobanie sieci z Pythonem w swoim projekcie? Dla zespołów, które wymagają ekstrakcji danych na dużą skalę bez konieczności skomplikowanej obsługi ich wewnętrznie, PromptCloud oferuje rozwiązania dostosowane do indywidualnych potrzeb. Poznaj usługi PromptCloud, aby znaleźć solidne i niezawodne rozwiązanie. Skontaktuj się z nami już dziś!