
Głos Bazaru
Opublikowany: 2024-04-24Ten artykuł na temat modernizacji starszych systemów jest uzupełnieniem wykładu, który niedawno przedstawiłem na szczycie AWS Data Summit dla firm zajmujących się oprogramowaniem, na temat generowania wartości z danych poprzez wykorzystanie naszych najlepszych praktyk w celu zapewnienia sukcesu w projektach uczenia maszynowego. Jeśli wolisz, możesz zeskoczyć na sam dół i obejrzeć film.
Spójrzmy prawdzie w oczy: oprogramowanie jest łatwiejsze do napisania niż utrzymywania. Właśnie dlatego my, jako inżynierowie oprogramowania, wolimy po prostu „wyrwać to i zacząć od nowa”, zamiast próbować zrozumieć, co myślał inny programista (lub nasze dawne ja). Wydaje się, że wspólnie zapomnieliśmy, że „programy muszą być pisane tak, aby ludzie mogli je czytać, a tylko incydentalnie, aby maszyny mogły je wykonywać”.
Wiesz, że to prawda — wszyscy musieliśmy skrupulatnie przekopywać się przez zapiekankę z kodem spaghetti i cienkimi abstrakcjami w starym stylu, szukając treści programu, ale na dnie talerzy znaleźliśmy jedynie bałagan.
Łatwo jest krzyknąć „WTF” i zwalić winę na poprzedniego twórcę, ale prawda jest często bardziej skomplikowana. Nie widzimy przyszłości, więc nie da się zrozumieć, w jaki sposób wymagania, technologia lub cele biznesowe wzrosną, gdy zaprojektujemy nowy system. W rezultacie systemy mogą stać się nieczytelne w miarę zwiększania się ich zakresu wraz ze wzrostem zależności przedsiębiorstwa od nich. To trochę paradoks: starsze, trudniejsze w utrzymaniu systemy często zapewniają największą wartość. Trudno nad nimi pracować, bo dorastają wraz z firmą, i strasznie się nad nimi pracuje, bo złamanie ich może oznaczać katastrofę.
Oto, do czego cię wzywam: jeśli lubisz trudne, satysfakcjonujące problemy… spróbuj. Weź najstarszy system, jaki posiadasz i spraw, aby był łatwy w utrzymaniu. Znacie tego, o którym mówię – tego, którego nikt nie będzie „posiadał”. Ten, na którym opierają się inne działy, a którego inżynierowie nienawidzą. Ten, na którym musiałeś najpierw załatać Log4Shell. Zrób to. Wyzywam cię.
Niedawno miałem taką okazję zaktualizować dziesięcioletni system uczenia maszynowego w Bazaarvoice. Na pozór nie brzmiało to ekscytująco : to coś nie miało nawet sieci neuronowych! Kogo to obchodzi! Cóż… to miało znaczenie. System ten przetwarza niemal każdą recenzję produktu wygenerowaną przez użytkowników otrzymaną przez Bazaarvoice – prawie 9 milionów miesięcznie – i robi to za pomocą 90 milionów wywołań wnioskowania do modeli uczenia maszynowego. Tak – 90 milionów wniosków! To ogromna skala i nie mogłem się doczekać, aż w nią zanurkuję.
W tym poście opowiem, jak modernizacja tego starszego systemu poprzez zmianę architektury, a nie przepisywanie, pozwoliła nam uczynić go skalowalnym i opłacalnym bez konieczności wyrywania całego kodu i zaczynania od nowa. Powstały system jest bezserwerowy, kontenerowy i łatwy w utrzymaniu, a jednocześnie zmniejsza koszty hostingu o prawie 80%.
Co to jest starszy system?
Starszy system odnosi się do starzejącego się oprogramowania i/lub sprzętu komputerowego, który nadal działa. Chociaż może nadal spełniać swój pierwotny cel, brakuje mu skalowalności dla przyszłego rozwoju.
Stare, starsze systemy
Najpierw przyjrzyjmy się, z czym mamy tu do czynienia. Starszy system, który mój zespół aktualizował, moderuje treści generowane przez użytkowników dla całego Bazaarvoice. W szczególności określa, czy dana treść jest odpowiednia dla witryn internetowych naszych klientów.

Brzmi to prosto – należy wyeliminować oczywiste naruszenia, takie jak mowa nienawiści, wulgarny język lub nagabywanie – ale w praktyce jest to znacznie bardziej zróżnicowane. Każdy klient ma unikalne wymagania dotyczące tego, co uważa za odpowiednie. Na przykład marki piwa oczekiwałyby dyskusji na temat alkoholu, ale marki dla dzieci nie. Przechwytujemy te specyficzne dla klienta opcje podczas wdrażania nowych klientów, a nasz zespół obsługi klienta koduje je w zarządzającej bazie danych.
Aby zwiększyć złożoność, pobieramy również próbkę podzbioru naszych treści, która ma być moderowana przez moderatorów. Dzięki temu możemy stale mierzyć wydajność naszych modeli i odkrywać możliwości budowania większej liczby modeli.
Poniżej przedstawiono pełną architekturę naszego starszego systemu:
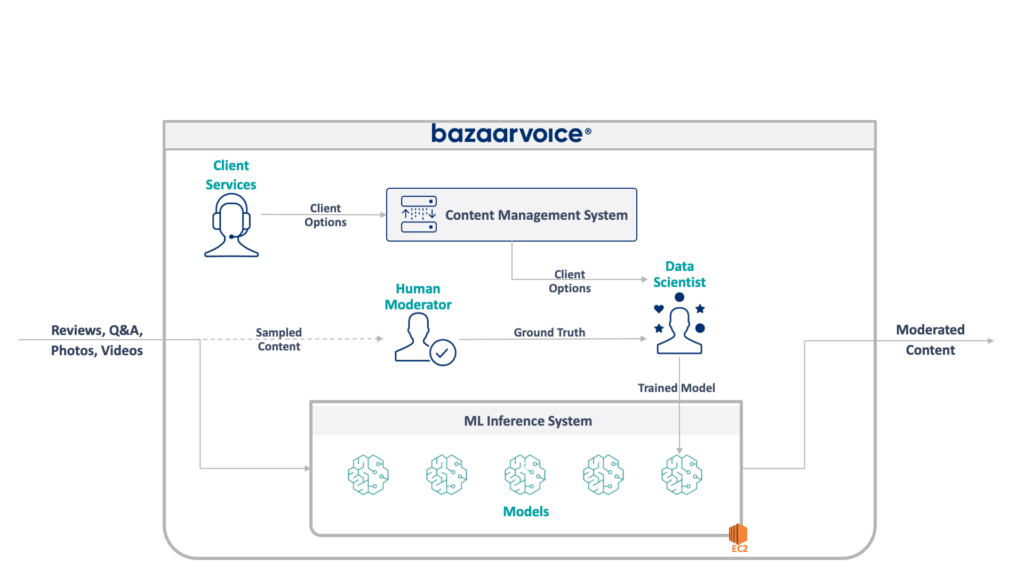
System ten ma kilka poważnych wad. W szczególności — wszystkie modele są hostowane w jednej instancji EC2. Nie wynikało to ze złej inżynierii – po prostu z niezdolności pierwotnych programistów do przewidzenia skali pożądanej przez firmę. Nikt nie przypuszczał, że urosnie aż tak bardzo.
Dodatkowo system spotkał się z odmową ze strony deweloperów: został napisany w języku Scala, który rozumiało niewielu inżynierów. Dlatego często pomijano go w celu poprawy, ponieważ nikt nie chciał go dotykać.
W rezultacie system nadal rozwijał się w sposób ciągły. Kiedy już zabraliśmy się za jego przeprojektowanie, działał on na pojedynczej instancji x1e.8xlarge. To urządzenie miało prawie terabajt pamięci RAM i kosztuje około 5000 dolarów miesięcznie (bez rezerwacji). Nie martw się jednak, właśnie uruchomiliśmy drugi dla redundancji i trzeci dla kontroli jakości.
System ten był kosztowny w utrzymaniu i obarczony wysokim ryzykiem awarii (jeden zły model może uniemożliwić całą usługę). Co więcej, baza kodu nie była aktywnie rozwijana, przez co była znacznie przestarzała w stosunku do nowoczesnych pakietów do nauki o danych i nie była zgodna z naszymi standardowymi praktykami dotyczącymi usług napisanych w języku Scala.
Nowy system
Przeprojektowując ten system, mieliśmy jasny cel: uczynić go skalowalnym. Obniżenie kosztów operacyjnych było celem drugorzędnym, podobnie jak ułatwienie zarządzania modelami i kodami.
Nowy projekt, który opracowaliśmy, pokazano poniżej:

Nasze podejście do rozwiązania tego problemu polegało na umieszczeniu każdego modelu uczenia maszynowego na izolowanym punkcie końcowym SageMaker Serverless. Podobnie jak funkcje AWS Lambda, bezserwerowe punkty końcowe wyłączają się, gdy nie są używane — oszczędzając nam koszty czasu działania w przypadku rzadko używanych modeli. Można je także szybko skalować w odpowiedzi na wzrost ruchu.

Ponadto udostępniliśmy opcje klienta pojedynczej mikrousługie, która kieruje zawartość do odpowiednich modeli. To była większość nowego kodu, który musieliśmy napisać: mały interfejs API, który był łatwy w utrzymaniu i pozwalał naszym analitykom danych na łatwiejsze aktualizowanie i wdrażanie nowych modeli.
To podejście ma następujące zalety:
- Zmniejszono czas osiągnięcia wartości o ponad 6 razy. W szczególności kierowanie ruchu do istniejących modeli jest natychmiastowe, a wdrażanie nowych modeli można wykonać w mniej niż 5 minut zamiast 30
- Skaluj bez ograniczeń – obecnie mamy 400 modeli, ale planujemy skalować do tysięcy, aby w dalszym ciągu zwiększać ilość treści, które możemy automatycznie moderować
- Zaobserwowaliśmy redukcję kosztów o 82% po przejściu na EC2, ponieważ funkcje wyłączają się, gdy nie są używane, a my nie płacimy za maszyny najwyższej klasy, które są w niewystarczającym stopniu wykorzystywane
Jednak samo zaprojektowanie idealnej architektury nie jest naprawdę interesującą i trudną częścią przebudowy starszego systemu — trzeba do niej przeprowadzić migrację .
Naszym pierwszym wyzwaniem podczas migracji było ustalenie, jak do cholery przeprowadzić migrację modelu Java WEKA w celu uruchomienia go w programie SageMaker, nie mówiąc już o SageMaker Serverless.
Na szczęście SageMaker wdraża modele w kontenerach Dockera, więc przynajmniej mogliśmy zamrozić wersję Java i wersje zależności, aby pasowały do naszego starego kodu. Pomogłoby to zapewnić, że modele hostowane w nowym systemie zwracają takie same wyniki, jak w starszym systemie.

Aby kontener był kompatybilny z SageMakerem, wystarczy zaimplementować kilka konkretnych punktów końcowych HTTP:
-
POST /invocation— akceptuje dane wejściowe, wykonuje wnioskowanie i zwraca wyniki. -
GET /ping— zwraca 200, jeśli serwer JVM jest w dobrej kondycji
(Zdecydowaliśmy się zignorować całe zamieszanie wokół wielomodelowych kontenerów BYO i zestawu narzędzi wnioskowania SageMaker.)
Kilka szybkich abstrakcji wokół com.sun.net.httpserver.HttpServer i byliśmy gotowi do pracy.
I wiesz co? To było naprawdę całkiem zabawne. Zabawa z kontenerami Docker i wpychanie czegoś, co miało 10 lat do SageMaker Serverless, miało klimat majsterkowania. Kiedy udało nam się to uruchomić, było całkiem ekscytująco — zwłaszcza, gdy otrzymaliśmy starszy kod systemowy do zbudowania go w naszym nowym stosie sbt zamiast w maven.
Nowy stos sbt ułatwił pracę, a konteneryzacja zapewniła prawidłowe zachowanie podczas pracy w środowisku SageMaker.
Migracja do nowego systemu
Mamy więc modele w kontenerach i możemy wdrożyć je w SageMaker — prawie gotowe, prawda? Nie do końca.
Trudna lekcja dotycząca migracji na nową architekturę jest taka, że aby obsłużyć migrację, należy zbudować trzykrotnie większy system niż rzeczywisty. Oprócz nowego systemu musieliśmy zbudować:
- Potok przechwytywania danych w starym systemie do rejestrowania danych wejściowych i wyjściowych z modelu. Wykorzystaliśmy je, aby potwierdzić, że nowy system zwróci te same wyniki
- Potok przetwarzania danych w nowym systemie umożliwiający obliczanie wyników i porównywanie ich z danymi ze starego systemu. Wymagało to dużej liczby pomiarów za pomocą Datadog i wymagało zapewnienia możliwości odtwarzania danych w przypadku wykrycia rozbieżności
- System wdrażania pełnego modelu, aby uniknąć wpływu na użytkowników starego systemu (który po prostu przesyłałby modele do S3). Wiedzieliśmy, że chcemy ostatecznie przenieść je do interfejsu API, ale w przypadku pierwszej wersji musieliśmy to zrobić bezproblemowo
Wszystko to był kod do wyrzucenia i wiedzieliśmy, że możemy go wyrzucić po zakończeniu migracji wszystkich użytkowników, ale nadal musieliśmy go zbudować i upewnić się, że dane wyjściowe nowego systemu odpowiadają staremu.
Spodziewaj się tego z góry.
Choć budowanie narzędzi i systemów do migracji z pewnością zajęło nam ponad 60% czasu inżynieryjnego w tym projekcie, było to także ciekawe doświadczenie. Testy jednostkowe bardziej przypominają eksperymenty związane z nauką o danych: napisaliśmy całe zestawy, aby mieć pewność, że wyniki dokładnie odpowiadają testom. To był inny sposób myślenia, który sprawił, że praca była o wiele przyjemniejsza. Jeśli wolisz, wyjdź poza nasze normalne pudełka.
Modernizacja starszych systemów poprzez zmianę architektury
Następnym razem, gdy poczujesz pokusę przebudowania systemu od kodu w górę, zachęcam Cię do wypróbowania migracji architektury zamiast kodu. Znajdziesz interesujące i satysfakcjonujące wyzwania techniczne, które prawdopodobnie sprawią ci dużo większą przyjemność niż debugowanie nieoczekiwanych przypadków brzegowych nowego kodu.
Chcesz dowiedzieć się więcej? Obejrzyj poniżej wykład, który wygłosiłem na szczycie AWS Data Summit, który omawia aspekty MLOps.