
Jak działa przeszukiwacz sieci
Opublikowany: 2023-12-05Roboty indeksujące odgrywają istotną funkcję w indeksowaniu i porządkowaniu obszernych informacji znajdujących się w Internecie. Ich rola polega na przeglądaniu stron internetowych, gromadzeniu danych i udostępnianiu ich do przeszukiwania. W tym artykule szczegółowo opisano mechanikę robota sieciowego, dostarczając wglądu w jego komponenty, operacje i różnorodne kategorie. Zagłębmy się w świat robotów sieciowych!
Co to jest przeszukiwacz sieci
Robot sieciowy, zwany pająkiem lub botem, to zautomatyzowany skrypt lub program przeznaczony do metodycznego poruszania się po stronach internetowych. Zaczyna się od początkowego adresu URL, a następnie podąża za linkami HTML, aby odwiedzić inne strony internetowe, tworząc sieć wzajemnie połączonych stron, które można indeksować i analizować.
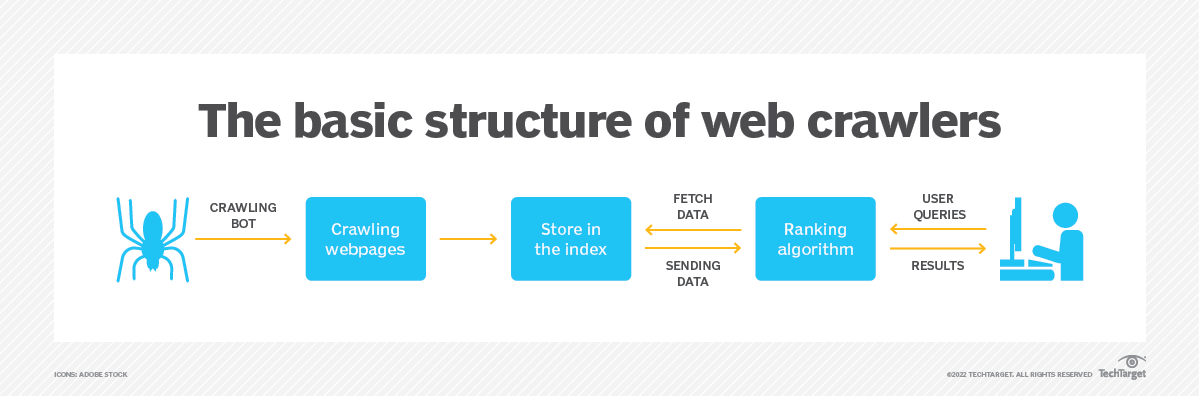
Źródło obrazu: https://www.techtarget.com/
Cel przeszukiwacza sieci
Głównym celem robota sieciowego jest zbieranie informacji ze stron internetowych i generowanie indeksu z możliwością przeszukiwania w celu skutecznego wyszukiwania. Główne wyszukiwarki, takie jak Google, Bing i Yahoo, w dużym stopniu polegają na robotach indeksujących przy tworzeniu swoich baz danych wyszukiwania. Dzięki systematycznemu badaniu treści internetowych wyszukiwarki mogą dostarczać użytkownikom trafne i aktualne wyniki wyszukiwania.
Należy zauważyć, że zastosowanie robotów indeksujących wykracza poza wyszukiwarki. Są również wykorzystywane przez różne organizacje do zadań takich jak eksploracja danych, agregacja treści, monitorowanie stron internetowych, a nawet cyberbezpieczeństwo.
Składniki robota sieciowego
Robot sieciowy składa się z kilku komponentów współpracujących ze sobą, aby osiągnąć swoje cele. Oto kluczowe elementy robota sieciowego:
- Granica adresów URL: ten komponent zarządza kolekcją adresów URL oczekujących na przeszukanie. Nadaje priorytet adresom URL na podstawie czynników takich jak trafność, aktualność lub znaczenie witryny.
- Narzędzie do pobierania: Narzędzie do pobierania pobiera strony internetowe na podstawie adresów URL dostarczonych przez granicę adresu URL. Wysyła żądania HTTP do serwerów internetowych, odbiera odpowiedzi i zapisuje pobraną treść internetową do dalszego przetwarzania.
- Parser: Parser przetwarza pobrane strony internetowe, wyodrębniając przydatne informacje, takie jak linki, tekst, obrazy i metadane. Analizuje strukturę strony i wyodrębnia adresy URL stron, do których prowadzą linki, które mają zostać dodane do granicy adresów URL.
- Przechowywanie danych: Komponent przechowywania danych przechowuje zebrane dane, w tym strony internetowe, wyodrębnione informacje i dane indeksowane. Dane te mogą być przechowywane w różnych formatach, takich jak baza danych lub rozproszony system plików.
Jak działa przeszukiwacz sieci
Po zapoznaniu się z zaangażowanymi elementami przyjrzyjmy się sekwencyjnej procedurze wyjaśniającej działanie robota sieciowego:
- Adres URL początkowy: robot indeksujący zaczyna od adresu URL początkowego, którym może być dowolna strona internetowa lub lista adresów URL. Ten adres URL jest dodawany do granicy adresu URL w celu zainicjowania procesu indeksowania.
- Pobieranie: Robot indeksujący wybiera adres URL z granicy adresu URL i wysyła żądanie HTTP do odpowiedniego serwera internetowego. Serwer odpowiada treścią strony internetowej, która jest następnie pobierana przez moduł downloadera.
- Parsowanie: analizator przetwarza pobraną stronę internetową, wyodrębniając istotne informacje, takie jak łącza, tekst i metadane. Identyfikuje także i dodaje nowe adresy URL znalezione na stronie do granicy adresów URL.
- Analiza linków: Robot ustala priorytety i dodaje wyodrębnione adresy URL do granicy adresu URL w oparciu o określone kryteria, takie jak trafność, świeżość lub ważność. Pomaga to określić kolejność, w jakiej robot będzie odwiedzał i indeksował strony.
- Powtórz proces: robot indeksujący kontynuuje proces, wybierając adresy URL z granicy adresów URL, pobierając ich treść internetową, analizując strony i wyodrębniając więcej adresów URL. Proces ten jest powtarzany do momentu, gdy nie będzie już żadnych adresów URL do przeszukania lub zostanie osiągnięty określony limit.
- Przechowywanie danych: W całym procesie indeksowania zebrane dane są przechowywane w komponencie przechowywania danych. Dane te można później wykorzystać do indeksowania, analizy lub do innych celów.
Rodzaje robotów sieciowych
Roboty indeksujące występują w różnych odmianach i mają określone zastosowania. Oto kilka powszechnie używanych typów robotów indeksujących:

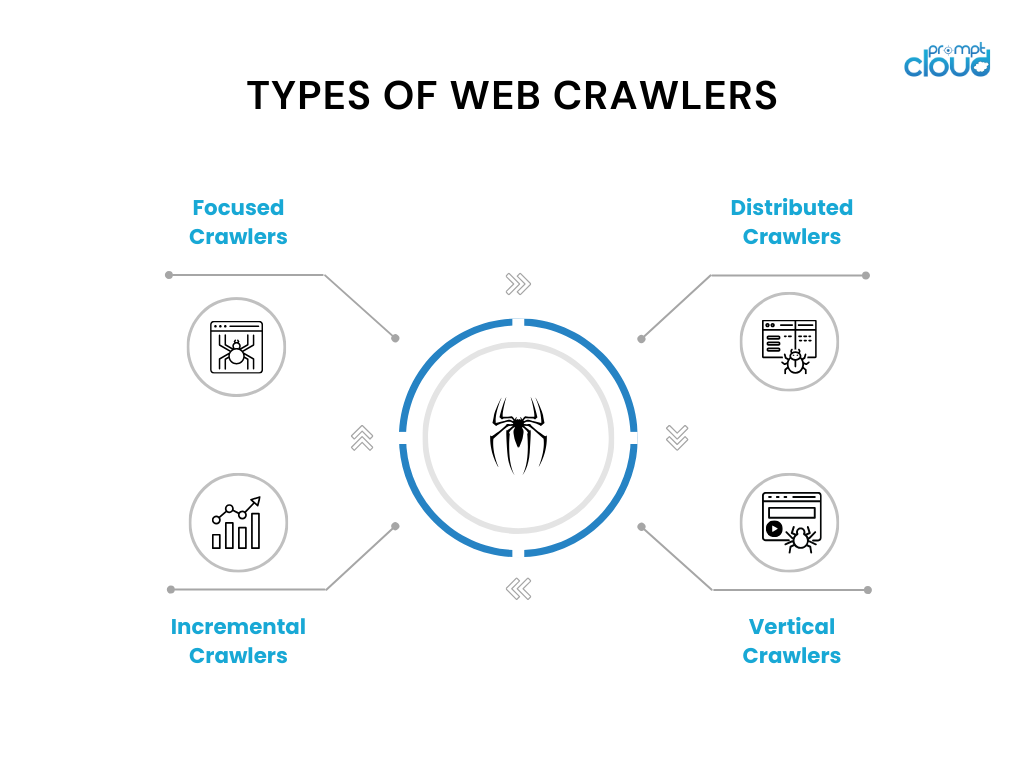
- Roboty ukierunkowane: roboty te działają w obrębie określonej domeny lub tematu i przeszukują strony powiązane z tą domeną. Przykładami mogą być roboty tematyczne wykorzystywane w witrynach z wiadomościami lub artykułach naukowych.
- Roboty przyrostowe: Roboty przyrostowe koncentrują się na przeszukiwaniu nowej lub zaktualizowanej zawartości od czasu ostatniego przeszukiwania. Wykorzystują techniki takie jak analiza znaczników czasu lub algorytmy wykrywania zmian w celu identyfikowania i indeksowania zmodyfikowanych stron.
- Roboty rozproszone: w robotach rozproszonych wiele instancji robota działa równolegle, dzieląc się pracą związaną z przeszukiwaniem ogromnej liczby stron. Takie podejście umożliwia szybsze indeksowanie i lepszą skalowalność.
- Roboty indeksujące: Roboty pionowe celują w określone typy treści lub danych na stronach internetowych, takie jak obrazy, filmy lub informacje o produktach. Mają na celu wyodrębnianie i indeksowanie określonych typów danych dla wyspecjalizowanych wyszukiwarek.
Jak często należy indeksować strony internetowe?
Częstotliwość indeksowania stron internetowych zależy od kilku czynników, w tym od rozmiaru i częstotliwości aktualizacji witryny, znaczenia stron i dostępnych zasobów. Niektóre witryny internetowe mogą wymagać częstego przeszukiwania, aby zapewnić zaindeksowanie najnowszych informacji, inne natomiast mogą być przeszukiwane rzadziej.
W przypadku witryn internetowych o dużym natężeniu ruchu lub zawierających szybko zmieniającą się treść częstsze indeksowanie jest niezbędne, aby zachować aktualne informacje. Z drugiej strony mniejsze witryny lub strony z rzadkimi aktualizacjami mogą być indeksowane rzadziej, co zmniejsza obciążenie pracą i wymagane zasoby.
Własny przeszukiwacz sieci a narzędzia do przeszukiwania sieci
Rozważając utworzenie robota sieciowego, kluczowa jest ocena jego złożoności, skalowalności i niezbędnych zasobów. Skonstruowanie robota od podstaw może być przedsięwzięciem czasochłonnym i obejmującym takie działania, jak zarządzanie współbieżnością, nadzorowanie systemów rozproszonych i usuwanie przeszkód w infrastrukturze. Z drugiej strony, wybór narzędzi lub struktur do przeszukiwania sieci może zapewnić szybsze i skuteczniejsze rozwiązanie.
Alternatywnie, szybsze i bardziej wydajne rozwiązanie może zapewnić użycie narzędzi lub struktur do przeszukiwania sieci. Narzędzia te oferują takie funkcje, jak konfigurowalne reguły indeksowania, możliwości wyodrębniania danych i opcje przechowywania danych. Wykorzystując istniejące narzędzia, programiści mogą skoncentrować się na swoich specyficznych wymaganiach, takich jak analiza danych lub integracja z innymi systemami.
Należy jednak wziąć pod uwagę ograniczenia i koszty związane z korzystaniem z narzędzi innych firm, takie jak ograniczenia dotyczące dostosowywania, własności danych i potencjalnych modeli cenowych.
Wniosek
Wyszukiwarki w dużym stopniu opierają się na robotach indeksujących, które odgrywają zasadniczą rolę w porządkowaniu i katalogowaniu obszernych informacji znajdujących się w Internecie. Zrozumienie mechaniki, komponentów i różnorodnych kategorii robotów indeksujących umożliwia głębsze zrozumienie skomplikowanej technologii leżącej u podstaw tego podstawowego procesu.
Niezależnie od tego, czy zdecydujesz się zbudować robota sieciowego od podstaw, czy też wykorzystać istniejące narzędzia do przeszukiwania sieci, konieczne staje się przyjęcie podejścia dostosowanego do Twoich konkretnych potrzeb. Wymaga to uwzględnienia takich czynników, jak skalowalność, złożoność i zasoby, którymi dysponujesz. Biorąc te elementy pod uwagę, możesz skutecznie wykorzystywać przeszukiwanie sieci do gromadzenia i analizowania cennych danych, co napędza rozwój Twojej firmy lub przedsięwzięć badawczych .
W PromptCloud specjalizujemy się w ekstrakcji danych internetowych, pozyskując dane z publicznie dostępnych zasobów internetowych. Skontaktuj się z nami pod adresem sales@promptcloud.com