
Jak utworzyć kopię zapasową danych Universal Analytics w BigQuery za pomocą R
Opublikowany: 2023-09-26Usługa Universal Analytics (UA) w końcu dobiegła końca i nasze dane przepływają teraz swobodnie do naszych usług Google Analytics 4 (GA4). Może kusić, aby nigdy więcej nie patrzeć na nasze konfiguracje UA, jednak zanim opuścimy UA, ważne jest, abyśmy przechowywali dane, które już przetworzył, na wypadek konieczności ich analizy w przyszłości. Do przechowywania danych polecamy oczywiście BigQuery, usługę hurtowni danych Google, a na tym blogu pokażemy Ci, jakie dane należy wykonać w kopii zapasowej z UA i jak to zrobić!
W celu pobrania naszych danych skorzystamy z API Google Analytics. Napiszemy skrypt, który za jednym razem pobierze niezbędne dane z UA i prześle je do BigQuery. Do tego zadania zdecydowanie zalecamy użycie języka R, ponieważ pakiety googleAnalyticsR i bigQueryR bardzo ułatwiają to zadanie i dlatego napisaliśmy nasz tutorial dla R!
W tym przewodniku nie opisano bardziej złożonych kroków konfiguracji uwierzytelniania, takich jak pobieranie pliku danych uwierzytelniających. Informacje na ten temat oraz więcej informacji o przesyłaniu danych do BigQuery znajdziesz na naszym blogu na temat przesyłania danych do BigQuery z R i Pythona!
Tworzenie kopii zapasowych danych UA za pomocą R
Jak zwykle w przypadku każdego skryptu R, pierwszym krokiem jest załadowanie naszych bibliotek. Do tego skryptu będziemy potrzebować:
biblioteka (googleAuthR)
biblioteka (googleAnalyticsR)
biblioteka (bigQueryR)
Jeśli nie korzystałeś wcześniej z tych bibliotek, uruchom install.packages(<NAZWA PAKIETU>) w konsoli, aby je zainstalować.
Następnie będziemy musieli uporządkować wszystkie nasze różne autoryzacje. Aby to zrobić, uruchom następujący kod i postępuj zgodnie z otrzymanymi instrukcjami:
googleAuthR::gar_cache_empty()
googleAuthR::gar_set_client(“C:\\Users\\Tom Brown\\Documents\\R\\APIs\\credentials.json”)
bqr_auth(email = „<Twój e-mail tutaj>”)
ga_id <- <TUTAJ TWÓJ IDENTYFIKATOR GA WIDOK>
Ga_id można znaleźć pod nazwą widoku po wybraniu go w UA, jak pokazano poniżej:
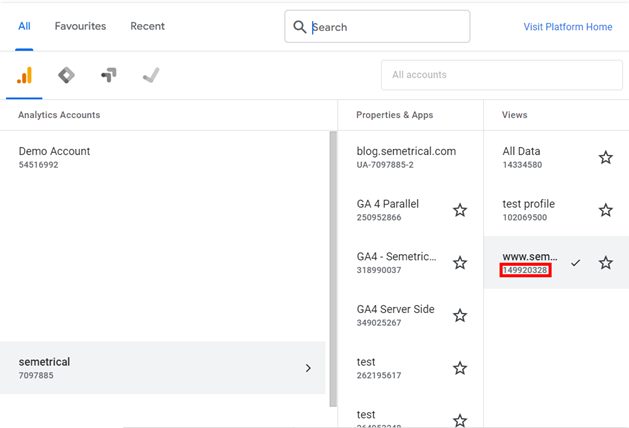
Następnie musimy zdecydować, jakie dane faktycznie pobrać z UA. Zalecamy pociągnięcie następujących elementów:
| Wymiary ograniczone do sesji | Wymiary ograniczone do zdarzenia | Wymiary ograniczone do odsłon |
| Identyfikator klienta | Identyfikator klienta | Ścieżka strony |
| Znak czasu | Znak czasu | Znak czasu |
| Źródło/medium | Kategoria wydarzenia | Źródło/medium |
| Kategoria urządzenia | Akcja Wydarzenia | Kategoria urządzenia |
| Kampania | Etykieta wydarzenia | Kampania |
| Grupowanie kanałów | Źródło/medium | Grupowanie kanałów |
| Kampania |
Umieszczenie ich w trzech tabelach w BigQuery powinno wystarczyć do zaspokojenia wszystkich potencjalnych przyszłych potrzeb związanych z danymi UA. Aby pobrać te dane z UA, musisz najpierw określić zakres dat. Wejdź na platformę UA i przejrzyj jeden ze swoich raportów, aby zobaczyć, kiedy po raz pierwszy rozpoczęło się gromadzenie danych. Następnie określ zakres dat obejmujący ten moment aż do dnia poprzedzającego uruchomienie skryptu, czyli ostatniego dnia, dla którego będziesz mieć dane z pełnych 24 godzin (a jeśli robisz to po wyłączeniu UA zachód słońca i tak uwzględni 100% dostępnych danych). Gromadzenie danych rozpoczęliśmy w maju 2017 r., dlatego napisałem:

daty <- c(„2017-05-01”, Sys.Date()-1)
Teraz musimy określić, co należy pobrać z UA zgodnie z powyższą tabelą. W tym celu będziemy musieli trzykrotnie uruchomić metodę google_analytics(), ponieważ nie można jednocześnie wysyłać zapytań o wymiary różnych zakresów. Możesz dokładnie skopiować następujący kod:
sessionpull <- google_analytics(ga_id,
zakres_dat = daty,
metryki = c(„sesje”),
wymiary = c(“clientId”, “dateHourMinute”,
„sourceMedium”, „deviceCategory”, „campaign”, „channelGrouping”),
anty_próbka = PRAWDA)
eventpull <- google_analytics(ga_id,
zakres_dat = daty,
metryka = c(„totalEvents”, „eventValue”),
wymiary = c(„clientId”, „dateHourMinute”, „eventCategory”, „eventAction”, „eventLabel”, „sourceMedium”, „campaign”),
anty_próbka = PRAWDA)
pvpull <- google_analytics(ga_id,
zakres_dat = daty,
metryki = c(„odsłony”),
wymiary = c(„pagePath”, „dateHourMinute”, „sourceMedium”, „deviceCategory”, „campaign”, „channelGrouping”),
anty_próbka = PRAWDA)
Powinno to starannie umieścić wszystkie dane w trzech ramkach danych zatytułowanych sessionpull dla wymiarów o zasięgu sesji, eventpull dla wymiarów o zasięgu zdarzenia i pvpull dla wymiarów o zakresie odsłon.
Musimy teraz przesłać dane do BigQuery, którego kod powinien wyglądać mniej więcej tak, powtórzony trzykrotnie dla każdej ramki danych:
bqr_upload_data(“<Twój projekt>”, „<Twój zbiór danych>”, „<Twoja tabela>”, <Twoja ramka danych>)
W moim przypadku oznacza to, że mój kod brzmi:
bqr_upload_data(“mój-projekt”, “test2”, “bloguploadRSess”, sessionpull)
bqr_upload_data(“mój-projekt”, “test2”, “bloguploadREvent”, eventpull)
bqr_upload_data(“mój-projekt”, “test2”, “bloguploadRpv”, pvpull)
Kiedy już to wszystko zostanie napisane, możesz ustawić skrypt tak, aby działał, usiądź wygodnie i zrelaksuj się! Gdy już to zrobisz, będziesz mógł przejść do BigQuery i powinieneś zobaczyć wszystkie swoje dane tam, gdzie teraz powinny!
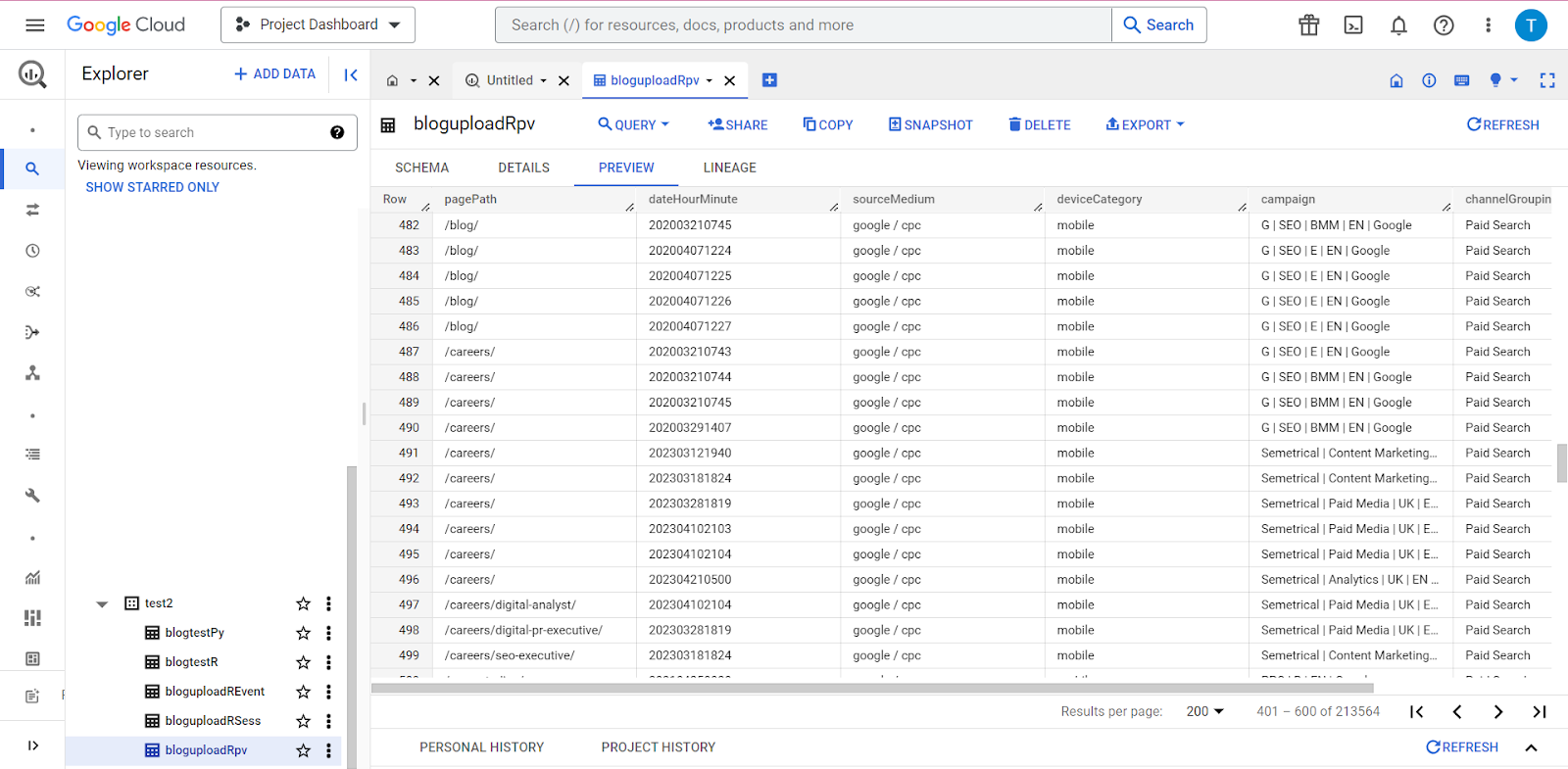
Mając dane UA bezpiecznie schowane na deszczowy dzień, możesz w pełni skupić się na maksymalizacji potencjału konfiguracji GA4 – a Semetrical jest tutaj, aby Ci w tym pomóc! Więcej informacji na temat maksymalnego wykorzystania danych znajdziesz na naszym blogu. Możesz też uzyskać więcej wsparcia we wszystkich kwestiach związanych z analityką, sprawdź nasze usługi analityki internetowej i dowiedz się, jak możemy Ci pomóc.