
Jak zablokować sztuczną inteligencję przed indeksowaniem treści
Opublikowany: 2023-10-24Narzędzia generujące sztuczną inteligencję, takie jak Google Bard i Bing Chat, są zbudowane na podstawie wielu źródeł treści, w tym Internetu. Ku konsternacji wielu wyszukiwarek po cichu trenują swoje modele sztucznej inteligencji na podstawie wszystkich treści znalezionych podczas przeszukiwania tradycyjnej wyszukiwarki internetowej.
Bing i Google ogłosiły teraz metody blokowania wykorzystania treści do szkolenia AI, przy jednoczesnym zachowaniu ich indeksowania na potrzeby wyszukiwania w Internecie.
Czy zatem należy blokować sztuczną inteligencję i jak się do tego zabrać?
- Czy należy blokować sztuczną inteligencję?
- Jak blokować boty AI?
- Jak zablokować sztuczną inteligencję Binga
- Jak zablokować sztuczną inteligencję Google
- Jak zablokować ChatGPT
- Testowanie
Czy należy blokować sztuczną inteligencję?
Firmy tworzące własne produkty mogą uznać za korzyść włączenie swoich treści do modeli sztucznej inteligencji. Informacje, takie jak specyfikacje techniczne lub wsparcie produktu, mogą pomóc w sprzedaży i obniżeniu kosztów obsługi klienta.
Ale dla wielu innych firm internetowych treść jest ich produktem. Istnieją uzasadnione obawy, że energia włożona w tworzenie treści zostanie wykorzystana do ulepszenia produktów AI będących własnością dużych firm technologicznych, nie przynosząc żadnej wartości w postaci ruchu.
Google i Bing próbują znaleźć sposoby na uznanie źródeł i wygenerowanie ruchu z witryn odsyłających, ale prawdopodobnie będzie on mniejszy niż w przypadku tradycyjnej wyszukiwarki internetowej i będzie miał raczej charakter transakcyjny niż zapytania informacyjne.
Należy pamiętać, że blokowanie treści pochodzących z tych AI nie będzie miało wpływu na zachowanie indeksowania. Google twierdzi, że „token klienta użytkownika w pliku robots.txt jest używany w celach kontrolnych”. Twoja witryna będzie normalnie indeksowana przez boty w celu zbudowania indeksów wyszukiwania.
A jeśli wyszukiwarki są już zablokowane przed indeksowaniem niektórych stron, nie musisz ich blokować specjalnie dla AI.
Jak blokować boty AI?
Obecnie możliwe jest blokowanie Google, Bing i ChatGPT przy użyciu metod znanych większości SEO, pliku robots.txt i dyrektyw robots na poziomie strony.
Google i ChatGPT wybrały metodę robots.txt, która pozwala określić wzorce adresów URL, a Bing zdecydował się na użycie dyrektyw robots stosowanych do poszczególnych stron.
Plik robots.txt ma tę zaletę, że można go łatwo skonfigurować dla całej witryny w jednym miejscu. Bardzo jasne jest, które adresy URL są blokowane w porównaniu z dyrektywami dotyczącymi robotów na poziomie strony, które należy przetestować, pobierając każdą pojedynczą stronę.
Jak zablokować sztuczną inteligencję Binga
Bing szuka dyrektyw robots nocache lub noarchive, które można dodać do strony jako metatag lub w nagłówku odpowiedzi X-Robots-Tag.
Nocache umożliwi dołączanie stron do odpowiedzi Bing Chat przy użyciu wyłącznie adresów URL, tytułów i fragmentów kodu podczas uczenia modeli sztucznej inteligencji firmy Microsoft.
Noarchive nie zezwala na dołączanie stron do Bing Chat i żadna zawartość nie będzie używana do szkolenia modeli sztucznej inteligencji firmy Microsoft.
Jeśli strona zawiera zarówno Nocache, jak i Noarchive, pierwszeństwo będzie mieć mniej restrykcyjny Nocache.
Token „ robos ” zastosuje dyrektywę do wszystkich robotów. Obejmuje to Google, które zapobiegnie wyświetlaniu strony z linkiem zapisanym w pamięci podręcznej w wynikach wyszukiwania.
<meta name=”roboty” content=”noarchive”>
Możesz użyć bardziej szczegółowych tokenów „ bingbot ” lub „ msnbot ”, aby uniknąć wpływu na inne wyszukiwarki.
<meta name=”bingbot” content=”nocache”>
Jak zablokować sztuczną inteligencję Google
Google zdecydowało się na metodę robots.txt, która umożliwia określenie wzorców adresów URL pasujących do stron, których nie chcesz używać w Bardzie i jego odpowiedniku Vertex API. Obecnie nie ma to zastosowania do środowiska generującego wyszukiwanie (SGE).
Będą zgodne z tokenem klienta użytkownika z rozszerzeniem Google. Wielkość tokena nie ma znaczenia.
Klient użytkownika: Rozszerzony Google
Uniemożliwić: /
Jeśli nie ma bloku reguł specjalnie dla tokena rozszerzonego Google, będzie on zgodny z tokenem wieloznacznym (*).

Agent użytkownika: *
Uniemożliwić: /
Zachowaj ostrożność, jeśli masz określony blok reguł dla Googlebota i oddzielny blok wieloznaczny. Rozszerzenie Google będzie pasować do bloku symboli wieloznacznych, a nie do bloku Googlebota.
Klient użytkownika: Googlebot
Umożliwić: /
Agent użytkownika: *
Uniemożliwić: /
Aby być bardziej precyzyjnym, możesz wyświetlić listę wielu klientów użytkownika przed blokami reguł.
Klient użytkownika: Rozszerzony Google
Klient użytkownika: Googlebot
Umożliwić: /
Agent użytkownika: *
Uniemożliwić: /
Jak zablokować ChatGPT
ChatGPT również zdecydował się na metodę robots.txt.
Chat GPT ma dwa różne tokeny klienta użytkownika, ChatGPT-User do zapytań w imieniu użytkowników ChatGPT i GPTBot, który jest przeszukiwaczem internetowym OpenAI używanym do tworzenia ich modeli.
System rezygnacji traktuje obecnie obydwa programy użytkownika w ten sam sposób, zatem wszelkie zakazy w pliku robots.txt dla jednego agenta będą dotyczyć obu agentów. Może się to zmienić w przyszłości, dlatego zalecamy oddzielne blokowanie ich.
Agent użytkownika: GPTBot
Agent użytkownika: ChatGPT-User
Uniemożliwić: /
Testowanie
Testowanie jest proste, jeśli blokujesz całą witrynę.
Aby sprawdzić, czy Google i ChatGPT są zablokowane, musisz sprawdzić, czy plik robots.txt zawiera regułę zakazującą wszystkiego dla botów, które chcesz zablokować.
Klient użytkownika: Rozszerzony Google
Klient użytkownika: GPTbot
Uniemożliwić: /
Jeśli chcesz zablokować tylko niektóre adresy URL, może to wymagać bardziej złożonego zestawu dyrektyw w pliku robots.txt. Możesz rozważyć przetestowanie kilku adresów URL, które według Ciebie będą blokowane, a które nie.
Tomo to nasze bezpłatne narzędzie do pliku robots.txt, które może pomóc Ci sprawdzić, czy określone adresy URL są blokowane w pliku robots.txt. Możesz zdefiniować testy w formie listy adresów URL i oczekiwanego statusu niedozwolonego dla każdego adresu URL.
Można go skonfigurować za pomocą tokenów agenta użytkownika Google-Extended, GPTBot i ChatGPT-User, aby pokazać, które adresy URL są blokowane dla każdego z nich i czy odpowiada to oczekiwanemu wynikowi testu.
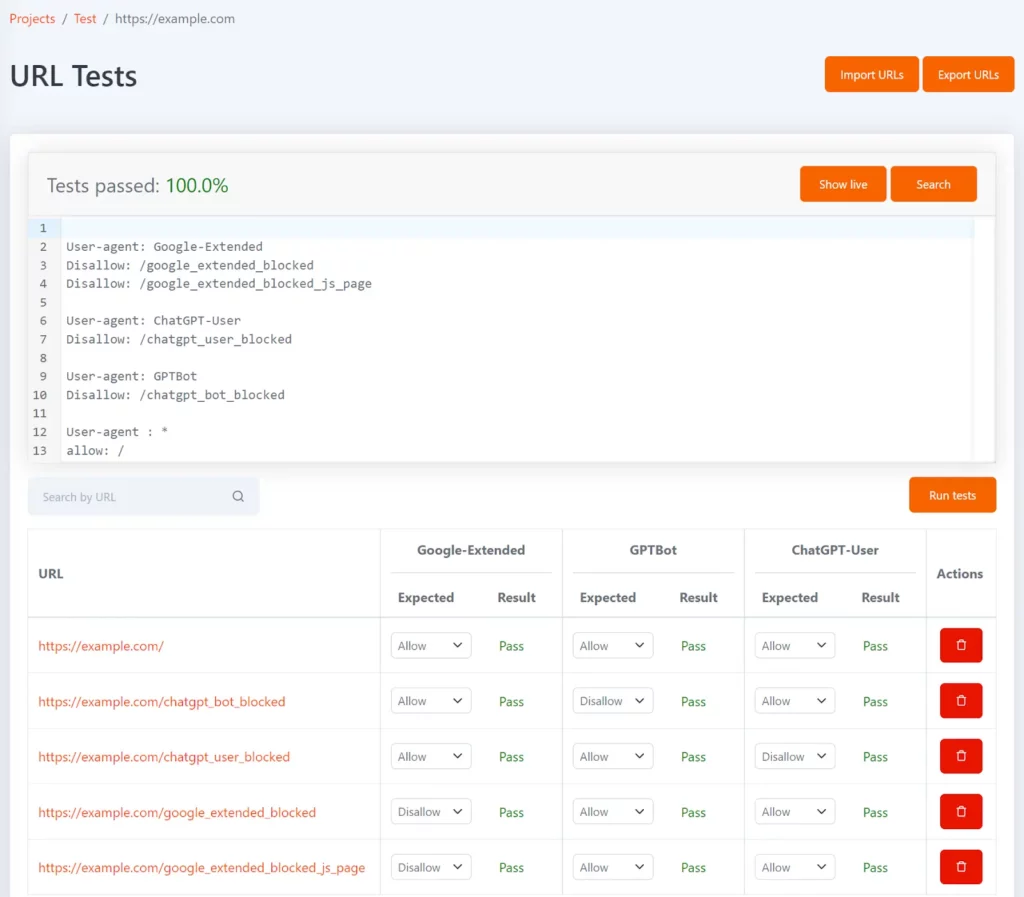
Po każdej aktualizacji pliku robots.txt testy zostaną ponownie uruchomione, a jeśli wyniki nie będą zgodne z oczekiwaniami, otrzymasz powiadomienie.
Aby sprawdzić, czy usługa Bing jest zablokowana, możesz sprawdzić szablony kluczowych stron w przeglądarce i upewnić się, że zawierają one tag robots.
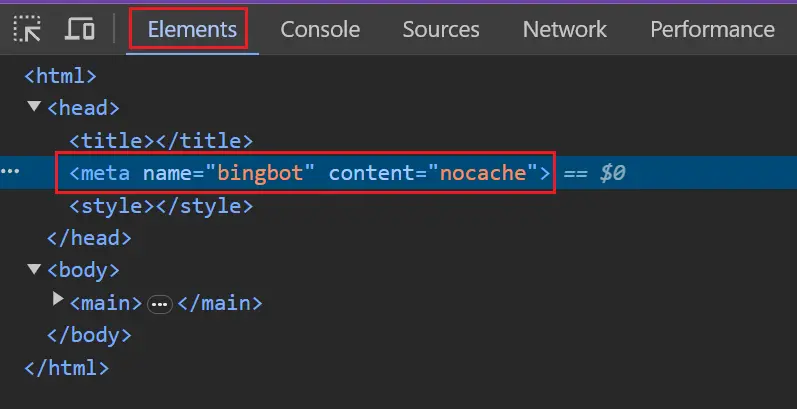
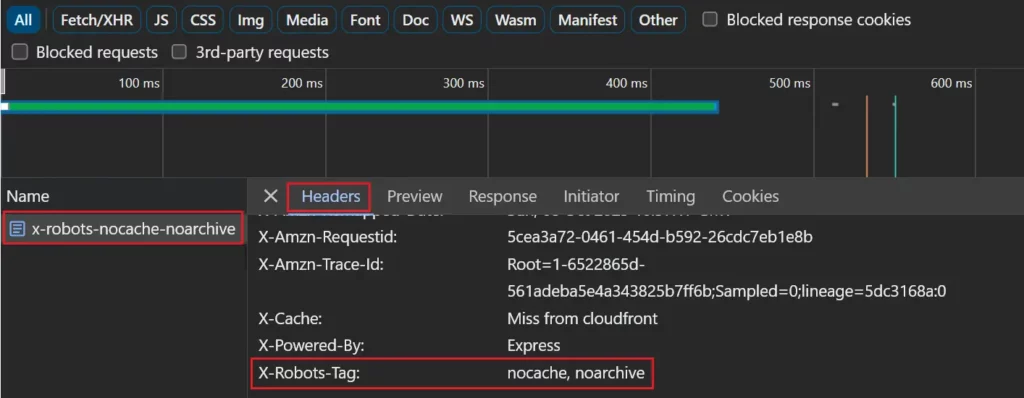
Jeśli używasz nagłówka odpowiedzi X-Robots-Tag, można go zobaczyć w zakładce sieci, wybierając stronę na liście żądań sieciowych i przeglądając zakładkę „Nagłówki”.
Testowanie będzie bardziej skomplikowane, jeśli blokujesz określony zestaw stron, ale istnieje kilka narzędzi, które mogą pomóc.
Robot Lumar będzie teraz automatycznie raportował wszystkie strony, na których zablokowane są AI Google i Bing.
Potrzebujesz dodatkowego wsparcia technicznego? Dowiedz się więcej o ofercie technologicznej Semetrical lub skontaktuj się z nami, aby uzyskać więcej informacji!