
Jarvis Rising – Jak Google może generować model uczenia maszynowego „w locie”, aby przewidywać odpowiedzi, gdy wyszukiwarka nie może, i jak może indeksować te modele, aby przewidywać odpowiedzi na przyszłe zapytania [Patent]
Opublikowany: 2023-07-13
Po przeanalizowaniu patentu Google'a związanego z PAA i PASF, zacząłem przeglądać inne ostatnio przyznane patenty. Nie minęło dużo czasu, zanim ujawniłem kolejny bardzo interesujący temat dotyczący wykorzystania modeli uczenia maszynowego. Patent, który właśnie przeanalizowałem, koncentruje się na wykorzystaniu i/lub wygenerowaniu modelu uczenia maszynowego w odpowiedzi na zapytanie (kiedy Google musi przewidzieć odpowiedź, ponieważ standardowe wyniki wyszukiwania nie mogą zapewnić odpowiedniej odpowiedzi). Po wielokrotnym przeczytaniu patentu podkreślono, jak wyrafinowane mogą być systemy Google, gdy trzeba zapewnić użytkownikom wysokiej jakości odpowiedź (lub prognozę).
Podobnie jak w przypadku każdego patentu, nigdy nie wiemy, czy Google rzeczywiście wdrożyło to, co obejmuje patent, ale zawsze jest to możliwe. A gdyby został wdrożony, Google nie tylko mógłby wykorzystywać wyszkolony model uczenia maszynowego do przewidywania odpowiedzi na zapytanie, ale mógłby indeksować te modele uczenia maszynowego, wiązać je z różnymi podmiotami, stronami internetowymi itp., a następnie pobierać i używać tych modeli do kolejnych powiązanych wyszukiwań. Pomyśl, jak potężne i skalowalne może to być dla Google.
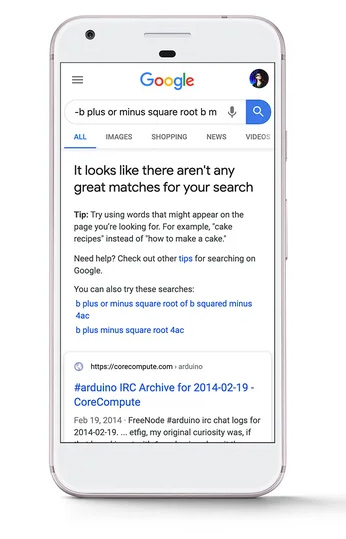
Ponadto patent wyjaśnia, że Google może przywrócić interaktywny interfejs do modelu uczenia maszynowego w wynikach wyszukiwania, który umożliwia użytkownikom dodawanie parametrów, które można wykorzystać do generowania prognoz dla zapytań, gdy wyniki wyszukiwania nie są wystarczające. Ta część patentu skłoniła mnie do zastanowienia się nad komunikatem, który Google wprowadził w SERP w kwietniu 2020 r., kiedy nie zwracano wysokiej jakości wyników wyszukiwania dla zapytania. Obecna implementacja nie zapewnia użytkownikom formularza do interakcji, ale z pewnością może w pewnym momencie. I być może ten interfejs mógłby być używany do większej liczby zapytań w przyszłości zamiast tylko tych bardziej niejasnych, które pojawiają się na razie. Omówię to więcej w punktach poniżej.
Kluczowe punkty z patentu:
Podobnie jak w moim ostatnim poście dotyczącym najnowszego patentu Google, myślę, że najlepszym sposobem na omówienie szczegółów jest przedstawienie kluczowych punktów.
Generowanie i/lub wykorzystywanie modelu uczenia maszynowego w odpowiedzi na żądanie wyszukiwania
US 11645277 B2
Data przyznania: 9 maja 2023 r
Data złożenia: 12 grudnia 2017 r
Nazwa cesjonariusza: Google LLC
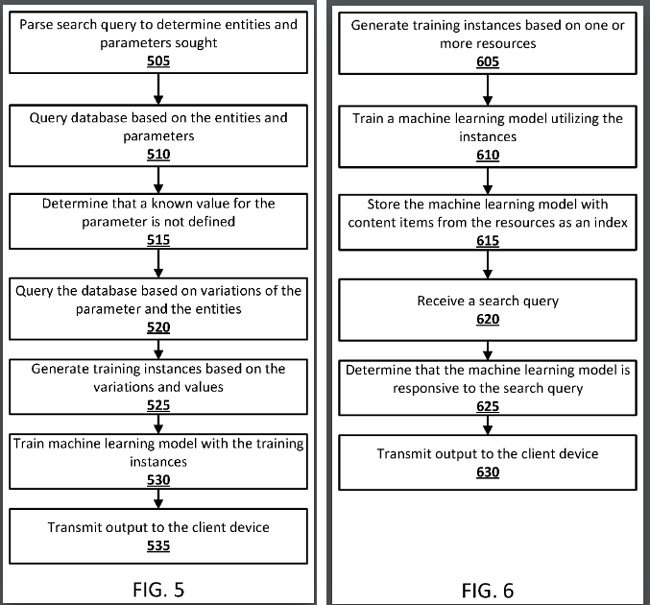
1. Patent Google wyjaśnia, że jeśli nie można z całą pewnością znaleźć odpowiedzi, a użytkownik przesyła żądanie, które ma charakter predykcyjny, do wygenerowania prognozy można użyć wyszkolonego modelu uczenia maszynowego.
2. Na przykład Google może najpierw wygenerować wyniki wyszukiwania na podstawie zapytania, ale jeśli wyniki nie są odpowiedniej jakości, można użyć modelu uczenia maszynowego, aby zapewnić lepszą przewidywaną odpowiedź. Tak więc system może zapewnić przewidywane odpowiedzi na podstawie modelu uczenia maszynowego, gdy odpowiedź nie może zostać zweryfikowana przez Google.

3. Ponadto model uczenia maszynowego można generować „w locie”, a Google może przechowywać wytrenowane modele uczenia maszynowego w indeksie wyszukiwania. Tak, Google może indeksować modele uczenia maszynowego, które zostały właśnie przeszkolone w celu dostarczania prognoz na podstawie określonych typów zapytań. Wkrótce opiszę więcej na ten temat.

4. Patent zawiera przykład oparty na zapytaniu „Ilu lekarzy będzie w Chinach w 2050 roku?” Jeśli nie można podać autorytatywnej odpowiedzi za pośrednictwem standardowych wyników wyszukiwania, zapytanie można przekazać do przeszkolonego modelu uczenia maszynowego w celu wygenerowania prognozy.

5. Patent dalej wyjaśnia, że system może wziąć inne lata, takie jak 2010, 2015, 2020 itd., i wykorzystać je do wygenerowania prognozy (poprzez model uczenia maszynowego wytrenowany na tych parametrach).

6. Patent wyjaśnia, że wytrenowane modele uczenia maszynowego mogą być indeksowane przez jeden lub więcej elementów treści z „zasobów wykorzystywanych do trenowania modelu”. W przypadku przyszłych zapytań, gdy system zidentyfikuje parametry związane z modelem uczenia maszynowego (np. jeśli kolejny użytkownik zada powiązane pytanie, takie jak „Ilu lekarzy będzie w Chinach w 2040 r. ?”), model uczenia maszynowego może wykorzystany do wygenerowania prognozy.

7. Patent dalej wyjaśnia, że modele uczenia maszynowego mogą być przechowywane z jednym lub kilkoma elementami treści, takimi jak jednostki na grafie wiedzy, nazwy tabel, nazwy kolumn, nazwy stron internetowych i inne. Ponadto słowa powiązane z zapytaniem, takie jak „Chiny” i „lekarze”, mogą zostać użyte przez model uczenia maszynowego do wygenerowania prognozy.
8. Patent wyjaśnia dalej, że system może zapewniać użytkownikom interaktywny interfejs do wybierania parametrów, które można przekazać do modelu uczenia maszynowego. Może to być pole tekstowe, menu rozwijane itp. Ponadto odpowiedź może zawierać komunikat prezentowany użytkownikowi, że odpowiedź jest prognozą opartą na wyszkolonym modelu uczenia maszynowego. Google chce więc upewnić się, że użytkownicy rozumieją, że jest to prognoza oparta na modelu uczenia maszynowego w porównaniu z odpowiedziami udzielanymi na podstawie zindeksowanych danych.

9. Wyszkolony model można następnie zweryfikować, aby upewnić się, że prognozy mają co najmniej „jakość progową”. Wszystko poniżej pewnego progu może zostać stłumione i nie zostanie udostępnione użytkownikowi. W takim przypadku zamiast tego można wyświetlić standardowe wyniki wyszukiwania.

10. Poza publicznymi wynikami wyszukiwania patent wyjaśnia, że system może być używany w prywatnej bazie danych, aby pomóc firmom przewidzieć określone wyniki. Patent wyjaśnia: „prywatny dla grupy użytkowników, korporacji i/lub innych ograniczonych zestawów”. Na przykład pracownik parku rozrywki może zapytać: „ile jutro sprzedamy stożków śnieżnych?” System może następnie wysłać zapytanie do prywatnej bazy danych, aby poznać sprzedaż z poprzednich dni, informacje o pogodzie, dane dotyczące obecności itp., aby przewidzieć odpowiedź dla pracownika.
11. Patent wyjaśnia, że system może w pewnym momencie dostarczać powiadomienia push od „automatycznego asystenta”. I tak głośno myśląc, zastanawiam się, czy to może być od asystenta podobnego do Jarvisa, jak wyjaśniłem w moim poście o Google Code Red, który wywołał tysiące Code Reds u wydawców.

12. Z punktu widzenia opóźnienia patent wyjaśnia, że może wystąpić opóźnienie po przesłaniu zapytania przez użytkownika. W takim przypadku standardowe wyniki wyszukiwania mogą być początkowo wyświetlane wraz z komunikatem, że „dobre” wyniki nie są dostępne dla zapytania i że do generowania prognozy używany jest model uczenia maszynowego. W takich sytuacjach system może przekazać tę prognozę użytkownikowi w późniejszym czasie lub udostępnić hiperłącze, które użytkownicy mogą kliknąć, aby wyświetlić dane wyjściowe uczenia maszynowego.
13. Ponadto patent mówi, że w niektórych sytuacjach użytkownik musiałby potwierdzić monit, aby proces mógł być kontynuowany. Na przykład system może wyświetlić komunikat o treści „Dobra odpowiedź nie jest dostępna. Czy chcesz, żebym przewidział dla ciebie odpowiedź? Następnie model uczenia maszynowego zostanie przeszkolony tylko wtedy, gdy w odpowiedzi na monit zostaną odebrane pozytywne dane wejściowe użytkownika. Jak wyjaśniłem wcześniej, widzę powiązanie z komunikatem „Nie ma świetnych dopasowań do Twojego wyszukiwania”, który pojawił się w kwietniu 2020 r. Zastanawiam się, czy można by go rozszerzyć, aby wykorzystać ten model w przyszłości…

Podsumowanie: Google może przewidywać wysokiej jakości odpowiedzi w potężny i superwydajny sposób za pomocą (indeksowanych) modeli uczenia maszynowego.
Chociaż nie wiemy, czy używany jest jakiś konkretny patent, siła i wydajność tego procesu ma dla Google duży sens. Od generowania modeli uczenia maszynowego „w locie”, przez indeksowanie tych modeli do wykorzystania w przyszłości, aż po interaktywny interfejs z powiadomieniami push, wydaje się, że Google przygotowuje grunt pod asystenta takiego jak Jarvis. Więc następnym razem, gdy poprosisz Google o przewidzenie odpowiedzi, pomyśl o tym patencie. W pewnym momencie możesz po prostu zostać poproszony o więcej informacji (dopóki Jarvis nie będzie w stanie zrobić tego wszystkiego w nanosekundę). :)
GG