
Opanowanie skrobaków stron internetowych: przewodnik dla początkujących dotyczący wydobywania danych online
Opublikowany: 2024-04-09Co to są skrobaki stron internetowych?
Skrobak stron internetowych to narzędzie przeznaczone do wydobywania danych ze stron internetowych. Symuluje nawigację człowieka w celu zebrania określonej treści. Początkujący często wykorzystują te skrobaki do różnorodnych zadań, w tym do badań rynku, monitorowania cen i kompilacji danych na potrzeby projektów uczenia maszynowego.
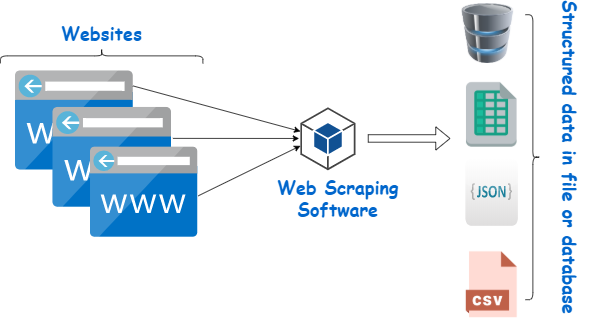
Źródło obrazu: https://www.webharvy.com/articles/what-is-web-scraping.html
- Łatwość obsługi: są przyjazne dla użytkownika i umożliwiają osobom o minimalnych umiejętnościach technicznych skuteczne przechwytywanie danych internetowych.
- Wydajność: Scrapery mogą szybko gromadzić duże ilości danych, znacznie przewyższając wysiłki związane z ręcznym gromadzeniem danych.
- Dokładność: automatyczne skrobanie zmniejsza ryzyko błędu ludzkiego, zwiększając dokładność danych.
- Ekonomiczne: eliminują potrzebę ręcznego wprowadzania danych, oszczędzając koszty pracy i czas.
Zrozumienie funkcjonalności skrobaków stron internetowych ma kluczowe znaczenie dla każdego, kto chce wykorzystać moc danych internetowych.
Tworzenie prostego skrobaka stron internetowych w języku Python
Aby rozpocząć tworzenie skrobaka stron internetowych w Pythonie, należy zainstalować pewne biblioteki, a mianowicie żądania wysyłające żądania HTTP do strony internetowej oraz BeautifulSoup z bs4 do analizowania dokumentów HTML i XML.
- Narzędzia do zbierania:
- Biblioteki: Użyj żądań do pobrania stron internetowych i BeautifulSoup do analizowania pobranej zawartości HTML.
- Targetowanie strony internetowej:
- Zdefiniuj adres URL strony internetowej zawierającej dane, które chcemy zeskrobać.
- Pobieranie treści:
- Korzystając z żądań, pobierz kod HTML strony internetowej.
- Analizowanie kodu HTML:
- BeautifulSoup przekształci pobrany kod HTML w ustrukturyzowany format ułatwiający nawigację.
- Wyodrębnianie danych:
- Zidentyfikuj konkretne tagi HTML zawierające pożądane informacje (np. tytuły produktów w tagach <div>).
- Korzystając z metod BeautifulSoup, wyodrębnij i przetwórz potrzebne dane.
Pamiętaj, aby wybrać określone elementy HTML powiązane z informacjami, które chcesz zeskrobać.
Proces skrobania strony internetowej krok po kroku
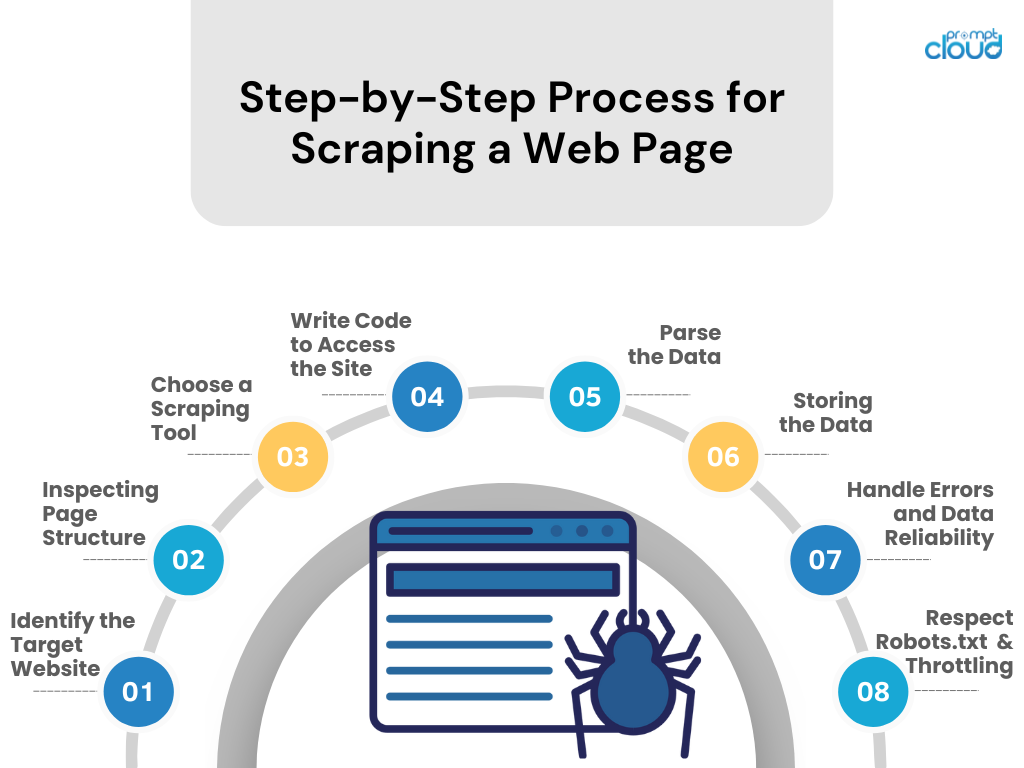
- Zidentyfikuj docelową witrynę internetową
Sprawdź witrynę, którą chcesz zeskrobać. Upewnij się, że jest to zgodne z prawem i etyczne. - Sprawdzanie struktury strony
Użyj narzędzi programistycznych przeglądarki, aby sprawdzić strukturę HTML, selektory CSS i treść opartą na JavaScript. - Wybierz narzędzie do skrobania
Wybierz narzędzie lub bibliotekę w języku programowania, który znasz (np. BeautifulSoup lub Scrapy w języku Python). - Napisz kod, aby uzyskać dostęp do witryny
Utwórz skrypt żądający danych ze strony internetowej, korzystając z wywołań API, jeśli są dostępne, lub żądań HTTP. - Przeanalizuj dane
Wyodrębnij odpowiednie dane ze strony internetowej, analizując kod HTML/CSS/JavaScript. - Przechowywanie danych
Zapisz zeskrobane dane w ustrukturyzowanym formacie, takim jak CSV, JSON, lub bezpośrednio w bazie danych. - Obsługa błędów i niezawodność danych
Zaimplementuj obsługę błędów, aby zarządzać błędami żądań i zachować integralność danych. - Szanuj plik Robots.txt i ograniczanie przepustowości
Przestrzegaj reguł witryny dotyczących pliku robots.txt i unikaj obciążania serwera poprzez kontrolowanie liczby żądań.
Wybór idealnych narzędzi do skrobania sieci dla Twoich potrzeb
Podczas przeglądania Internetu kluczowy jest wybór narzędzi dostosowanych do Twoich umiejętności i celów. Początkujący powinni rozważyć:
- Łatwość obsługi: wybierz intuicyjne narzędzia z pomocą wizualną i przejrzystą dokumentacją.
- Wymagania dotyczące danych: Oceń strukturę i złożoność danych docelowych, aby określić, czy konieczne jest proste rozszerzenie lub solidne oprogramowanie.
- Budżet: porównaj koszt z funkcjami; wiele skutecznych skrobaków oferuje bezpłatne poziomy.
- Dostosowanie: Upewnij się, że narzędzie można dostosować do konkretnych potrzeb w zakresie skrobania.
- Wsparcie: Dostęp do pomocnej społeczności użytkowników pomaga w rozwiązywaniu problemów i ulepszaniu.
Wybieraj mądrze, aby zapewnić płynne skrobanie.
Wskazówki i porady dotyczące optymalizacji skrobaka stron internetowych
- Użyj wydajnych bibliotek analizujących, takich jak BeautifulSoup lub Lxml w Pythonie, aby przyspieszyć przetwarzanie HTML.
- Zaimplementuj buforowanie, aby uniknąć ponownego pobierania stron i zmniejszyć obciążenie serwera.
- Szanuj pliki robots.txt i używaj ograniczania szybkości, aby zapobiec zablokowaniu przez docelową witrynę.
- Zmieniaj programy użytkownika i serwery proxy, aby naśladować ludzkie zachowanie i unikać wykrycia.
- Zaplanuj zgarniacze poza godzinami szczytu, aby zminimalizować wpływ na wydajność witryny.
- Jeśli są dostępne, wybierz punkty końcowe API, ponieważ dostarczają one uporządkowane dane i są ogólnie bardziej wydajne.
- Unikaj usuwania niepotrzebnych danych, zadając zapytania selektywnie, zmniejszając wymaganą przepustowość i przestrzeń dyskową.
- Regularnie aktualizuj swoje skrobaki, aby dostosować się do zmian w strukturze witryny i zachować integralność danych.
Obsługa typowych problemów i rozwiązywanie problemów podczas skrobania stron internetowych
Podczas pracy ze skrobakami stron internetowych początkujący mogą napotkać kilka typowych problemów:

- Problemy z selektorami : Upewnij się, że selektory odpowiadają bieżącej strukturze strony internetowej. Narzędzia takie jak narzędzia programistyczne przeglądarki mogą pomóc w zidentyfikowaniu właściwych selektorów.
- Treść dynamiczna : niektóre strony internetowe ładują treść dynamicznie za pomocą JavaScript. W takich przypadkach rozważ użycie przeglądarek bezgłowych lub narzędzi renderujących JavaScript.
- Zablokowane żądania : strony internetowe mogą blokować skrobaki. Stosuj strategie takie jak rotacja agentów użytkownika, używanie serwerów proxy i przestrzeganie pliku robots.txt, aby złagodzić blokowanie.
- Problemy z formatem danych : Wyodrębnione dane mogą wymagać czyszczenia lub sformatowania. Użyj wyrażeń regularnych i manipulacji ciągami, aby ujednolicić dane.
Pamiętaj, aby zapoznać się z dokumentacją i forami społeczności, aby uzyskać szczegółowe wskazówki dotyczące rozwiązywania problemów.
Wniosek
Początkujący mogą teraz wygodnie zbierać dane z Internetu za pomocą skrobaka stron internetowych, dzięki czemu badania i analizy są bardziej wydajne. Zrozumienie właściwych metod przy jednoczesnym uwzględnieniu aspektów prawnych i etycznych pozwala użytkownikom wykorzystać pełny potencjał web scrapingu. Postępuj zgodnie z tymi wskazówkami, aby sprawnie wprowadzić się w proces scrapowania stron internetowych, pełen cennych spostrzeżeń i podejmowania świadomych decyzji.
Często zadawane pytania:
Co to jest skrobanie strony?
Skrobanie sieci, znane również jako skrobanie danych lub zbieranie danych z sieci, polega na automatycznym wyodrębnianiu danych ze stron internetowych za pomocą programów komputerowych imitujących ludzkie zachowania nawigacyjne. Dzięki skrobakowi stron internetowych można szybko sortować ogromne ilości informacji, skupiając się wyłącznie na istotnych sekcjach, zamiast je ręcznie kompilować.
Firmy stosują web scraping do takich celów, jak badanie kosztów, zarządzanie reputacją, analizowanie trendów i przeprowadzanie analiz konkurencji. Wdrożenie projektów web scrapingu gwarantuje sprawdzenie, czy odwiedzane strony internetowe akceptują działanie i przestrzegają wszystkich odpowiednich protokołów robots.txt i no-follow.
Jak zeskrobać całą stronę?
Aby zeskrobać całą stronę internetową, zazwyczaj potrzebne są dwa komponenty: sposób na zlokalizowanie wymaganych danych na stronie internetowej oraz mechanizm zapisywania tych danych w innym miejscu. Wiele języków programowania obsługuje skrobanie sieci, zwłaszcza Python i JavaScript.
Dla obu istnieją różne biblioteki open source, co jeszcze bardziej upraszcza proces. Niektóre popularne opcje wśród programistów Pythona to BeautifulSoup, Requests, LXML i Scrapy. Alternatywnie platformy komercyjne, takie jak ParseHub i Octoparse, umożliwiają mniej technicznym osobom wizualne tworzenie złożonych przepływów pracy związanych z przeglądaniem stron internetowych. Po zainstalowaniu niezbędnych bibliotek i zrozumieniu podstawowych pojęć stojących za wyborem elementów DOM, rozpocznij od zidentyfikowania interesujących punktów danych na docelowej stronie internetowej.
Wykorzystaj narzędzia programistyczne przeglądarki, aby sprawdzić znaczniki i atrybuty HTML, a następnie przetłumacz te ustalenia na odpowiednią składnię obsługiwaną przez wybraną bibliotekę lub platformę. Na koniec określ preferencje formatu wyjściowego, CSV, Excel, JSON, SQL lub inną opcję, wraz z miejscami docelowymi, w których znajdują się zapisane dane.
Jak korzystać ze skrobaka Google?
Wbrew powszechnemu przekonaniu Google nie oferuje bezpośrednio publicznego narzędzia do przeglądania sieci jako takiego, pomimo udostępniania interfejsów API i pakietów SDK ułatwiających bezproblemową integrację z wieloma produktami. Niemniej jednak wykwalifikowani programiści stworzyli rozwiązania innych firm oparte na podstawowych technologiach Google, skutecznie rozszerzając możliwości poza funkcjonalność natywną. Przykładami mogą być SerpApi, które eliminują skomplikowane aspekty Google Search Console i przedstawiają łatwy w użyciu interfejs do śledzenia rankingu słów kluczowych, szacowania ruchu organicznego i eksploracji linków zwrotnych.
Chociaż technicznie różnią się od tradycyjnego skrobania sieci, te modele hybrydowe zacierają linie oddzielające konwencjonalne definicje. Inne przykłady ilustrują wysiłki inżynierii wstecznej zastosowane w celu rekonstrukcji wewnętrznej logiki sterującej Google Maps Platform, YouTube Data API v3 lub Google Shopping Services, uzyskując funkcjonalności niezwykle zbliżone do oryginalnych odpowiedników, aczkolwiek podlegające różnym stopniom legalności i ryzyka dla zrównoważonego rozwoju. Ostatecznie początkujący programiści zajmujący się skrobaniem stron internetowych powinni zbadać różne opcje i ocenić zalety w odniesieniu do konkretnych wymagań, zanim zdecydują się na daną ścieżkę.
Czy skrobak Facebooka jest legalny?
Jak stwierdzono w Zasadach dla programistów Facebooka, nieautoryzowane skrobanie sieci stanowi wyraźne naruszenie standardów społeczności. Użytkownicy zgadzają się nie tworzyć ani nie obsługiwać aplikacji, skryptów ani innych mechanizmów mających na celu obejście lub przekroczenie wyznaczonych limitów szybkości API, ani też nie będą podejmować prób odszyfrowania, dekompilowania ani inżynierii wstecznej jakiegokolwiek aspektu Witryny lub Usługi. Ponadto podkreśla oczekiwania dotyczące ochrony danych i prywatności, wymagając wyraźnej zgody użytkownika przed udostępnieniem danych osobowych poza dozwolonym kontekstem.
Każde nieprzestrzeganie przedstawionych zasad powoduje eskalację środków dyscyplinarnych, począwszy od ostrzeżeń i stopniowo prowadzących do ograniczonego dostępu lub całkowitego odebrania przywilejów w zależności od poziomu dotkliwości. Niezależnie od wyjątków stworzonych dla badaczy bezpieczeństwa działających w ramach zatwierdzonych programów nagród za błędy, ogólny konsensus opowiada się za unikaniem niesankcjonowanych inicjatyw usuwania danych z Facebooka w celu uniknięcia niepotrzebnych komplikacji. Zamiast tego rozważ skorzystanie z alternatyw zgodnych z obowiązującymi normami i konwencjami zatwierdzonymi przez platformę.