
Przeszukiwacz sieciowy Python – samouczek krok po kroku
Opublikowany: 2023-12-07Roboty indeksujące to fascynujące narzędzia w świecie gromadzenia danych i przeglądania sieci. Automatyzują proces poruszania się po sieci w celu gromadzenia danych, które można wykorzystać do różnych celów, takich jak indeksowanie w wyszukiwarkach, eksploracja danych czy analiza konkurencji. W tym samouczku wyruszymy w pouczającą podróż mającą na celu zbudowanie podstawowego robota sieciowego przy użyciu Pythona, języka znanego ze swojej prostoty i potężnych możliwości w obsłudze danych internetowych.
Python, ze swoim bogatym ekosystemem bibliotek, stanowi doskonałą platformę do tworzenia robotów indeksujących. Niezależnie od tego, czy jesteś początkującym programistą, entuzjastą danych, czy po prostu ciekawi Cię, jak działają roboty indeksujące, ten przewodnik krok po kroku ma na celu wprowadzenie Cię w podstawy przeszukiwania sieci i wyposażenie Cię w umiejętności potrzebne do stworzenia własnego robota indeksującego .
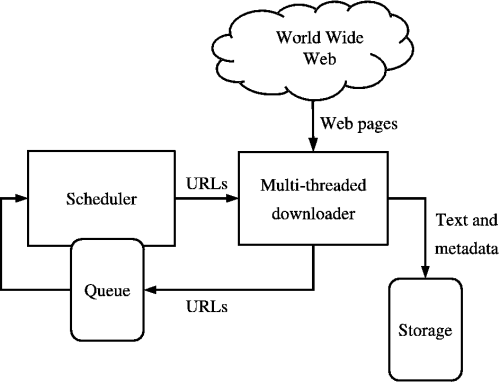
Źródło: https://medium.com/kariyertech/web-crawling-general-perspective-713971e9c659
Przeszukiwacz sieciowy w języku Python — jak zbudować przeszukiwacz sieciowy
Krok 1: Zrozumienie podstaw
Robot sieciowy, znany również jako pająk, to program przeglądający sieć WWW w metodyczny i zautomatyzowany sposób. W naszym przeszukiwaczu użyjemy języka Python ze względu na jego prostotę i potężne biblioteki.
Krok 2: Skonfiguruj swoje środowisko
Zainstaluj Python : Upewnij się, że masz zainstalowany Python. Można go pobrać z python.org.
Zainstaluj biblioteki : Będziesz potrzebować żądań do wysyłania żądań HTTP i BeautifulSoup z bs4 do analizowania HTML. Zainstaluj je za pomocą pip:
żądania instalacji pip pip install piękna zupa4
Krok 3: Napisz podstawowy robot indeksujący
Importuj biblioteki :
import żądań z bs4 import BeautifulSoup
Pobierz stronę internetową :
Tutaj pobierzemy zawartość strony internetowej. Zastąp „URL” stroną internetową, którą chcesz zaindeksować.
url = odpowiedź „URL” = żądania.get(url) treść = odpowiedź.treść
Przeanalizuj zawartość HTML :
zupa = BeautifulSoup(treść, 'html.parser')
Informacje o wyciągu :
Na przykład, aby wyodrębnić wszystkie hiperłącza, możesz:
dla linku w zupie.find_all('a'): print(link.get('href'))
Krok 4: Rozwiń swój robot
Obsługa względnych adresów URL :
Użyj urljoin do obsługi względnych adresów URL.
z urllib.parse zaimportuj urljoin
Unikaj dwukrotnego indeksowania tej samej strony :
Utrzymuj zestaw odwiedzanych adresów URL, aby uniknąć nadmiarowości.
Dodawanie opóźnień :
Pełen szacunek obejmuje opóźnienia między żądaniami. Użyj funkcji time.sleep().
Krok 5: Szanuj plik Robots.txt
Upewnij się, że robot indeksujący przestrzega pliku robots.txt witryn internetowych, który wskazuje, które części witryny nie powinny być indeksowane.
Krok 6: Obsługa błędów
Zaimplementuj bloki try-except, aby obsłużyć potencjalne błędy, takie jak przekroczenie limitu czasu połączenia lub odmowa dostępu.
Krok 7: Zejście głębiej
Możesz ulepszyć swojego robota, aby obsługiwał bardziej złożone zadania, takie jak przesyłanie formularzy lub renderowanie JavaScript. W przypadku witryn z dużą ilością JavaScript rozważ użycie Selenium.
Krok 8: Przechowuj dane
Zdecyduj, jak przechowywać przeszukane dane. Opcje obejmują proste pliki, bazy danych, a nawet bezpośrednie wysyłanie danych na serwer.
Krok 9: Postępuj etycznie
- Nie przeciążaj serwerów; dodaj opóźnienia w swoich prośbach.
- Postępuj zgodnie z warunkami korzystania z serwisu.
- Nie kopiuj ani nie przechowuj danych osobowych bez pozwolenia.
Zablokowanie jest częstym wyzwaniem podczas przeszukiwania sieci, szczególnie w przypadku witryn internetowych, które posiadają środki do wykrywania i blokowania automatycznego dostępu. Oto kilka strategii i rozważań, które pomogą Ci poruszać się po tym problemie w Pythonie:
Zrozumienie, dlaczego zostajesz zablokowany
Częste żądania: szybkie, powtarzające się żądania z tego samego adresu IP mogą powodować blokowanie.
Wzorce inne niż ludzkie: boty często zachowują się inaczej niż wzorce przeglądania ludzi, np. zbyt szybkie uzyskiwanie dostępu do stron lub w przewidywalnej kolejności.
Niewłaściwe zarządzanie nagłówkami: brakujące lub nieprawidłowe nagłówki HTTP mogą sprawić, że Twoje żądania będą wyglądać podejrzanie.
Ignorowanie pliku robots.txt: Nieprzestrzeganie wytycznych zawartych w pliku robots.txt witryny może prowadzić do blokad.
Strategie pozwalające uniknąć zablokowania
Szanuj plik robots.txt : zawsze sprawdzaj plik robots.txt witryny i przestrzegaj go. Jest to praktyka etyczna, która może zapobiec niepotrzebnemu blokowaniu.
Rotacja agentów użytkownika : strony internetowe mogą identyfikować Cię poprzez Twojego agenta użytkownika. Obracając go, zmniejszasz ryzyko, że zostaniesz oznaczony jako bot. Aby to zaimplementować, użyj biblioteki fake_useragent.
z fake_useragent import UserAgent ua = nagłówki UserAgent() = {'User-Agent': ua.random}

Dodawanie opóźnień : wdrożenie opóźnienia między żądaniami może naśladować ludzkie zachowanie. Użyj funkcji time.sleep(), aby dodać losowe lub stałe opóźnienie.
czas importu time.sleep(3) # Czeka 3 sekundy
Rotacja IP : Jeśli to możliwe, użyj usług proxy, aby zmienić swój adres IP. W tym celu dostępne są zarówno bezpłatne, jak i płatne usługi.
Korzystanie z sesji : obiekt request.Session w Pythonie może pomóc w utrzymaniu spójnego połączenia i udostępnianiu nagłówków, plików cookie itp. w żądaniach, dzięki czemu robot indeksujący będzie wyglądał bardziej jak zwykła sesja przeglądarki.
z żądaniami.Session() jako sesja: session.headers = {'User-Agent': ua.random} odpowiedź = session.get(url)
Obsługa JavaScript : Niektóre strony internetowe w dużym stopniu korzystają z JavaScript do ładowania treści. Narzędzia takie jak Selenium czy Puppeteer mogą naśladować prawdziwą przeglądarkę, włączając renderowanie JavaScript.
Obsługa błędów : Zaimplementuj solidną obsługę błędów, aby sprawnie zarządzać blokami i innymi problemami i reagować na nie.
Względy etyczne
- Zawsze przestrzegaj warunków korzystania z witryny internetowej. Jeśli witryna wyraźnie zabrania skrobania sieci, najlepiej się do tego zastosować.
- Pamiętaj o wpływie robota na zasoby witryny. Przeciążenie serwera może spowodować problemy dla właściciela witryny.
Zaawansowane techniki
- Struktury Web Scraping : Rozważ użycie frameworków takich jak Scrapy, które mają wbudowane funkcje do obsługi różnych problemów z indeksowaniem.
- Usługi rozwiązywania problemów CAPTCHA : w przypadku witryn z wyzwaniami CAPTCHA dostępne są usługi, które mogą rozwiązać problemy CAPTCHA, chociaż ich użycie budzi wątpliwości etyczne.
Najlepsze praktyki przeszukiwania sieci w języku Python
Angażowanie się w działania związane z przeszukiwaniem sieci wymaga równowagi między wydajnością techniczną a odpowiedzialnością etyczną. Używając języka Python do przeszukiwania sieci, ważne jest przestrzeganie najlepszych praktyk, które uwzględniają dane i strony internetowe, z których pochodzą. Oto kilka kluczowych uwag i najlepszych praktyk dotyczących przeszukiwania sieci w języku Python:
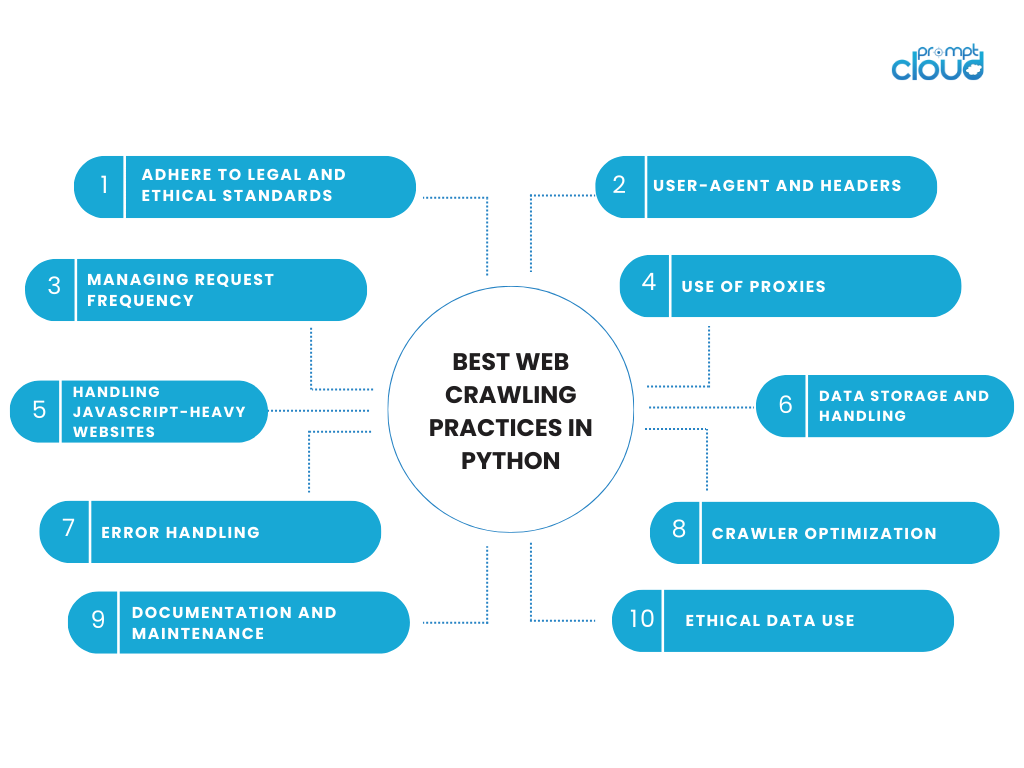
Przestrzegaj standardów prawnych i etycznych
- Szanuj plik robots.txt: zawsze sprawdzaj plik robots.txt witryny. Plik ten przedstawia obszary witryny, których właściciel witryny woli nie indeksować.
- Postępuj zgodnie z Warunkami korzystania z usług: Wiele witryn internetowych zawiera klauzule dotyczące skrobania sieci w swoich warunkach korzystania z usług. Przestrzeganie tych warunków jest zarówno etyczne, jak i prawnie rozważne.
- Unikaj przeciążania serwerów: Wysyłaj żądania w rozsądnym tempie, aby uniknąć nadmiernego obciążenia serwera witryny.
Agent użytkownika i nagłówki
- Zidentyfikuj się: użyj ciągu znaków klienta użytkownika zawierającego Twoje dane kontaktowe lub cel indeksowania. Ta przejrzystość może budować zaufanie.
- Używaj odpowiednio nagłówków: dobrze skonfigurowane nagłówki HTTP mogą zmniejszyć prawdopodobieństwo zablokowania. Mogą zawierać informacje takie jak klient użytkownika, język akceptacji itp.
Zarządzanie częstotliwością żądań
- Dodaj opóźnienia: zaimplementuj opóźnienie między żądaniami, aby naśladować wzorce przeglądania przez ludzi. Użyj funkcji time.sleep() Pythona.
- Ograniczanie szybkości: Bądź świadomy, ile żądań wysyłasz do witryny w danym przedziale czasu.
Korzystanie z serwerów proxy
- Rotacja adresów IP: Używanie serwerów proxy do rotacji adresu IP może pomóc uniknąć blokowania na podstawie adresu IP, ale należy to robić w sposób odpowiedzialny i etyczny.
Obsługa witryn internetowych z dużą ilością JavaScript
- Treść dynamiczna: w przypadku witryn, które dynamicznie ładują treść za pomocą JavaScript, narzędzia takie jak Selenium lub Puppeteer (w połączeniu z Pyppeteer dla Pythona) mogą renderować strony jak przeglądarka.
Przechowywanie i przetwarzanie danych
- Przechowywanie danych: przechowuj przeszukane dane w sposób odpowiedzialny, biorąc pod uwagę przepisy i regulacje dotyczące prywatności danych.
- Minimalizuj wyodrębnianie danych: wyodrębniaj tylko te dane, których potrzebujesz. Unikaj gromadzenia danych osobowych lub wrażliwych, chyba że jest to absolutnie konieczne i zgodne z prawem.
Obsługa błędów
- Solidna obsługa błędów: Zaimplementuj kompleksową obsługę błędów, aby zarządzać problemami takimi jak przekroczenia limitu czasu, błędy serwera lub niemożność wczytania treści.
Optymalizacja robota
- Skalowalność: zaprojektuj robota tak, aby obsługiwał zwiększoną skalę, zarówno pod względem liczby przeszukiwanych stron, jak i ilości przetwarzanych danych.
- Wydajność: zoptymalizuj swój kod pod kątem wydajności. Wydajny kod zmniejsza obciążenie zarówno systemu, jak i serwera docelowego.
Dokumentacja i konserwacja
- Zachowaj dokumentację: Dokumentuj swój kod i logikę indeksowania do wykorzystania w przyszłości i konserwacji.
- Regularne aktualizacje: Aktualizuj swój kod indeksujący, zwłaszcza jeśli zmieni się struktura docelowej witryny.
Etyczne wykorzystanie danych
- Etyczne wykorzystanie: Korzystaj ze zgromadzonych danych w sposób etyczny, szanując prywatność użytkowników i normy dotyczące wykorzystania danych.
Podsumowując
Kończąc naszą eksplorację tworzenia robota sieciowego w Pythonie, przeszliśmy przez zawiłości automatycznego gromadzenia danych i związane z tym względy etyczne. To przedsięwzięcie nie tylko podnosi nasze umiejętności techniczne, ale także pogłębia naszą wiedzę na temat odpowiedzialnego przetwarzania danych w rozległym krajobrazie cyfrowym.
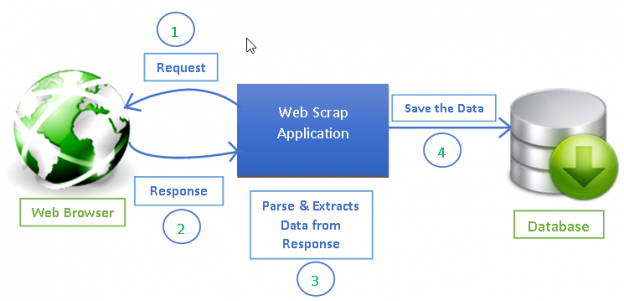
Źródło: https://www.datacamp.com/tutorial/making-web-crawlers-scrapy-python
Jednak utworzenie i utrzymanie robota sieciowego może być złożonym i czasochłonnym zadaniem, szczególnie w przypadku firm o specyficznych potrzebach w zakresie danych na dużą skalę. W tym miejscu wchodzą w grę niestandardowe usługi skrobania sieci PromptCloud. Jeśli szukasz dostosowanego, wydajnego i etycznego rozwiązania spełniającego wymagania dotyczące danych internetowych, PromptCloud oferuje szereg usług dostosowanych do Twoich unikalnych potrzeb. Od obsługi złożonych witryn internetowych po dostarczanie czystych, ustrukturyzowanych danych — zapewniają, że Twoje projekty przeglądania stron internetowych będą bezproblemowe i zgodne z celami biznesowymi.
Dla firm i osób prywatnych, które mogą nie mieć czasu lub wiedzy technicznej na tworzenie własnych robotów indeksujących i zarządzanie nimi, zlecanie tego zadania ekspertom takim jak PromptCloud może zmienić zasady gry. Ich usługi nie tylko oszczędzają czas i zasoby, ale także zapewniają, że otrzymujesz najdokładniejsze i istotne dane, a wszystko to przy jednoczesnym przestrzeganiu standardów prawnych i etycznych.
Chcesz dowiedzieć się więcej o tym, jak PromptCloud może zaspokoić Twoje specyficzne potrzeby w zakresie danych? Skontaktuj się z nimi pod adresem sales@promptcloud.com, aby uzyskać więcej informacji i omówić, w jaki sposób ich niestandardowe rozwiązania do skrobania sieci mogą pomóc w rozwoju Twojej firmy.
W dynamicznym świecie danych internetowych posiadanie niezawodnego partnera, takiego jak PromptCloud, może wzmocnić Twoją firmę, zapewniając przewagę w podejmowaniu decyzji w oparciu o dane. Pamiętaj, że w dziedzinie gromadzenia i analizy danych właściwy partner robi różnicę.
Udanego polowania na dane!