
Wybór i konfiguracja silników wnioskowania dla LLM
Opublikowany: 2024-04-02Wprowadzenie do silników wnioskowania
Istnieje wiele technik optymalizacji opracowanych w celu łagodzenia nieefektywności występujących na różnych etapach procesu wnioskowania. Trudno jest skalować wnioskowanie na dużą skalę za pomocą transformatora/technik waniliowych. Silniki wnioskowania łączą optymalizacje w jeden pakiet i ułatwiają nam proces wnioskowania.
W przypadku bardzo małego zestawu testów adhoc lub szybkiego odniesienia, do wnioskowania możemy użyć kodu transformatora waniliowego.
Krajobraz silników wnioskowania szybko ewoluuje, ponieważ mamy wiele możliwości wyboru, ważne jest przetestowanie i stworzenie krótkiej listy najlepszych z najlepszych dla konkretnych przypadków użycia. Poniżej znajduje się kilka eksperymentów z silnikami wnioskowania, które przeprowadziliśmy i powody, dla których odkryliśmy, dlaczego zadziałało to w naszym przypadku.
Próbowaliśmy tego w przypadku naszego dopracowanego modelu Vicuna-7B
- TGI
- vLLM
- Afrodyta
- Optimum-Nvidia
- PowerInfer
- LAMACPP
- Ctłumacz2
Przejrzeliśmy stronę Github i jej przewodnik szybkiego startu, aby skonfigurować te silniki. PowerInfer, LlaamaCPP, Ctranslate2 nie są zbyt elastyczne i nie obsługują wielu technik optymalizacji, takich jak ciągłe przetwarzanie wsadowe, uwaga stronicowana i utrzymywana poniżej normy wydajność w porównaniu do innych wymienionych silników .
Aby uzyskać wyższą przepustowość, silnik/serwer wnioskowania powinien zmaksymalizować możliwości pamięci i obliczeń, a zarówno klient, jak i serwer muszą pracować równolegle/asynchronicznie, obsługując żądania, aby serwer zawsze działał. Jak wspomniano wcześniej, bez pomocy technik optymalizacyjnych, takich jak PagedAttention, Flash Attention, ciągłe przetwarzanie wsadowe, zawsze będzie to prowadzić do nieoptymalnej wydajności.
TGI, vLLM i Aphrodite są pod tym względem bardziej odpowiednimi kandydatami i wykonując wiele eksperymentów opisanych poniżej, znaleźliśmy optymalną konfigurację, która pozwala wycisnąć maksymalną wydajność z wnioskowania. Techniki takie jak ciągłe przetwarzanie wsadowe i uwaga stronicowana są domyślnie włączone. Na potrzeby poniższych testów należy ręcznie włączyć dekodowanie spekulatywne w silniku wnioskowania.
Analiza porównawcza silników wnioskowania
TGI
Aby użyć TGI, możemy przejść przez sekcję „Rozpocznij” na stronie github, tutaj okno dokowane jest najprostszym sposobem konfiguracji i używania silnika TGI.
Argumenty programu uruchamiającego generowanie tekstu -> ta lista przedstawia różne ustawienia, których możemy użyć po stronie serwera. Kilka ważnych,
- –max-input-length : określa maksymalną długość danych wejściowych do modelu, w większości przypadków wymaga to zmian, ponieważ wartość domyślna to 1024.
- –max-tokeny ogółem: max całkowita liczba tokenów, tj. długość tokena wejściowego i wyjściowego.
- –spekuluj, –quantiz, –max-concurrent-requests -> domyślnie jest tylko 128, czyli oczywiście mniej.
Aby rozpocząć lokalnie dostrojony model,
uruchomienie okna dokowanego – urządzenie gpus = 1 – shm-size 1g -p 9091:80 -v /path/to/fine_tuned_v1:/model ghcr.io/huggingface/text- Generation-inference:1.4.4 –model-id /model – dtype float16 – liczba-odłamek 1 – maksymalna długość-wejściowa 3600 – maksymalna suma tokenów 4000 – spekuluj 2
Aby uruchomić model z koncentratora,
model=”lmsys/vicuna-7b-v1.5″; objętość=$PWD/dane; token=”<hf_token>”; uruchomienie okna dokowanego –gpus all –shm-size 1g -e HUGGING_FACE_HUB_TOKEN=$token -p 9091:80 -v $volume:/data ghcr.io/huggingface/text-generowanie-inferencja:1.4.4 –model-id $model – dtype float16 – liczba-odłamek 1 – maksymalna długość-wejściowa 3600 – maksymalna suma tokenów 4000 – spekuluj 2
Możesz poprosić chatGPT o wyjaśnienie powyższego polecenia, aby uzyskać bardziej szczegółowe zrozumienie. Tutaj uruchamiamy serwer wnioskowania na porcie 9091. Możemy także użyć klienta w dowolnym języku, aby wysłać żądanie do serwera. Interfejs API wnioskowania o generowaniu tekstu -> wymienia wszystkie punkty końcowe i parametry ładunku na potrzeby żądania.
Np
ładunek=”<podpowiedź tutaj>”
curl -XPOST „0.0.0.0:9091/generate” -H „Typ zawartości: aplikacja/json” -d „{„wejścia”: $ładunek, „parametry”: {„max_new_tokens”: 400”, „do_sample”:false „best_of”: null, „repetition_penalty”: 1, „return_full_text”: false, „seed”: null, „stop_sequences”: null, „temperatura”: 0,1, „top_k”: 100, „top_p”: 0,3”, truncate”: null, „typical_p”: null, „watermark”: false, „decoder_input_details”: false }}”
Kilka obserwacji,
- Opóźnienie wzrasta wraz z maksymalnymi tokenami, co jest oczywiste, że jeśli przetwarzamy długi tekst, ogólny czas się wydłuży.
- Spekulacje pomagają, ale zależy to od przypadku użycia i rozkładu danych wejściowych i wyjściowych.
- Kwantyzacja Eetq najbardziej pomaga w zwiększeniu przepustowości.
- Jeśli masz procesor graficzny z wieloma procesorami graficznymi, uruchomienie 1 interfejsu API na każdym procesorze graficznym i posiadanie tych interfejsów API z wieloma procesorami graficznymi za modułem równoważenia obciążenia skutkuje wyższą przepustowością niż sharding przez sam TGI.
vLLM
Aby uruchomić serwer vLLM, możemy użyć serwera/dokującego REST API kompatybilnego z OpenAI. Rozpoczęcie jest bardzo proste, postępuj zgodnie z instrukcją Deploying with Docker — vLLM, jeśli zamierzasz używać modelu lokalnego, podłącz wolumin i użyj ścieżki jako nazwy modelu,
docker run –runtime nvidia –gpus urządzenie=1 –shm-size 1g -v /path/to/fine_tuned_v1:/model -v ~/.cache/ -p 8000:8000 –ipc=host vllm/vllm-openai:latest – modelka/modelka
Powyżej uruchomi się serwer vLLM na wspomnianym porcie 8000, jak zawsze możesz pobawić się argumentami.
Złóż żądanie opublikowania za pomocą,
„skorupa
ładunek=”<podpowiedź tutaj>”
curl -XPOST -m 1200 „0.0.0.0:8000/v1/completions” -H „Typ zawartości: aplikacja/json” -d „{„podpowiedź”: $ładunek”, model”:”/model” ”, max_tokens ”: 400”, „top_p”: 0,3, „top_k”: 100, „temperatura”: 0,1}”
„`
Afrodyta
„skorupa
pip zainstaluj aphrodite-engine
python -m aphrodite.endpoints.openai.api_server – model PygmalionAI/pygmalion-2-7b

„`
Lub
„`
docker run -v /ścieżka/do/fine_tuned_v1:/model -d -e NAZWA_MODULU=”/model” -p 2242:7860 –urządzenie gpus=1 –ipc host alpindale/aphrodite-engine
„`
Aphrodite zapewnia instalację zarówno pip, jak i dockera, jak wspomniano w sekcji Wprowadzenie. Docker jest ogólnie stosunkowo łatwiejszy do uruchomienia i przetestowania. Opcje użytkowania, opcje serwera pomagają nam w wysyłaniu żądań.
- Zarówno Aphrodite, jak i vLLM korzystają z ładunków opartych na serwerze OpenAI, więc możesz sprawdzić ich dokumentację.
- Wypróbowaliśmy deepspeed-mii, ponieważ jest on w stanie przejściowym (kiedy próbowaliśmy) ze starszej wersji do nowej bazy kodu, nie wygląda na niezawodny i łatwy w użyciu.
- Optimum-NVIDIA nie obsługuje innych znaczących optymalizacji i powoduje nieoptymalną wydajność, link ref.
- Dodano istotę, kod, którego używaliśmy do wykonywania równoległych żądań ad hoc.
Metryki i pomiary
Chcemy wypróbować i znaleźć:
- Optymalny nr. wątków dla klienta/serwera silnika wnioskowania.
- Jak rośnie przepustowość wraz ze wzrostem pamięci
- Jak rośnie przepustowość w przypadku rdzeni tensorowych.
- Wpływ wątków na równoległe żądania klienta.
Bardzo prostym sposobem zaobserwowania wykorzystania jest obejrzenie go za pomocą narzędzi linuxowych nvidia-smi, nvtop. To powie nam zajętą pamięć, wykorzystanie obliczeń, szybkość przesyłania danych itp.
Innym sposobem jest profilowanie procesu przy użyciu GPU z nsys.
| Nr S | GPU | Pamięć VRAM | Silnik wnioskowania | Wątki | Czas (y) | Spekulować |
| 1 | A6000 | 48/48 GB | TGI | 24 | 664 | – |
| 2 | A6000 | 48/48 GB | TGI | 64 | 561 | – |
| 3 | A6000 | 48/48 GB | TGI | 128 | 554 | – |
| 4 | A6000 | 48/48 GB | TGI | 256 | 568 | – |
W oparciu o powyższe eksperymenty, wątek 128/256 jest lepszy niż niższy numer wątku i powyżej 256 narzutów, co przyczynia się do zmniejszenia przepustowości. Okazuje się, że zależy to od procesora i procesora graficznego i wymaga własnego eksperymentu. | ||||||
| 5 | A6000 | 48/48 GB | TGI | 128 | 596 | 2 |
| 6 | A6000 | 48/48 GB | TGI | 128 | 945 | 8 |
Wyższa wartość spekulacji powoduje więcej odrzuceń naszego dopracowanego modelu, a tym samym zmniejsza przepustowość. 1/2, ponieważ wartość spekulacyjna jest w porządku, zależy to od modelu i nie gwarantuje się, że będzie działać tak samo w różnych przypadkach użycia. Ale wniosek jest taki, że dekodowanie spekulatywne poprawia przepustowość. | ||||||
| 7 | 3090 | 24/24 GB | TGI | 128 | 741 | 2 |
| 7 | 4090 | 24/24 GB | TGI | 128 | 481 | 2 |
4090 ma mniej pamięci VRAM w porównaniu do A6000, ale ma lepsze wyniki ze względu na większą liczbę rdzeni tensorowych i większą przepustowość pamięci. | ||||||
| 8 | A6000 | 24/48 GB | TGI | 128 | 707 | 2 |
| 9 | A6000 | 2x24/48 GB | TGI | 128 | 1205 | 2 |
Konfigurowanie i konfiguracja TGI pod kątem dużej przepustowości
Skonfiguruj żądania asynchroniczne w wybranym języku skryptowym, takim jak python/Ruby, i używając tego samego pliku do konfiguracji, który znaleźliśmy:
- Czas trwania zwiększa maksymalną długość wyjściową generowania sekwencji.
- 128/256 wątków na kliencie i serwerze jest lepsze niż 24, 64, 512. Podczas korzystania z niższych wątków moc obliczeniowa jest niedostatecznie wykorzystywana i powyżej progu takiego jak 128 narzut staje się większy, a tym samym zmniejsza się przepustowość.
- Istnieje 6% poprawa podczas przeskakiwania z żądań asynchronicznych do równoległych przy użyciu „równoległego GNU” zamiast wątków w językach takich jak Go, Python/Ruby.
- 4090 ma o 12% wyższą przepustowość niż A6000. 4090 ma mniej pamięci VRAM w porównaniu do A6000, ale ma lepsze wyniki ze względu na większą liczbę rdzeni tensorowych i większą przepustowość pamięci.
- Ponieważ A6000 ma 48 GB pamięci vRAM, aby stwierdzić, czy dodatkowa pamięć RAM pomaga w poprawie przepustowości, czy nie, próbowaliśmy użyć ułamków pamięci GPU w eksperymencie 8 z tabeli i widzimy, że dodatkowa pamięć RAM pomaga w poprawie, ale nie liniowo. Również przy próbie rozdzielenia, tj. hostowania 2 interfejsów API na tym samym procesorze graficznym przy użyciu połowy pamięci dla każdego interfejsu API, zachowuje się jak działające 2 kolejne interfejsy API, zamiast akceptować żądania równolegle.
Obserwacje i metryki
Poniżej znajdują się wykresy niektórych eksperymentów i czasu potrzebnego na ukończenie ustalonego zestawu danych wejściowych, im krótszy czas, tym lepiej.
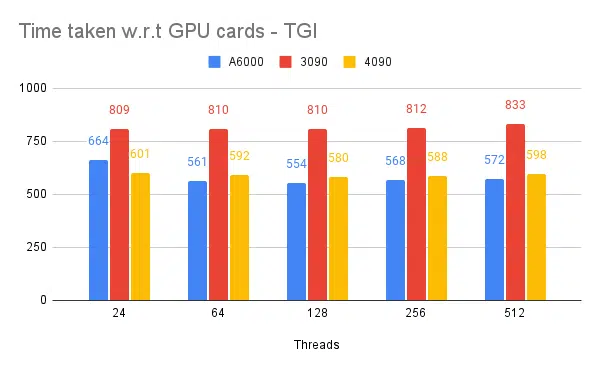
- Wspomniane są wątki po stronie klienta. Po stronie serwera musimy wspomnieć przy uruchamianiu silnika wnioskowania.
Testowanie spekulacyjne:

Testowanie wielu silników wnioskowania:
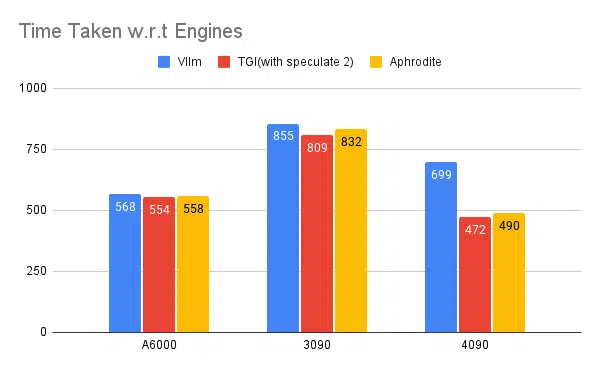
Tego samego rodzaju eksperymenty przeprowadzone z innymi silnikami, takimi jak vLLM i Aphrodite, zaobserwowaliśmy podobne wyniki, w chwili pisania tego artykułu vLLM i Aphrodite nie obsługują jeszcze dekodowania spekulatywnego, pozostaje nam wybrać TGI, ponieważ zapewnia wyższą przepustowość niż wynikająca z odpoczynku do spekulatywnego dekodowania.
Dodatkowo można skonfigurować profilery GPU, aby zwiększyć obserwowalność, pomagając w identyfikacji obszarów o nadmiernym zużyciu zasobów i optymalizując wydajność. Czytaj dalej: Narzędzia programistyczne Nvidia Nsight — Max Katz
Wniosek
Widzimy, że krajobraz generowania wnioskowań stale się rozwija, a poprawa przepustowości w LLM wymaga dobrego zrozumienia procesora graficznego, wskaźników wydajności, technik optymalizacji i wyzwań związanych z zadaniami generowania tekstu. Pomaga to w wyborze odpowiednich narzędzi do pracy. Rozumiejąc wewnętrzne elementy procesora graficznego i ich związek z wnioskowaniem LLM, na przykład wykorzystując rdzenie tensorowe i maksymalizując przepustowość pamięci, programiści mogą wybrać opłacalny procesor graficzny i skutecznie zoptymalizować wydajność.
Różne karty graficzne oferują różne możliwości, a zrozumienie różnic ma kluczowe znaczenie przy wyborze najodpowiedniejszego sprzętu do określonych zadań. Techniki takie jak ciągłe dozowanie, uwaga stronicowana, łączenie jąder i uwaga błyskawiczna oferują obiecujące rozwiązania pozwalające przezwyciężyć pojawiające się wyzwania i poprawić wydajność. Na podstawie eksperymentów i wyników, które uzyskaliśmy, TGI wydaje się najlepszym wyborem dla naszego przypadku użycia.
Przeczytaj inne artykuły związane z modelem dużego języka:
Zrozumienie architektury GPU na potrzeby optymalizacji wnioskowania LLM
Zaawansowane techniki zwiększania przepustowości LLM