
Przewodnik krok po kroku dotyczący tworzenia robota sieciowego
Opublikowany: 2023-12-05W zawiłym gobelinie Internetu, gdzie informacje są rozproszone po niezliczonych stronach internetowych, roboty indeksujące wyłaniają się jako niedoceniani bohaterowie, pilnie pracujący nad porządkowaniem, indeksowaniem i udostępnianiem tego bogactwa danych. W tym artykule omówiono roboty indeksujące, rzucając światło na ich podstawowe działanie, rozróżniając przeszukiwanie sieci od skrobania sieci i dostarczając praktycznych informacji, takich jak przewodnik krok po kroku dotyczący tworzenia prostego przeszukiwacza sieciowego opartego na języku Python. W miarę zagłębiania się w szczegóły odkryjemy możliwości zaawansowanych narzędzi, takich jak Scrapy, i odkryjemy, jak PromptCloud przenosi indeksowanie sieci do skali przemysłowej.
Co to jest przeszukiwacz sieci
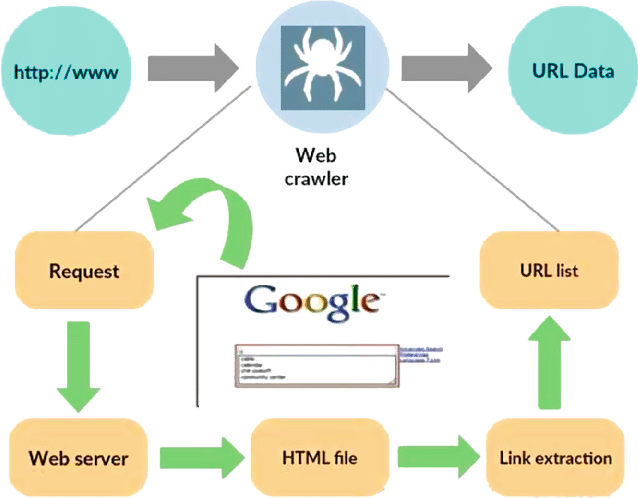
Źródło: https://www.researchgate.net/figure/Working-model-of-web-crawler_fig1_316089973
Robot sieciowy, znany również jako pająk lub bot, to wyspecjalizowany program zaprojektowany do systematycznego i autonomicznego poruszania się po rozległych obszarach sieci WWW. Jego podstawową funkcją jest przeglądanie stron internetowych, zbieranie danych i indeksowanie informacji do różnych celów, takich jak optymalizacja wyszukiwarek, indeksowanie treści lub ekstrakcja danych.
W swojej istocie robot sieciowy naśladuje działania użytkownika, ale w znacznie szybszym i wydajniejszym tempie. Rozpoczyna swoją podróż od wyznaczonego punktu początkowego, często określanego jako początkowy adres URL, a następnie podąża za hiperłączami z jednej strony internetowej na drugą. Proces podążania za linkami ma charakter rekurencyjny, umożliwiając robotowi eksplorowanie znacznej części Internetu.
Gdy robot indeksujący odwiedza strony internetowe, systematycznie wyodrębnia i przechowuje odpowiednie dane, które mogą obejmować tekst, obrazy, metadane i inne. Wyodrębnione dane są następnie porządkowane i indeksowane, co ułatwia wyszukiwarkom wyszukiwanie i prezentowanie odpowiednich informacji użytkownikom w przypadku zapytania.
Roboty indeksujące odgrywają kluczową rolę w funkcjonowaniu wyszukiwarek takich jak Google, Bing i Yahoo. Stale i systematycznie przeszukując sieć, zapewniają aktualność indeksów wyszukiwarek, zapewniając użytkownikom dokładne i trafne wyniki wyszukiwania. Ponadto roboty indeksujące są wykorzystywane w różnych innych zastosowaniach, w tym w agregacji treści, monitorowaniu witryn internetowych i eksploracji danych.
Skuteczność robota indeksującego opiera się na jego zdolności do poruszania się po różnorodnych strukturach witryny, obsługi zawartości dynamicznej i przestrzegania zasad ustalonych przez witryny internetowe za pomocą pliku robots.txt, który określa, które części witryny można przeszukiwać. Zrozumienie sposobu działania robotów indeksujących ma zasadnicze znaczenie dla docenienia ich znaczenia w zapewnianiu dostępności i organizacji ogromnej sieci informacji.
Jak działają roboty indeksujące
Roboty indeksujące, znane również jako pająki lub boty, działają poprzez systematyczny proces poruszania się po sieci WWW w celu gromadzenia informacji ze stron internetowych. Oto przegląd działania robotów indeksujących:
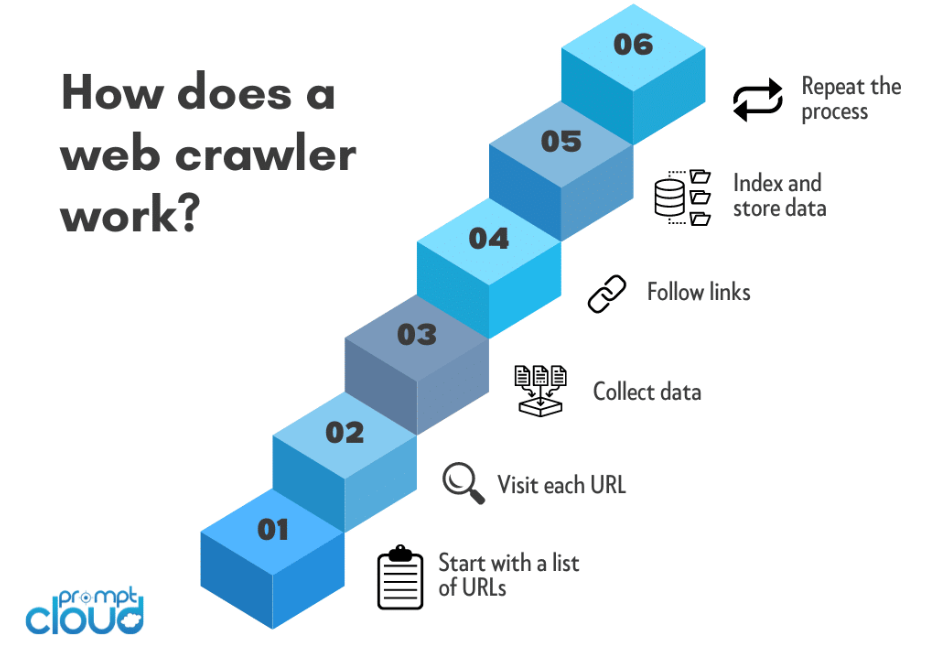
Wybór początkowego adresu URL:
Proces indeksowania sieci zwykle rozpoczyna się od początkowego adresu URL. Jest to początkowa strona internetowa lub witryna internetowa, od której robot rozpoczyna swoją podróż.
Żądanie HTTP:
Robot indeksujący wysyła żądanie HTTP do początkowego adresu URL w celu pobrania zawartości HTML strony internetowej. To żądanie jest podobne do żądań wysyłanych przez przeglądarki internetowe podczas uzyskiwania dostępu do strony internetowej.
Analiza HTML:
Po pobraniu treści HTML robot indeksujący analizuje ją w celu wyodrębnienia odpowiednich informacji. Obejmuje to rozbicie kodu HTML na ustrukturyzowany format, po którym robot może nawigować i analizować.
Wyodrębnianie adresu URL:
Robot indeksujący identyfikuje i wyodrębnia hiperłącza (adresy URL) obecne w treści HTML. Te adresy URL reprezentują łącza do innych stron, które robot będzie odwiedzał później.
Kolejka i harmonogram:
Wyodrębnione adresy URL są dodawane do kolejki lub harmonogramu. Kolejka gwarantuje, że robot będzie odwiedzał adresy URL w określonej kolejności, często nadając priorytet nowym lub nieodwiedzonym adresom URL.
Rekurencja:
Robot podąża za łączami w kolejce, powtarzając proces wysyłania żądań HTTP, analizowania treści HTML i wyodrębniania nowych adresów URL. Ten rekurencyjny proces umożliwia robotowi poruszanie się po wielu warstwach stron internetowych.
Ekstrakcja danych:
Gdy robot przemierza sieć, wyodrębnia odpowiednie dane z każdej odwiedzanej strony. Rodzaj wyodrębnionych danych zależy od celu robota i może obejmować tekst, obrazy, metadane lub inną konkretną treść.
Indeksowanie treści:
Zebrane dane są porządkowane i indeksowane. Indeksowanie polega na utworzeniu ustrukturyzowanej bazy danych, która ułatwia wyszukiwanie, pobieranie i prezentowanie informacji, gdy użytkownicy przesyłają zapytania.
Szacunek do pliku Robots.txt:
Roboty indeksujące zazwyczaj przestrzegają zasad określonych w pliku robots.txt witryny internetowej. Ten plik zawiera wytyczne dotyczące tego, które obszary witryny można przeszukiwać, a które należy wykluczyć.
Opóźnienia w indeksowaniu i uprzejmość:
Aby uniknąć przeciążania serwerów i powodowania zakłóceń, roboty indeksujące często zawierają mechanizmy opóźnień indeksowania i uprzejmości. Środki te zapewniają, że robot indeksujący wchodzi w interakcję ze stronami internetowymi w sposób pełen szacunku i niezakłócający działania.
Roboty indeksujące systematycznie poruszają się po sieci, śledząc łącza, wyodrębniając dane i budując zorganizowany indeks. Proces ten umożliwia wyszukiwarkom dostarczanie użytkownikom dokładnych i trafnych wyników na podstawie ich zapytań, dzięki czemu roboty indeksujące stają się podstawowym elementem nowoczesnego ekosystemu internetowego.

Indeksowanie sieci a skrobanie sieci

Źródło: https://research.aimultiple.com/web-crawling-vs-web-scraping/
Chociaż przeszukiwanie sieci i skrobanie sieci są często używane zamiennie, służą one różnym celom. Przeszukiwanie sieci polega na systematycznym poruszaniu się po sieci w celu indeksowania i gromadzenia informacji, natomiast przeszukiwanie sieci koncentruje się na wydobywaniu określonych danych ze stron internetowych. Zasadniczo przeszukiwanie sieci polega na eksplorowaniu i mapowaniu sieci, podczas gdy przeszukiwanie sieci polega na zbieraniu ukierunkowanych informacji.
Budowa robota sieciowego
Budowa prostego przeszukiwacza sieciowego w języku Python obejmuje kilka kroków, od skonfigurowania środowiska programistycznego po zakodowanie logiki przeszukiwacza. Poniżej znajduje się szczegółowy przewodnik, który pomoże Ci stworzyć podstawowy robot sieciowy przy użyciu Pythona, wykorzystując bibliotekę żądań do tworzenia żądań HTTP i BeautifulSoup do analizowania HTML.
Krok 1: Skonfiguruj środowisko
Upewnij się, że masz zainstalowany język Python w swoim systemie. Można go pobrać z python.org. Dodatkowo musisz zainstalować wymagane biblioteki:
pip install requests beautifulsoup4
Krok 2: Importuj biblioteki
Utwórz nowy plik Pythona (np. simple_crawler.py) i zaimportuj niezbędne biblioteki:
import requests from bs4 import BeautifulSoup
Krok 3: Zdefiniuj funkcję przeszukiwacza
Utwórz funkcję, która pobiera adres URL jako dane wejściowe, wysyła żądanie HTTP i wyodrębnia odpowiednie informacje z treści HTML:
def simple_crawler(url):
# Send HTTP request to the URL
response = requests.get(url)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Parse HTML content with BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Extract and print relevant information (modify as needed)
title = soup.title.text
print(f'Title: {title}')
# Additional data extraction and processing can be added here
else:
print(f'Error: Failed to fetch {url}')
Krok 4: Przetestuj robota
Podaj przykładowy adres URL i wywołaj funkcję simple_crawler, aby przetestować robota:
if __name__ == "__main__": sample_url = 'https://example.com' simple_crawler(sample_url)
Krok 5: Uruchom robota
Wykonaj skrypt Pythona w terminalu lub w wierszu poleceń:
python simple_crawler.py
Robot pobierze treść HTML podanego adresu URL, przeanalizuje ją i wydrukuje tytuł. Możesz rozszerzyć robota, dodając więcej funkcji wyodrębniania różnych typów danych.
Przeszukiwanie sieci za pomocą Scrapy
Indeksowanie sieci za pomocą Scrapy otwiera drzwi do potężnej i elastycznej platformy zaprojektowanej specjalnie do wydajnego i skalowalnego skrobania sieci. Scrapy upraszcza złożoność tworzenia robotów sieciowych, oferując zorganizowane środowisko do tworzenia pająków, które mogą poruszać się po stronach internetowych, wydobywać dane i przechowywać je w systematyczny sposób. Oto bliższe spojrzenie na indeksowanie sieci za pomocą Scrapy:
Instalacja:
Zanim zaczniesz, upewnij się, że masz zainstalowany Scrapy. Możesz go zainstalować za pomocą:
pip install scrapy
Tworzenie projektu Scrapy:
Zainicjuj projekt Scrapy:
Otwórz terminal i przejdź do katalogu, w którym chcesz utworzyć projekt Scrapy. Uruchom następujące polecenie:
scrapy startproject your_project_name
Tworzy to podstawową strukturę projektu z niezbędnymi plikami.
Zdefiniuj pająka:
W katalogu projektu przejdź do folderu spiders i utwórz plik Pythona dla swojego pająka. Zdefiniuj klasę pająka, podklasując scrapy.Spider i podając niezbędne szczegóły, takie jak nazwa, dozwolone domeny i początkowe adresy URL.
import scrapy
class YourSpider(scrapy.Spider):
name = 'your_spider'
allowed_domains = ['example.com']
start_urls = ['http://example.com']
def parse(self, response):
# Define parsing logic here
pass
Wyodrębnianie danych:
Używanie selektorów:
Scrapy wykorzystuje potężne selektory do wyodrębniania danych z HTML. Możesz zdefiniować selektory w metodzie analizy pająka, aby przechwytywać określone elementy.
def parse(self, response):
title = response.css('title::text').get()
yield {'title': title}
Ten przykład wyodrębnia zawartość tekstową znacznika <title>.
Następujące linki:
Scrapy upraszcza proces podążania za linkami. Użyj poniższej metody, aby przejść do innych stron.
def parse(self, response):
for next_page in response.css('a::attr(href)').getall():
yield response.follow(next_page, self.parse)
Uruchamianie pająka:
Uruchom pająka za pomocą następującego polecenia z katalogu projektu:
scrapy crawl your_spider
Scrapy zainicjuje pająka, podąży za łączami i wykona logikę analizowania zdefiniowaną w metodzie parsowania.
Indeksowanie sieci za pomocą Scrapy oferuje solidną i rozszerzalną platformę do obsługi złożonych zadań skrobania. Jego modułowa architektura i wbudowane funkcje sprawiają, że jest to preferowany wybór dla programistów zajmujących się wyrafinowanymi projektami ekstrakcji danych internetowych.
Indeksowanie sieci na dużą skalę
Indeksowanie sieci na dużą skalę stwarza wyjątkowe wyzwania, szczególnie w przypadku ogromnej ilości danych rozproszonych po wielu witrynach internetowych. PromptCloud to wyspecjalizowana platforma zaprojektowana w celu usprawnienia i optymalizacji procesu indeksowania sieci na dużą skalę. Oto, w jaki sposób PromptCloud może pomóc w obsłudze inicjatyw indeksowania sieci na dużą skalę:
- Skalowalność
- Ekstrakcja i wzbogacanie danych
- Jakość i dokładność danych
- Zarządzanie infrastrukturą
- Łatwość użycia
- Zgodność i etyka
- Monitorowanie i raportowanie w czasie rzeczywistym
- Wsparcie i konserwacja
PromptCloud to solidne rozwiązanie dla organizacji i osób chcących indeksować strony internetowe na dużą skalę. Rozwiązując kluczowe wyzwania związane z ekstrakcją danych na dużą skalę, platforma zwiększa wydajność, niezawodność i łatwość zarządzania inicjatywami przeszukiwania sieci.
W podsumowaniu
Roboty indeksujące są niedocenianymi bohaterami rozległego cyfrowego krajobrazu, pilnie poruszając się po sieci w celu indeksowania, gromadzenia i organizowania informacji. Wraz ze wzrostem skali projektów przeszukiwania sieci PromptCloud wkracza jako rozwiązanie, oferując skalowalność, wzbogacanie danych i zgodność z etyką, aby usprawnić inicjatywy na dużą skalę. Skontaktuj się z nami pod adresem sales@promptcloud.com