
Rola skrobania sieci w zwiększaniu dokładności modelu AI
Opublikowany: 2023-12-27Sztuczna inteligencja stale się rozwija, napędzana ogromnymi danymi potrzebnymi do udoskonalenia uczenia maszynowego. Ten proces uczenia się obejmuje rozpoznawanie wzorców i podejmowanie świadomych decyzji.
Wejdź do web scrapingu – istotnego gracza w poszukiwaniu danych. Polega na wydobywaniu ogromnych informacji ze stron internetowych, które są skarbnicą do szkolenia modeli AI. Harmonia między sztuczną inteligencją a web scrapingiem podkreśla opartą na danych istotę współczesnego uczenia maszynowego. W miarę rozwoju sztucznej inteligencji rośnie zapotrzebowanie na różnorodne zbiory danych, co sprawia, że skrobanie sieci staje się niezbędnym narzędziem dla programistów tworzących ostrzejsze i wydajniejsze systemy sztucznej inteligencji.
Ewolucja skrobania sieci: od ręcznego do wspomaganego sztuczną inteligencją
Rozwój skrobania sieci odzwierciedla postęp technologiczny. Wczesne metody były proste i wymagały ręcznej ekstrakcji danych – zadania często czasochłonnego i podatnego na błędy. W miarę szybkiego rozwoju Internetu techniki te nie nadążały za rosnącą ilością danych. Wprowadzono skrypty i boty w celu automatyzacji skrobania, ale brakowało im wyrafinowania.
Wprowadź sztuczną inteligencję do skrobania sieci, rewolucjonizującą gromadzenie danych. Uczenie maszynowe umożliwia teraz analizowanie złożonych, nieustrukturyzowanych danych, efektywnie je nadając im sens. Ta zmiana nie tylko przyspiesza gromadzenie danych, ale także poprawia ich jakość, umożliwiając bardziej wyrafinowane aplikacje i zapewniając bogatsze podłoże dla modeli sztucznej inteligencji, które nieustannie uczą się na podstawie ogromnych, zróżnicowanych zbiorów danych.
Źródło obrazu: https://www.scrapingdog.com/
Zrozumienie technologii AI w scrapowaniu sieci
Dzięki sztucznej inteligencji narzędzia do skrobania stron internetowych stały się potężniejsze. Sztuczna inteligencja automatyzuje rozpoznawanie wzorców podczas ekstrakcji danych, dzięki czemu identyfikowanie istotnych informacji jest szybsze i dokładniejsze. Zgarniacze internetowe oparte na sztucznej inteligencji mogą:
- Dostosuj się do różnych układów stron internetowych za pomocą uczenia maszynowego, zmniejszając w ten sposób potrzebę ręcznego projektowania szablonów.
- Wykorzystaj przetwarzanie języka naturalnego (NLP), aby zrozumieć i kategoryzować dane tekstowe, poprawiając jakość zbieranych danych.
- Wykorzystaj możliwości rozpoznawania obrazu, aby wyodrębnić treść wizualną, która może mieć kluczowe znaczenie w niektórych kontekstach analizy danych.
- Wdrażaj algorytmy wykrywania anomalii, aby identyfikować wartości odstające lub błędy ekstrakcji danych i zarządzać nimi, zapewniając integralność danych.
Dzięki mocy sztucznej inteligencji skrobanie sieci staje się silniejsze i bardziej elastyczne, spełniając obszerne wymagania dotyczące danych współczesnych zaawansowanych modeli sztucznej inteligencji.
Rola uczenia maszynowego w inteligentnej ekstrakcji danych
Uczenie maszynowe rewolucjonizuje ekstrakcję danych, umożliwiając systemom niezależne rozpoznawanie, rozumienie i wydobywanie odpowiednich informacji. Kluczowe wkłady obejmują:
- Rozpoznawanie wzorców : Algorytmy uczenia maszynowego doskonale radzą sobie z rozpoznawaniem wzorców i anomalii w dużych zbiorach danych, co czyni je idealnymi do identyfikowania odpowiednich punktów danych podczas przeglądania stron internetowych.
- Przetwarzanie języka naturalnego (NLP) : wykorzystując NLP, uczenie maszynowe może rozumieć i interpretować ludzki język, ułatwiając wydobywanie informacji z nieustrukturyzowanych źródeł danych, takich jak media społecznościowe.
- Uczenie się adaptacyjne : w miarę jak modele uczenia maszynowego mają kontakt z większą ilością danych, uczą się i poprawiają swoją dokładność, zapewniając z biegiem czasu proces ekstrakcji danych coraz wydajniejszy.
- Ograniczanie błędów ludzkich : dzięki uczeniu maszynowemu znacznie zmniejsza się prawdopodobieństwo błędów związanych z ręczną ekstrakcją danych, co poprawia jakość zbioru danych dla modeli AI.
Źródło obrazu: https://research.aimultiple.com/
Rozpoznawanie wzorców oparte na sztucznej inteligencji w celu wydajnego skrobania
Web scraping odgrywa kluczową rolę w zaspokajaniu rosnącego zapotrzebowania na dane w modelach uczenia maszynowego. Najważniejszym elementem jest rozpoznawanie wzorców oparte na sztucznej inteligencji, usprawniające ekstrakcję danych z niezwykłą wydajnością. Ta zaawansowana technika identyfikuje i kategoryzuje ogromne ilości danych przy minimalnym zaangażowaniu człowieka.
Wykorzystując skomplikowane algorytmy, sztuczna inteligencja do skrobania sieci szybko porusza się po stronach internetowych, rozpoznając wzorce i wyodrębniając ustrukturyzowane zbiory danych. Te zautomatyzowane systemy nie tylko działają szybciej, ale także znacznie zwiększają dokładność, minimalizując błędy w porównaniu z ręcznymi metodami skrobania. W miarę ewolucji sztucznej inteligencji jej zdolność do rozpoznawania skomplikowanych wzorców będzie w dalszym ciągu zmieniać krajobraz przeglądania stron internetowych i gromadzenia danych.
Przetwarzanie języka naturalnego na potrzeby agregacji treści
Kluczowa funkcja przetwarzania języka naturalnego (NLP) wysuwa się na pierwszy plan w agregacji treści, umożliwiając systemom AI skuteczne rozumienie, interpretowanie i organizowanie danych. Zapewnia skrobakom zdolność odróżniania istotnych informacji od nieistotnej paplaniny. Analizując semantykę i składnię tekstu, NLP klasyfikuje treść, wyodrębnia kluczowe elementy i podsumowuje informacje.

Te wydestylowane dane stają się podstawowym materiałem szkoleniowym dla modeli, które uczą się rozpoznawać wzorce, przewidywać zapytania użytkowników i dostarczać wnikliwych odpowiedzi. W związku z tym agregacja treści oparta na NLP ma kluczowe znaczenie w opracowywaniu inteligentniejszych, świadomych kontekstu modeli sztucznej inteligencji. Ułatwia ukierunkowane podejście do gromadzenia danych, udoskonalając surowe dane wejściowe, które zaspokajają nienasycony apetyt na dane współczesnej sztucznej inteligencji.
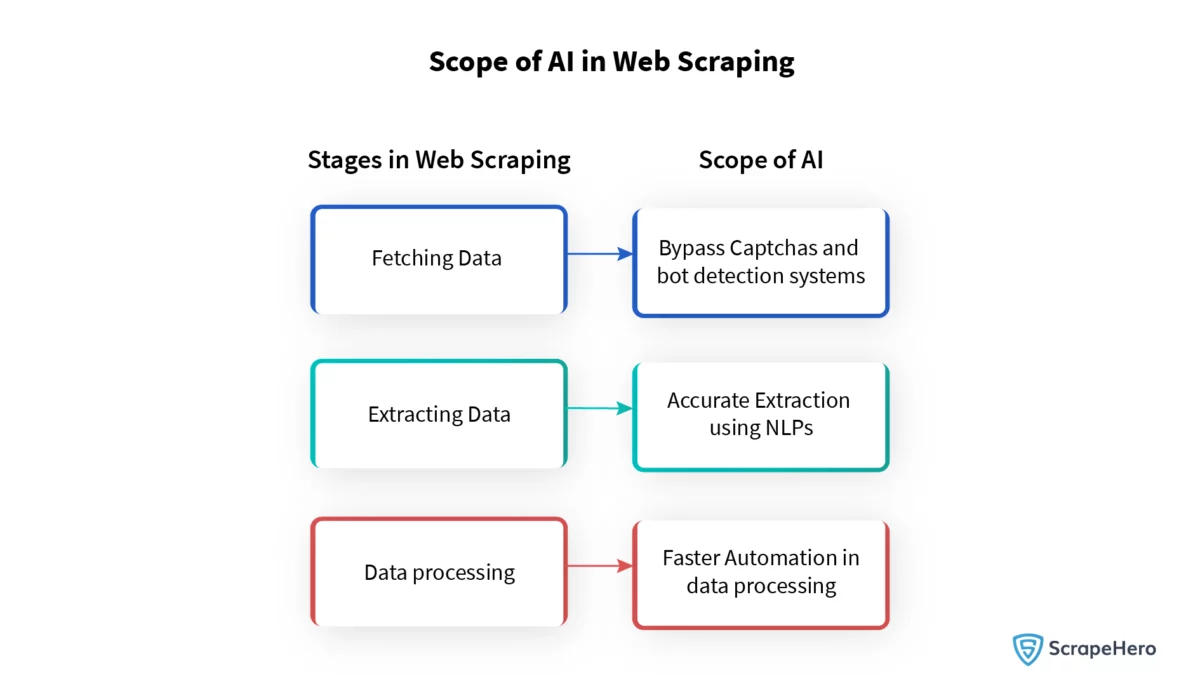
Pokonywanie wyzwań związanych z Captcha i zawartością dynamiczną dzięki sztucznej inteligencji
Captcha i dynamiczna treść stanowią ogromne bariery dla skutecznego przeglądania stron internetowych. Mechanizmy te mają na celu rozróżnienie między użytkownikami ludzkimi a usługami zautomatyzowanymi, często zakłócając wysiłki związane z gromadzeniem danych. Jednak postęp w sztucznej inteligencji wprowadził wyrafinowane rozwiązania:
- Algorytmy uczenia maszynowego znacznie poprawiły interpretację wizualnych captcha, naśladując ludzkie zdolności rozpoznawania wzorców.
- Narzędzia oparte na sztucznej inteligencji mogą teraz dostosowywać się do dynamicznych treści, ucząc się struktur stron i przewidywając zmiany lokalizacji danych.
- Niektóre systemy wykorzystują generatywne sieci przeciwstawne (GAN) do uczenia modeli, które potrafią rozwiązywać złożone captcha.
- Techniki przetwarzania języka naturalnego (NLP) pomagają zrozumieć semantykę dynamicznie generowanych tekstów, ułatwiając dokładną ekstrakcję danych.
W miarę toczenia się walki między twórcami captcha a twórcami sztucznej inteligencji każdy krok w technologii captcha jest równoważony przez bardziej przenikliwe i zwinniejsze środki zaradcze oparte na sztucznej inteligencji. Ta dynamiczna interakcja zapewnia płynny strumień danych, napędzając nieustanny rozwój branży sztucznej inteligencji.
Zwiększanie jakości i dokładności danych dzięki mocy aplikacji AI
Aplikacje sztucznej inteligencji (AI) znacznie poprawiają jakość i dokładność danych, co ma kluczowe znaczenie dla uczenia skutecznych modeli. Dzięki zastosowaniu zaawansowanych algorytmów sztuczna inteligencja może:
- Wykrywaj i naprawiaj niespójności w dużych zbiorach danych.
- Odfiltruj nieistotne informacje, koncentrując się na podzbiorach danych niezbędnych do zrozumienia modelu.
- Zweryfikuj dane w oparciu o wcześniej ustalone standardy jakości.
- Wykonuj czyszczenie danych w czasie rzeczywistym, co gwarantuje, że zbiory danych szkoleniowych pozostaną aktualne i dokładne.
- Korzystaj z uczenia się bez nadzoru, aby identyfikować wzorce lub anomalie, które mogą umknąć ludzkiej kontroli.
Wykorzystanie sztucznej inteligencji do przygotowywania danych nie tylko usprawnia proces; podnosi jakość wniosków uzyskanych z danych, co skutkuje inteligentniejszymi i bardziej niezawodnymi modelami sztucznej inteligencji.
Skalowanie operacji skrobania sieci dzięki integracji AI
Włączenie sztucznej inteligencji do praktyk web scrapingu znacznie zwiększa wydajność i skalowalność procesów gromadzenia danych. Systemy oparte na sztucznej inteligencji mogą dostosowywać się do różnych układów witryn i dokładnie wyodrębniać dane, nawet jeśli witryna ulega zmianom. Ta zdolność adaptacji wynika z algorytmów uczenia maszynowego, które uczą się na podstawie wzorców i anomalii podczas procesu skrobania.
Co więcej, sztuczna inteligencja może ustalać priorytety i kategoryzować punkty danych, szybko rozpoznając cenne informacje. Umiejętności przetwarzania języka naturalnego (NLP) umożliwiają narzędziom skrobanie rozumienie i przetwarzanie ludzkiego języka, umożliwiając w ten sposób wydobywanie nastrojów lub intencji z danych tekstowych. W miarę jak zadania skrobania stają się coraz bardziej złożone i objętościowe, integracja sztucznej inteligencji gwarantuje, że zadania te będą wykonywane przy ograniczonym ręcznym nadzorze, co prowadzi do bardziej usprawnionej i opłacalnej operacji. Wdrożenie takich inteligentnych systemów ułatwia:
- Automatyzacja identyfikacji i ekstrakcji odpowiednich danych
- Ciągłe uczenie się i dostosowywanie do nowych struktur internetowych
- Analiza i interpretacja nieustrukturyzowanych danych technikami NLP
- Zwiększenie dokładności i zmniejszenie potrzeby interwencji człowieka
Nadchodzące trendy: Przyszły krajobraz AI do skrobania sieci
Gdy poruszamy się po stale rozwijającej się dziedzinie sztucznej inteligencji, główny punkt wyłania się na niezwykłych postępach w sztucznej inteligencji przeszukującej strony internetowe. Poznaj te kluczowe trendy kształtujące przyszłość:
- Wszechstronne zrozumienie: sztuczna inteligencja rozszerza się, aby rozumieć kontekstowo filmy, obrazy i dźwięk.
- Uczenie się adaptacyjne: sztuczna inteligencja dostosowuje strategie skrobania w oparciu o struktury witryn internetowych, ograniczając interwencję człowieka.
- Precyzyjne wyodrębnianie danych: Algorytmy są dopracowywane w celu zapewnienia dokładnej i istotnej ekstrakcji danych.
- Bezproblemowa integracja: narzędzia do skrobania oparte na sztucznej inteligencji integrują się bezproblemowo z platformami analizy danych.
- Etyczne pozyskiwanie danych: sztuczna inteligencja uwzględnia wytyczne etyczne dotyczące zgody użytkownika i ochrony danych.
Źródło obrazu: https://www.scrapehero.com/
Doświadcz synergii skrobania stron internetowych i sztucznej inteligencji dla swoich potrzeb związanych z danymi. Skontaktuj się z PromptCloud pod adresem sales@promptcloud.com, aby uzyskać najnowocześniejsze usługi przeglądania stron internetowych, które podnoszą dokładność Twoich modeli AI.
Często zadawane pytania:
Czy sztuczna inteligencja może skrobać strony internetowe?
Z pewnością sztuczna inteligencja jest biegła w radzeniu sobie z zadaniami związanymi ze skrobaniem stron internetowych. Wyposażone w zaawansowane algorytmy systemy AI mogą samodzielnie przeglądać strony internetowe, identyfikować wzorce i wydobywać istotne dane z zauważalną wydajnością. Możliwość ta stanowi znaczący postęp, zwiększając szybkość, precyzję i elastyczność procedur ekstrakcji danych.
Czy scrapowanie stron internetowych jest nielegalne?
Jeśli chodzi o legalność skrobania sieci, jest to kwestia zróżnicowana. Samo skrobanie sieci nie jest z natury nielegalne, ale legalność zależy od sposobu jego wykonania. Odpowiedzialne i etyczne skrobanie, zgodne z warunkami korzystania z docelowych stron internetowych, ma kluczowe znaczenie dla uniknięcia komplikacji prawnych. Do skrobania stron internetowych należy podchodzić z rozwagą i przestrzeganiem zasad.
Czy ChatGPT może skrobać strony internetowe?
Jeśli chodzi o ChatGPT, nie zajmuje się on skrobaniem sieci. Jego mocną stroną jest zrozumienie i generowanie języka naturalnego oraz dostarczanie odpowiedzi na podstawie otrzymanych danych wejściowych. Do rzeczywistych zadań związanych ze skrobaniem sieci potrzebne są specjalistyczne narzędzia i oprogramowanie.
Ile kosztuje skrobak AI?
Rozważając koszt usług skrobaka AI, ważne jest, aby wziąć pod uwagę takie zmienne, jak złożoność zadania skrobania, ilość danych do wyodrębnienia i specyficzne potrzeby dostosowywania. Modele cenowe mogą obejmować opłaty jednorazowe, plany subskrypcji lub opłaty zależne od użytkowania. Aby uzyskać spersonalizowaną wycenę dostosowaną do Twoich wymagań, zaleca się skontaktowanie z dostawcą usług skrobania stron internetowych, takim jak PromptCloud.