
Zrozumienie architektury GPU na potrzeby optymalizacji wnioskowania LLM
Opublikowany: 2024-04-02Wprowadzenie do LLM i znaczenie optymalizacji GPU
W dzisiejszej erze postępu w przetwarzaniu języka naturalnego (NLP) modele dużego języka (LLM) stały się potężnymi narzędziami do niezliczonej liczby zadań, od generowania tekstu po odpowiadanie na pytania i podsumowywanie. To coś więcej niż kolejny prawdopodobny generator tokenów. Jednak rosnąca złożoność i rozmiar tych modeli stwarza poważne wyzwania w zakresie wydajności obliczeniowej i wydajności.
Na tym blogu zagłębiamy się w zawiłości architektury GPU, badając, w jaki sposób różne komponenty przyczyniają się do wnioskowania LLM. Omówimy kluczowe wskaźniki wydajności, takie jak przepustowość pamięci i wykorzystanie rdzenia tensora, a także wyjaśnimy różnice między różnymi kartami graficznymi, umożliwiając podejmowanie świadomych decyzji przy wyborze sprzętu do zadań związanych z dużymi modelami językowymi.
W szybko rozwijającym się środowisku, w którym zadania NLP wymagają stale rosnących zasobów obliczeniowych, optymalizacja przepustowości wnioskowania LLM ma ogromne znaczenie. Dołącz do nas, gdy wyruszamy w tę podróż, aby uwolnić pełny potencjał LLM poprzez techniki optymalizacji GPU i zagłębić się w różne narzędzia, które pozwalają nam skutecznie poprawiać wydajność.
Podstawy architektury GPU dla LLM – poznaj elementy wewnętrzne swojego procesora graficznego
Ze względu na charakter wykonywania wysoce wydajnych obliczeń równoległych, procesory graficzne stają się urządzeniami z wyboru do wykonywania wszystkich zadań głębokiego uczenia się, dlatego ważne jest zrozumienie ogólnego przeglądu architektury procesora graficznego, aby zrozumieć podstawowe wąskie gardła pojawiające się na etapie wnioskowania. Karty Nvidia są preferowane ze względu na CUDA (Compute Unified Device Architecture), zastrzeżoną platformę obliczeń równoległych i interfejs API opracowany przez firmę NVIDIA, który umożliwia programistom określenie równoległości na poziomie wątków w języku programowania C, zapewniając bezpośredni dostęp do wirtualnego zestawu instrukcji procesora graficznego i równoległości elementy obliczeniowe.
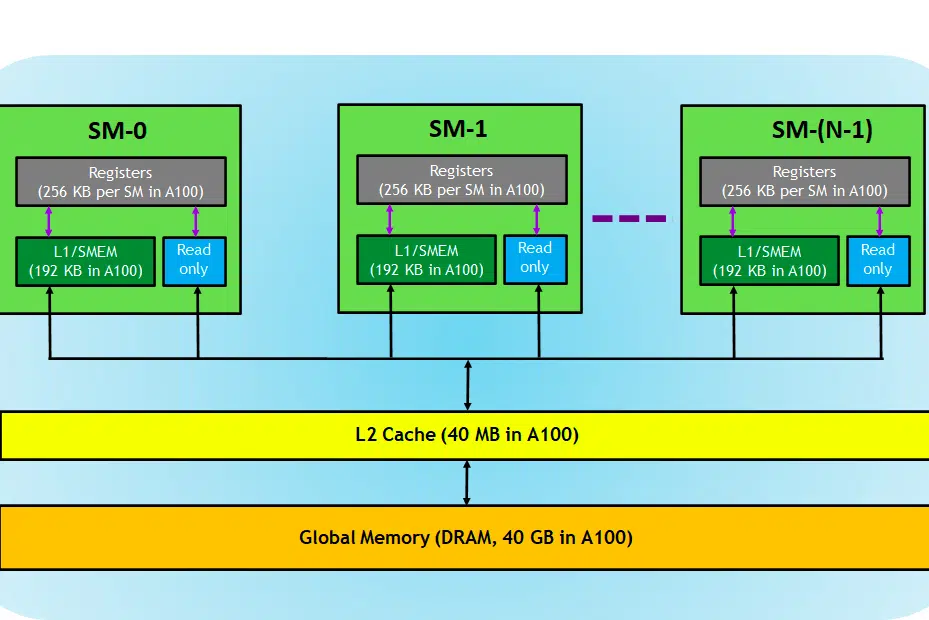
W kontekście użyliśmy karty NVIDIA do wyjaśnienia, ponieważ jest ona powszechnie preferowana w zadaniach głębokiego uczenia się, jak już wspomniano, i ma do tego zastosowanie kilka innych terminów, takich jak rdzenie Tensor.
Przyjrzyjmy się karcie GPU. Tutaj na obrazku widzimy trzy główne części i (jeszcze jedną główną ukrytą część) urządzenia GPU
- SM (wieloprocesorowe przesyłanie strumieniowe)
- Pamięć podręczna L2
- Przepustowość pamięci
- Pamięć globalna (DRAM)
Podobnie jak procesor-RAM, pamięć RAM jest miejscem przechowywania danych (tj. pamięci) i procesora do przetwarzania zadań (tj. procesu). W procesorze graficznym pamięć globalna o dużej przepustowości (DRAM) przechowuje wagi modelu (np. LLAMA 7B), które są ładowane do pamięci i w razie potrzeby wagi te są przesyłane do jednostki przetwarzającej (tj. procesora SM) w celu obliczeń.
Multiprocesory strumieniowe
Wieloprocesor strumieniowy (SM) to zbiór mniejszych jednostek wykonawczych zwanych rdzeniami CUDA (zastrzeżona platforma obliczeń równoległych firmy NVIDIA) wraz z dodatkowymi jednostkami funkcjonalnymi odpowiedzialnymi za pobieranie instrukcji, dekodowanie, planowanie i wysyłanie. Każdy SM działa niezależnie i zawiera własny plik rejestru, pamięć współdzieloną, pamięć podręczną L1 i jednostkę tekstury. SM są wysoce zrównoleglone, co pozwala im przetwarzać tysiące wątków jednocześnie, co jest niezbędne do osiągnięcia wysokiej przepustowości w zadaniach obliczeniowych GPU. Wydajność procesora zazwyczaj mierzy się w FLOPS, nie. operacji pływających, które może wykonać w każdej sekundzie.
Zadania głębokiego uczenia się składają się głównie z operacji tensorowych, tj. mnożenia macierz-macierz. Firma NVIDIA wprowadziła rdzenie tensorowe w procesorach graficznych nowszej generacji, które zostały zaprojektowane specjalnie do wykonywania tych operacji na tensorach w wysoce wydajny sposób. Jak wspomniano, rdzenie tensorowe są przydatne, jeśli chodzi o zadania głębokiego uczenia się i zamiast rdzeni CUDA musimy sprawdzić rdzenie Tensor, aby określić, jak wydajnie procesor graficzny może wykonywać szkolenie/wnioskowanie LLM.
Pamięć podręczna L2
Pamięć podręczna L2 to pamięć o dużej przepustowości, współdzielona przez SM, której celem jest optymalizacja dostępu do pamięci i wydajności przesyłania danych w systemie. Jest to mniejszy i szybszy typ pamięci, umieszczony bliżej jednostek przetwarzających (takich jak wieloprocesory strumieniowe) w porównaniu z pamięcią DRAM. Pomaga poprawić ogólną wydajność dostępu do pamięci, zmniejszając potrzebę dostępu do wolniejszej pamięci DRAM przy każdym żądaniu pamięci.
Przepustowość pamięci
Wydajność zależy więc od tego, jak szybko uda nam się przenieść wagi z pamięci do procesora oraz jak sprawnie i szybko procesor może przetworzyć zadane obliczenia.
Gdy wydajność obliczeniowa jest wyższa/szybsza niż szybkość przesyłania danych między pamięcią a SM, SM będzie cierpieć z powodu braku danych do przetworzenia, w związku z czym obliczenia będą niewykorzystane. Ta sytuacja, w której przepustowość pamięci jest mniejsza niż szybkość zużycia, nazywana jest fazą związaną z pamięcią . Należy o tym pamiętać, ponieważ jest to najczęstsze wąskie gardło w procesie wnioskowania.
I odwrotnie, jeśli przetwarzanie zajmuje więcej czasu i więcej danych znajduje się w kolejce do obliczeń, ten stan jest fazą związaną z obliczeniami .
Aby w pełni wykorzystać możliwości procesora graficznego, musimy znajdować się w stanie związanym z obliczeniami, jednocześnie wykonując wykonywane obliczenia tak efektywnie, jak to możliwe.
Pamięć DRAM
DRAM pełni funkcję pamięci podstawowej w procesorze graficznym, zapewniając dużą pulę pamięci do przechowywania danych i instrukcji potrzebnych do obliczeń. Zwykle jest zorganizowany w sposób hierarchiczny, z wieloma bankami pamięci i kanałami, aby umożliwić szybki dostęp.

W przypadku zadania wnioskowania pamięć DRAM procesora graficznego określa, jak duży model możemy załadować, a obliczone FLOPS i przepustowość określają przepustowość, jaką możemy uzyskać.
Porównanie kart GPU do zadań LLM
Aby uzyskać informacje na temat liczby rdzeni tensorowych i szybkości pasma, można zapoznać się z oficjalnym dokumentem wydanym przez producenta karty graficznej. Oto przykład,
| RTX-a6000 | RTX4090 | RTX-a 3090 | |
| Rozmiar pamięci | 48 GB | 24 GB | 24 GB |
| Typ pamięci | GDDR6 | GDDR6X | |
| Przepustowość łącza | 768,0 GB/s | 1008 GB/sek | 936,2 GB/s |
| Rdzenie CUDA/GPU | 10752 | 16384 | 10496 |
| Rdzenie Tensorowe | 336 | 512 | 328 |
| Pamięć podręczna L1 | 128 KB (na SM) | 128 KB (na SM) | 128 KB (na SM) |
| FP16 Bez tensora | 38,71 TFLOPS (1:1) | 82,6 | 35,58 TFLOPS (1:1) |
| FP32 bez tensora | 38,71 TFLOPS | 82,6 | 35,58 TFLOPSÓW |
| FP64 bez tensora | 1210 GFLOPSów (1:32) | 556,0 GFLOPS (1:64) | |
| Szczytowy TFLOPS tensora FP16 z akumulacją FP16 | 154,8/309,6 | 330,3/660,6 | 142/284 |
| Szczytowy TFLOPS tensora FP16 z akumulacją FP32 | 154,8/309,6 | 165,2/330,4 | 71/142 |
| Szczytowy TFLOPS tensora BF16 z FP32 | 154,8/309,6 | 165,2/330,4 | 71/142 |
| Szczytowy TFLOPS tensora TF32 | 77,4/154,8 | 82,6/165,2 | 35,6/71 |
| Szczytowe TOPS Tensora INT8 | 309,7/619,4 | 660,6/1321,2 | 284/568 |
| Szczytowe TOPS Tensora INT4 | 619,3/1238,6 | 1321,2/2642,4 | 568/1136 |
| Pamięć podręczna L2 | 6 MB | 72MB | 6 MB |
| Autobus pamięci | 384-bitowy | 384-bitowy | 384-bitowy |
| TMU | 336 | 512 | 328 |
| ROP | 112 | 176 | 112 |
| Liczba SM | 84 | 128 | 82 |
| Rdzenie RT | 84 | 128 | 82 |
Tutaj widzimy, że FLOPS jest specjalnie wspomniany dla operacji Tensor, dane te pomogą nam porównać różne karty GPU i wybrać odpowiednią dla naszego przypadku użycia. Z tabeli wynika, że chociaż A6000 ma dwukrotnie większą pamięć niż 4090, flopy tensore i przepustowość pamięci 4090 są lepsze liczbowo, a tym samym skuteczniejsze w przypadku wnioskowania z dużych modeli językowych.
Czytaj dalej: Nvidia CUDA w 100 sekund
Wniosek
W szybko rozwijającej się dziedzinie NLP optymalizacja modeli wielkojęzykowych (LLM) pod kątem zadań wnioskowania stała się kluczowym obszarem zainteresowania. Jak już ustaliliśmy, architektura procesorów graficznych odgrywa kluczową rolę w osiąganiu wysokiej wydajności i efektywności w tych zadaniach. Zrozumienie wewnętrznych komponentów procesorów graficznych, takich jak wieloprocesory strumieniowe (SM), pamięć podręczna L2, przepustowość pamięci i DRAM, jest niezbędne do zidentyfikowania potencjalnych wąskich gardeł w procesach wnioskowania LLM.
Porównanie różnych kart graficznych NVIDIA — RTX A6000, RTX 4090 i RTX 3090 — ujawnia znaczące różnice, między innymi pod względem rozmiaru pamięci, przepustowości oraz liczby rdzeni CUDA i Tensor. Te rozróżnienia są kluczowe dla podejmowania świadomych decyzji dotyczących tego, który procesor graficzny najlepiej nadaje się do konkretnych zadań LLM. Na przykład, podczas gdy RTX A6000 oferuje większy rozmiar pamięci, RTX 4090 wyróżnia się pod względem Tensor FLOPS i przepustowości pamięci, co czyni go lepszym wyborem dla wymagających zadań wnioskowania LLM.
Optymalizacja wnioskowania LLM wymaga zrównoważonego podejścia, które uwzględnia zarówno moc obliczeniową procesora graficznego, jak i specyficzne wymagania danego zadania LLM. Wybór odpowiedniego procesora graficznego wymaga zrozumienia kompromisów pomiędzy pojemnością pamięci, mocą obliczeniową i przepustowością, aby mieć pewność, że procesor graficzny będzie w stanie efektywnie obsługiwać obciążenia modelu i wykonywać obliczenia, nie tworząc wąskiego gardła. Ponieważ dziedzina NLP stale ewoluuje, bycie na bieżąco z najnowszymi technologiami GPU i ich możliwościami będzie najważniejsze dla tych, którzy chcą przesuwać granice tego, co jest możliwe dzięki modelom wielkojęzykowym.
Używana terminologia
- Wydajność:
W przypadku wnioskowania przepustowość jest miarą liczby żądań/podpowiedzi przetwarzanych w danym okresie czasu. Przepustowość jest zwykle mierzona na dwa sposoby:
- Żądania na sekundę (RPS) :
- RPS mierzy liczbę żądań wnioskowania, które model może obsłużyć w ciągu sekundy. Żądanie wnioskowania zazwyczaj obejmuje wygenerowanie odpowiedzi lub prognozy na podstawie danych wejściowych.
- W przypadku generowania LLM RPS wskazuje, jak szybko model może reagować na przychodzące monity lub zapytania. Wyższe wartości RPS sugerują lepszą responsywność i skalowalność w przypadku aplikacji czasu rzeczywistego lub prawie rzeczywistego.
- Osiągnięcie wysokich wartości RPS często wymaga skutecznych strategii wdrażania, takich jak grupowanie wielu żądań w celu amortyzacji kosztów ogólnych i maksymalizacji wykorzystania zasobów obliczeniowych.
- Tokeny na sekundę (TPS) :
- TPS mierzy prędkość, z jaką model może przetwarzać i generować tokeny (słowa lub słowa podrzędne) podczas generowania tekstu.
- W kontekście generowania LLM TPS odzwierciedla przepustowość modelu w zakresie generowania tekstu. Wskazuje, jak szybko model może generować spójne i znaczące odpowiedzi.
- Wyższe wartości TPS oznaczają szybsze generowanie tekstu, umożliwiając modelowi przetworzenie większej ilości danych wejściowych i wygenerowanie dłuższych odpowiedzi w określonym czasie.
- Osiąganie wysokich wartości TPS często wiąże się z optymalizacją architektury modelu, równoległością obliczeń i wykorzystaniem akceleratorów sprzętowych, takich jak procesory graficzne, w celu przyspieszenia generowania tokenów.
- Czas oczekiwania:
Opóźnienie w LLM odnosi się do opóźnienia czasowego między wejściem a wyjściem podczas wnioskowania. Minimalizacja opóźnień jest niezbędna do poprawy komfortu użytkownika i umożliwienia interakcji w czasie rzeczywistym w aplikacjach wykorzystujących LLM. Istotne jest znalezienie równowagi pomiędzy przepustowością a opóźnieniami w zależności od usługi, którą musimy świadczyć. Małe opóźnienia są pożądane w przypadku chatbotów/drugiego pilota interakcji w czasie rzeczywistym, ale nie są konieczne w przypadkach masowego przetwarzania danych, takich jak ponowne przetwarzanie danych wewnętrznych.
Przeczytaj więcej na temat zaawansowanych technik zwiększania przepustowości LLM tutaj.