
Jak przesyłać dane do BigQuery za pomocą R i Pythona
Opublikowany: 2023-06-06Świat analityki internetowej wciąż zmierza ku fatalnej dacie 1 lipca, kiedy Universal Analytics przestanie przetwarzać dane i zostanie zastąpiony przez Google Analytics 4 (GA4). Jedną z kluczowych zmian jest to, że w GA4 dane można przechowywać na platformie maksymalnie przez 14 miesięcy. Jest to duża zmiana w stosunku do UA, ale w zamian możesz przesyłać dane GA4 do BigQuery za darmo, do pewnego limitu.
BigQuery to niezwykle przydatne źródło przechowywania danych poza GA4. Ponieważ w ciągu kilku miesięcy staje się ważniejszy niż kiedykolwiek, jest to dobry moment, aby zacząć go używać do wszystkich potrzeb związanych z przechowywaniem danych. Często lepiej będzie zmodyfikować dane w jakiś sposób przed przesłaniem. W tym celu zalecamy użycie skryptu napisanego w języku R lub Python, zwłaszcza jeśli tego rodzaju manipulacje muszą być wykonywane wielokrotnie. Możesz także przesyłać dane do BigQuery bezpośrednio z tych skryptów i dokładnie przez to przeprowadzi Cię ten blog.
Przesyłanie do BigQuery z R
R to niezwykle potężny język do analizy danych i najłatwiejszy w obsłudze przy przesyłaniu danych do BigQuery. Pierwszym krokiem jest zaimportowanie wszystkich niezbędnych bibliotek. Do tego samouczka będziemy potrzebować następujących bibliotek:
library(googleAuthR)
library(bigQueryR)
Jeśli wcześniej nie używałeś tych bibliotek, uruchom install.packages(<PACKAGE NAME>) w konsoli, aby je zainstalować.
Następnie musimy zająć się tym, co jest często najtrudniejszą i najbardziej frustrującą częścią pracy z interfejsami API – autoryzacją. Na szczęście w R jest to stosunkowo proste. Będziesz potrzebował pliku JSON zawierającego dane uwierzytelniające. Można to znaleźć w Google Cloud Console, w tym samym miejscu, w którym znajduje się BigQuery. Najpierw przejdź do Google Cloud Console i kliknij „Interfejsy API i usługi”.
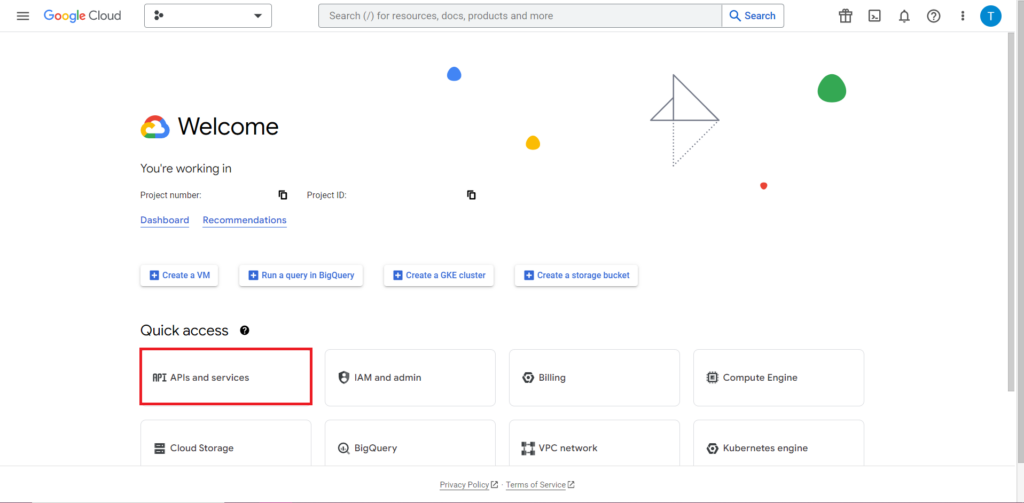
Następnie kliknij „Poświadczenia” na pasku bocznym.
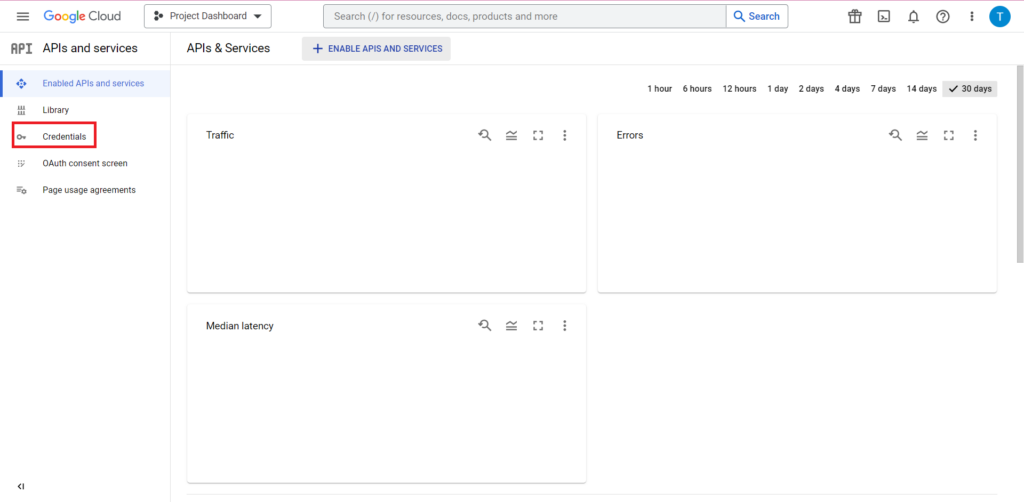
Na stronie Poświadczenia możesz wyświetlić istniejące klucze API, identyfikatory klientów OAuth 2.0 i konta usług. Będziesz potrzebował do tego identyfikatora klienta OAuth 2.0, więc albo naciśnij przycisk pobierania na samym końcu odpowiedniego wiersza swojego identyfikatora, albo utwórz nowy identyfikator, klikając „Utwórz dane uwierzytelniające” u góry strony. Upewnij się, że Twój identyfikator ma uprawnienia do wyświetlania i edytowania odpowiedniego projektu BigQuery – w tym celu otwórz pasek boczny, najedź kursorem na „IAM i Admin” i kliknij „IAM”. Na tej stronie możesz przyznać swojemu kontu usługi dostęp do odpowiedniego projektu, używając przycisku „Udziel dostępu” u góry strony.
Po uzyskaniu i zapisaniu pliku JSON możesz przekazać do niego ścieżkę za pomocą funkcji gar_set_client(), aby ustawić swoje dane uwierzytelniające. Pełny kod autoryzacji znajduje się poniżej:
googleAuthR::gar_cache_empty()
googleAuthR::gar_set_client("C:\\Users\\Tom Brown\\Documents\\R\\APIs\\credentials.json")
bqr_auth(email = "<your email here>")
Oczywiście będziesz chciał zastąpić ścieżkę w funkcji gar_set_client() ścieżką do własnego pliku JSON i wstawić adres e-mail, którego używasz do uzyskiwania dostępu do BigQuery, do funkcji bqr_auth().
Po skonfigurowaniu autoryzacji potrzebujemy trochę danych do przesłania do BigQuery. Będziemy musieli umieścić te dane w ramce danych. Na potrzeby tego artykułu stworzę fikcyjne dane z liczbą lokalizacji i liczbami sprzedaży, ale najprawdopodobniej będziesz odczytywać prawdziwe dane z pliku .csv lub arkusza kalkulacyjnego. Aby odczytać dane z pliku .csv, możesz po prostu użyć funkcji read.csv(), przekazując jako argument ścieżkę do pliku:
data <- read.csv("C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv")
Alternatywnie, jeśli masz dane przechowywane w arkuszu kalkulacyjnym, Twoja metoda będzie się różnić w zależności od tego, gdzie znajduje się ten arkusz kalkulacyjny. Jeśli Twój arkusz kalkulacyjny jest przechowywany w Arkuszach Google, możesz wczytać jego dane do R, korzystając z biblioteki googlesheets4:
library(googlesheets4)
data <- read_sheet(ss=”<spreadsheet URL>”, sheet=”<name of tab>”)
Tak jak poprzednio, jeśli wcześniej nie korzystałeś z tego pakietu, przed uruchomieniem kodu musisz uruchomić w konsoli install.packages(“googlesheets4”).
Jeśli twój arkusz kalkulacyjny znajduje się w Excelu, będziesz musiał użyć biblioteki readxl, która jest częścią biblioteki tidyverse – coś, czego polecam używać. Zawiera ogromną liczbę funkcji, które znacznie ułatwiają manipulację danymi w R:
library(tidyverse)
data <- read_excel(“C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx”)
I jeszcze raz, upewnij się, że uruchomiłeś install.package("tidyverse"), jeśli jeszcze tego nie zrobiłeś!
Ostatnim krokiem jest przesłanie danych do BigQuery. W tym celu potrzebujesz miejsca w BigQuery, aby go przesłać. Twoja tabela będzie znajdować się w zbiorze danych, który będzie znajdować się w projekcie, i będziesz potrzebować nazw wszystkich trzech z nich w następującym formacie:
bqr_upload_data(“<your project>”, “<your dataset>”, “<your table>”, <your dataframe>)
W moim przypadku oznacza to, że mój kod brzmi:
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data)
Jeśli Twoja tabela jeszcze nie istnieje, nie martw się, kod utworzy ją za Ciebie. Nie zapomnij wstawić nazw swojego projektu, zbioru danych i tabeli do powyższego kodu (w cudzysłowach) i upewnić się, że przesyłasz poprawną ramkę danych! Gdy to zrobisz, powinieneś zobaczyć swoje dane w BigQuery, jak poniżej:

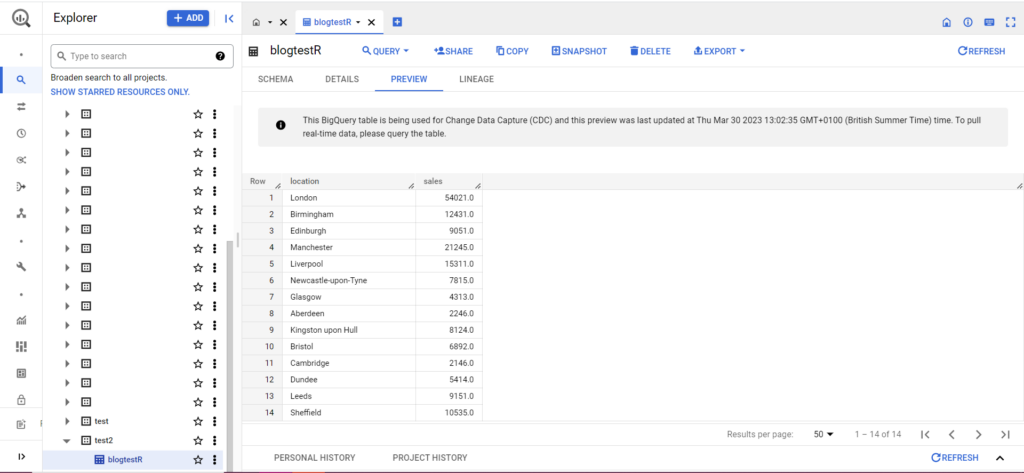
Na koniec załóżmy, że masz dodatkowe dane, które chcesz dodać do BigQuery. Załóżmy na przykład, że w powyższych danych zapomniałem podać kilka lokalizacji z kontynentu i chcę przesłać dane do BigQuery, ale nie chcę nadpisywać istniejących danych. W tym celu bqr_upload_data ma parametr o nazwie writeDisposition. writeDisposition ma dwa ustawienia, „WRITE_TRUNCATE” i „WRITE_APPEND”. Pierwsza mówi bqr_upload_data(), aby nadpisała istniejące dane w tabeli, podczas gdy druga mówi jej, aby dołączyła nowe dane. Tak więc, aby przesłać te nowe dane, napiszę:
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data2, writeDisposition = “WRITE_APPEND”))
I rzeczywiście, w BigQuery możemy zobaczyć, że nasze dane mają nowych współlokatorów:
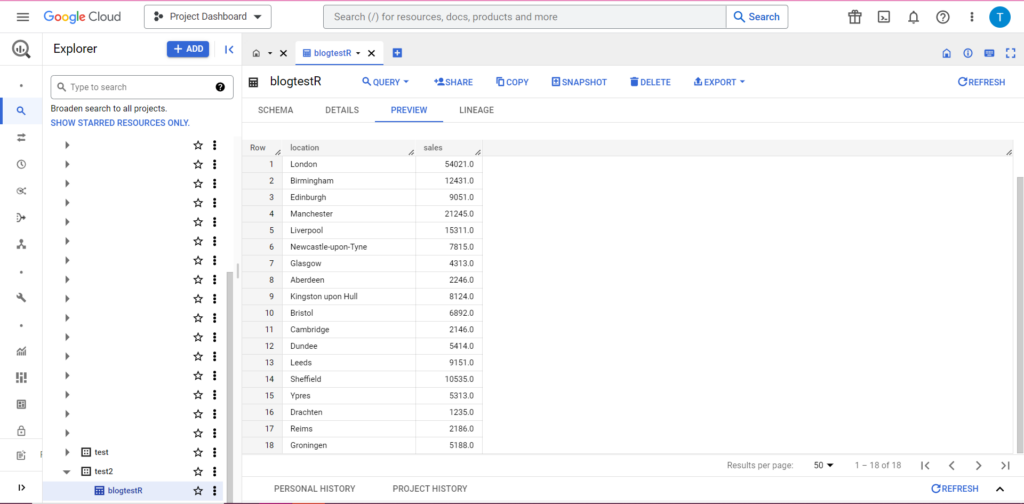
Przesyłanie do BigQuery z Pythona
W Pythonie sytuacja wygląda trochę inaczej. Ponownie będziemy musieli zaimportować niektóre pakiety, więc zacznijmy od tych:
import pandas as pd
from google.cloud import bigquery
from google.oauth2 import service_account
Autoryzacja jest skomplikowana. Ponownie będziemy potrzebować pliku JSON zawierającego poświadczenia. Jak wyżej, przejdziemy do Google Cloud Console i klikniemy „Interfejsy API i usługi”, a następnie klikniemy „Poświadczenia” na pasku bocznym. Tym razem na dole strony pojawi się sekcja o nazwie „Konta serwisowe”.
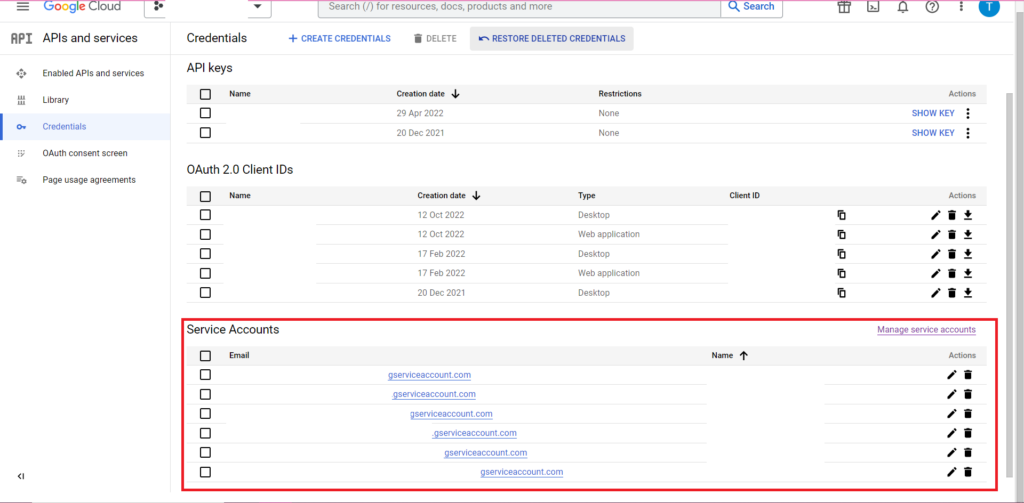
Tam możesz pobrać klucz do swojego konta usługi lub klikając „Zarządzaj kontem usługi” możesz utworzyć nowy klucz lub nowe konto usługi, dla którego możesz pobrać dane uwierzytelniające.
Następnie upewnij się, że Twoje konto usługi ma uprawnienia dostępu do Twojego projektu BigQuery i edytowania go. Ponownie przejdź do strony IAM w sekcji „IAM i administrator” na pasku bocznym, gdzie możesz przyznać swojemu kontu usługi dostęp do odpowiedniego projektu za pomocą przycisku „Udziel dostępu” u góry strony.
Gdy tylko to załatwisz, możesz wpisać kod autoryzacyjny:
bqcreds = service_account.Credentials.from_service_account_file('myjson.json', scopes = ['https://www.googleapis.com/auth/cloud-platform'])
client = bigquery.Client(credentials=bqcreds, project=bqcreds.project_id,)
Następnie musisz umieścić swoje dane w ramce danych. Ramki danych należą do pakietu pandas i są bardzo proste do utworzenia. Aby wczytać plik CSV, postępuj zgodnie z tym przykładem:
data = pd.read_csv('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv')
Oczywiście musisz zastąpić powyższą ścieżkę ścieżką do własnego pliku CSV. Aby wczytać z pliku programu Excel, postępuj zgodnie z tym przykładem:
data = pd.read_excel('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx', sheet_name='mytab'>
Wczytywanie z Arkuszy Google jest trudne i wymaga kolejnej rundy autoryzacji. Będziemy musieli zaimportować kilka nowych pakietów i użyć pliku poświadczeń JSON, który pobraliśmy podczas powyższego samouczka języka R. Możesz użyć tego kodu, aby autoryzować i odczytać swoje dane:
import gspread
from oauth2client.service_account import ServiceAccountCredentials
credentials = ServiceAccountCredentials.from_json_keyfile_name('myjson.json', scopes = ['https://spreadsheets.google.com/feeds'])
gc = gspead.authorize(credentials)
ss = gc.open_by_key('<spreadsheet key>')
sheet = ss.worksheet('<name of tab>')
data = pd.DataFrame(sheet.get_all_records())
Gdy masz już dane w ramce danych, nadszedł czas, aby ponownie przesłać je do BigQuery! Możesz to zrobić, korzystając z tego szablonu:
table_id = “<your project>.<your dataset>.<your table>”
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
Na przykład, oto kod, który właśnie napisałem, aby przesłać dane, które zrobiłem wcześniej:
table_
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
Po wykonaniu tej czynności dane powinny natychmiast pojawić się w BigQuery!
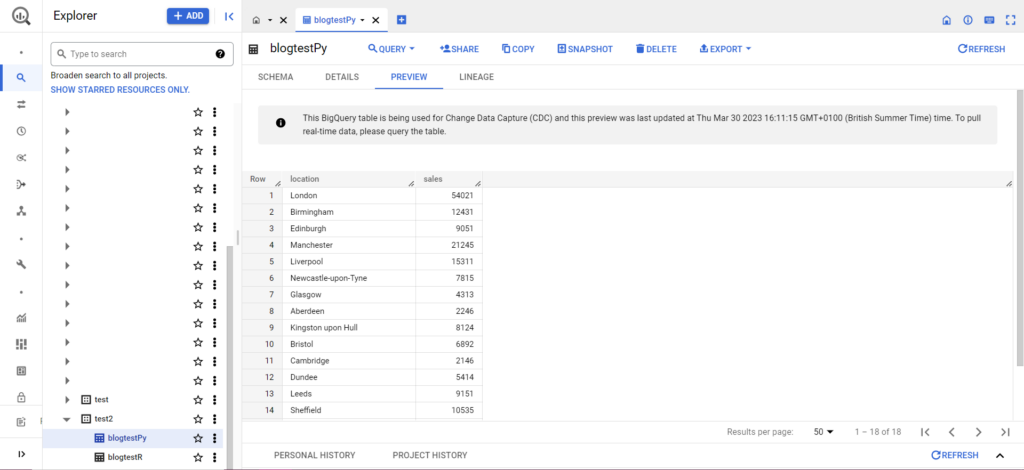
Jest o wiele więcej rzeczy, które możesz zrobić z tymi funkcjami, gdy już je opanujesz. Jeśli chcesz przejąć większą kontrolę nad konfiguracją analityki, Semetrical jest tutaj, aby Ci pomóc! Sprawdź nasz blog, aby uzyskać więcej informacji o tym, jak najlepiej wykorzystać swoje dane. Lub, aby uzyskać więcej pomocy w zakresie wszystkich zagadnień analitycznych, przejdź do usługi Web Analytics, aby dowiedzieć się, jak możemy Ci pomóc.