
Roboty indeksujące — kompletny przewodnik
Opublikowany: 2023-12-12Przeszukiwanie sieci
Przeszukiwanie sieci, podstawowy proces w dziedzinie indeksowania sieci i technologii wyszukiwarek, odnosi się do automatycznego przeglądania sieci WWW przez program znany jako przeszukiwacz sieci. Te roboty indeksujące, czasami nazywane pająkami lub botami, systematycznie poruszają się po Internecie w celu gromadzenia informacji ze stron internetowych. Proces ten umożliwia gromadzenie i indeksowanie danych, co jest kluczowe, aby wyszukiwarki dostarczały aktualne i trafne wyniki wyszukiwania.
Kluczowe funkcje indeksowania sieci:
- Indeksowanie treści : roboty indeksujące skanują strony internetowe i indeksują ich zawartość, umożliwiając jej przeszukiwanie. Ten proces indeksowania obejmuje analizę tekstu, obrazów i innej zawartości strony w celu zrozumienia jej tematyki.
- Analiza linków : Roboty śledzą linki z jednej strony internetowej na drugą. Pomaga to nie tylko w odkrywaniu nowych stron internetowych, ale także w zrozumieniu relacji i hierarchii pomiędzy różnymi stronami internetowymi.
- Wykrywanie aktualizacji treści : regularnie odwiedzając strony internetowe, roboty indeksujące mogą wykryć aktualizacje i zmiany, zapewniając aktualność zaindeksowanej treści.
Nasz przewodnik krok po kroku dotyczący tworzenia robota sieciowego pomoże Ci lepiej zrozumieć proces przeszukiwania sieci.
Co to jest przeszukiwacz sieci
Robot sieciowy, znany również jako pająk lub bot, to zautomatyzowany program, który systematycznie przegląda sieć WWW w celu indeksowania sieci. Jego podstawową funkcją jest skanowanie i indeksowanie zawartości stron internetowych, która obejmuje tekst, obrazy i inne multimedia. Roboty indeksujące rozpoczynają pracę od znanego zestawu stron internetowych i podążają za łączami na tych stronach, aby odkryć nowe strony, zachowując się podobnie jak osoba przeglądająca Internet. Proces ten pozwala wyszukiwarkom gromadzić i aktualizować swoje dane, zapewniając użytkownikom aktualne i kompleksowe wyniki wyszukiwania. Sprawne działanie robotów indeksujących jest niezbędne do utrzymania ogromnego i stale rosnącego repozytorium informacji online dostępnych i możliwych do przeszukiwania.
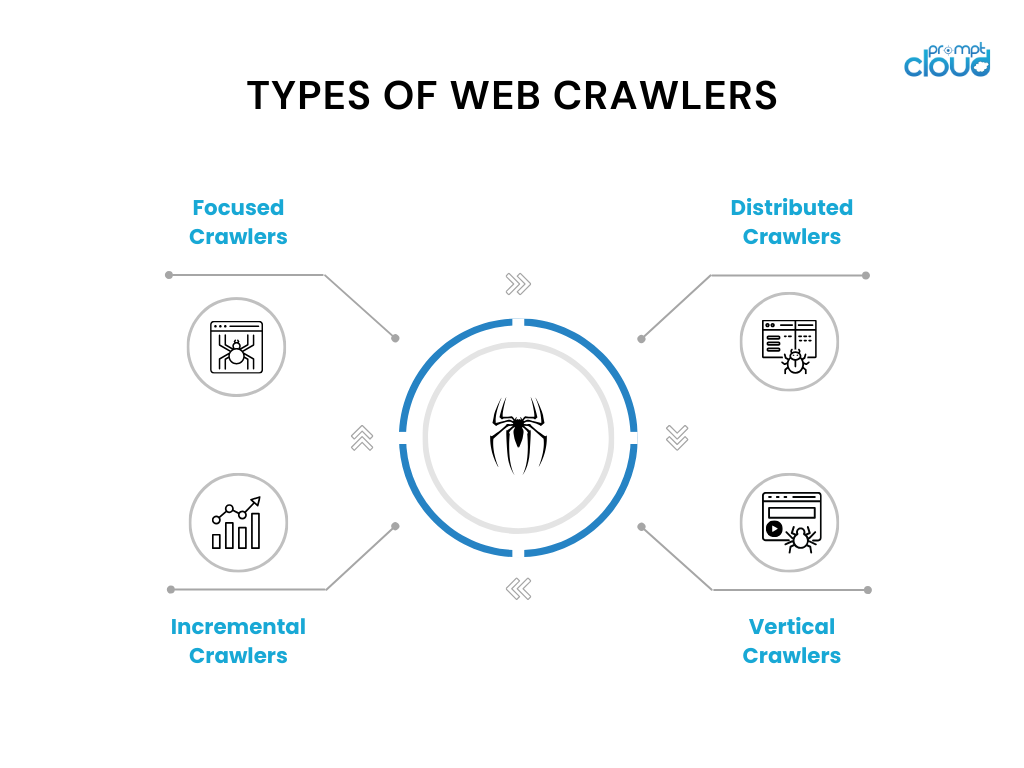
Jak działa przeszukiwacz sieci
Roboty indeksujące działają poprzez systematyczne przeglądanie Internetu w celu gromadzenia i indeksowania treści witryn internetowych, co jest procesem kluczowym dla wyszukiwarek. Zaczynają od zestawu znanych adresów URL i uzyskują dostęp do tych stron internetowych w celu pobrania treści. Analizując strony, identyfikują wszystkie hiperłącza i dodają je do listy adresów URL, które należy odwiedzić w następnej kolejności, skutecznie odwzorowując strukturę sieci. Każda odwiedzana strona jest przetwarzana w celu wyodrębnienia odpowiednich informacji, takich jak tekst, obrazy i metadane, które następnie są przechowywane w bazie danych. Dane te stają się podstawą indeksu wyszukiwarki, umożliwiając jej szybkie i trafne wyniki wyszukiwania.
Roboty indeksujące muszą działać w ramach pewnych ograniczeń, takich jak przestrzeganie zasad określonych w plikach robots.txt przez właścicieli witryn internetowych i unikanie przeciążania serwerów, zapewniając w ten sposób etyczny i wydajny proces indeksowania. Poruszając się po miliardach stron internetowych, roboty te stają przed wyzwaniami, takimi jak obsługa zawartości dynamicznej, zarządzanie zduplikowanymi stronami i bycie na bieżąco z najnowszymi technologiami internetowymi, co sprawia, że ich rola w ekosystemie cyfrowym jest zarówno złożona, jak i niezastąpiona. Oto szczegółowy artykuł na temat działania robotów indeksujących.
Przeszukiwacz sieciowy Python
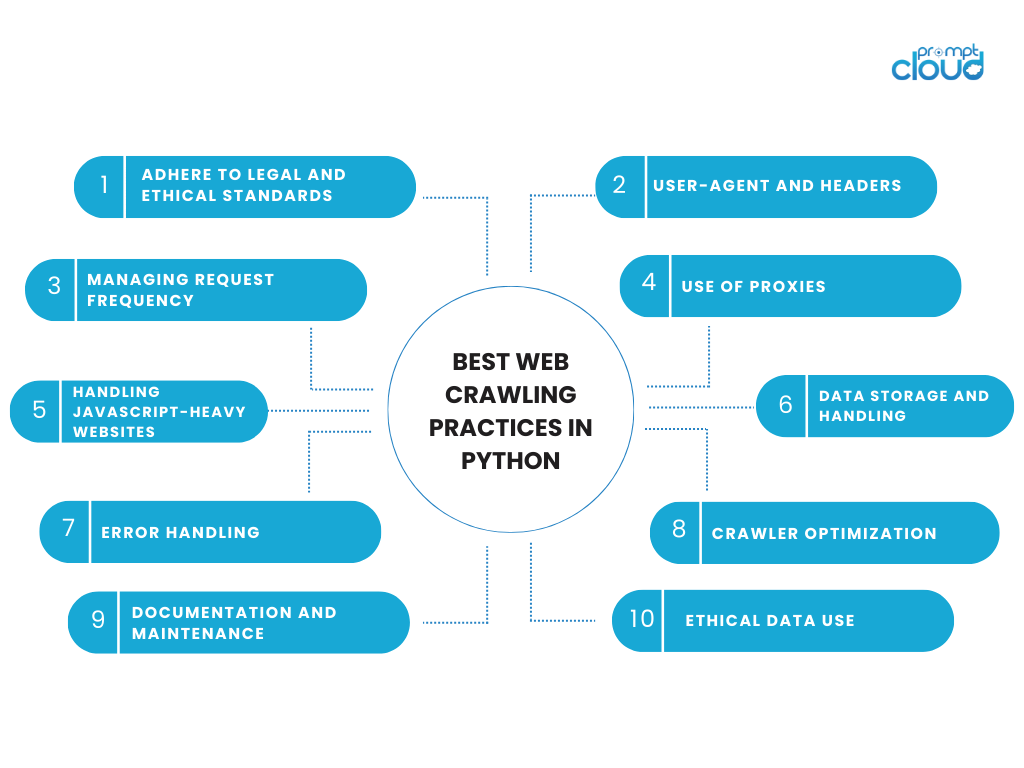
Python, znany ze swojej prostoty i czytelności, jest idealnym językiem programowania do tworzenia robotów indeksujących. Bogaty ekosystem bibliotek i frameworków upraszcza proces pisania skryptów, które nawigują, analizują i wyodrębniają dane z Internetu. Oto kluczowe aspekty, które sprawiają, że Python jest najczęściej wybieranym wyborem do przeszukiwania sieci:
Kluczowe biblioteki Pythona do przeszukiwania sieci:
- Żądania : ta biblioteka służy do wysyłania żądań HTTP do stron internetowych. Jest prosty w użyciu i może obsługiwać różnego rodzaju żądania, niezbędne do uzyskania dostępu do zawartości strony internetowej.
- Beautiful Soup : Specjalizująca się w analizowaniu dokumentów HTML i XML, Beautiful Soup pozwala na łatwe wyodrębnianie danych ze stron internetowych, ułatwiając poruszanie się po strukturze znaczników dokumentu.
- Scrapy : platforma do przeszukiwania sieci o otwartym kodzie źródłowym. Scrapy zapewnia kompletny pakiet do pisania przeszukiwaczy sieci. Bezproblemowo obsługuje żądania, analizowanie odpowiedzi i ekstrakcję danych.
Zalety używania języka Python do przeszukiwania sieci:
- Łatwość użycia : Prosta składnia języka Python sprawia, że jest on dostępny nawet dla początkujących programistów.
- Solidne wsparcie społeczności : duża społeczność i bogata dokumentacja pomagają w rozwiązywaniu problemów i ulepszaniu funkcjonalności robota.
- Elastyczność i skalowalność : roboty indeksujące Python mogą być tak proste lub tak złożone, jak potrzeba, skalując się od małych do dużych projektów.
Przykład podstawowego robota sieciowego w języku Python:
żądania importu

z bs4 importuj BeautifulSoup
# Zdefiniuj adres URL do przeszukania
url = „http://example.com”
# Wyślij żądanie HTTP na adres URL
odpowiedź = żądania.get(url)
# Przeanalizuj zawartość HTML strony
zupa = BeautifulSoup(response.text, 'html.parser')
# Wyodrębnij i wydrukuj wszystkie hiperłącza
dla linku w zupie.find_all('a'):
print(link.get('href'))
Ten prosty skrypt demonstruje podstawowe działanie przeszukiwacza sieciowego w języku Python. Pobiera zawartość HTML strony internetowej za pomocą żądań, analizuje ją za pomocą Beautiful Soup i wyodrębnia wszystkie hiperłącza.
Roboty indeksujące Python wyróżniają się łatwością programowania i wydajnością ekstrakcji danych.
Niezależnie od tego, czy chodzi o analizę SEO, eksplorację danych czy marketing cyfrowy, Python zapewnia solidną i elastyczną podstawę do zadań związanych z przeszukiwaniem sieci, co czyni go doskonałym wyborem zarówno dla programistów, jak i analityków danych.
Przypadki użycia indeksowania sieci
Przeszukiwanie sieci ma szeroki zakres zastosowań w różnych branżach, co odzwierciedla jego wszechstronność i znaczenie w epoce cyfrowej. Oto niektóre z kluczowych przypadków użycia:
Indeksowanie w wyszukiwarkach
Najbardziej znanym zastosowaniem robotów indeksujących są wyszukiwarki takie jak Google, Bing i Yahoo, służące do tworzenia indeksów sieciowych z możliwością przeszukiwania. Roboty indeksujące skanują strony internetowe, indeksują ich zawartość i oceniają je na podstawie różnych algorytmów, dzięki czemu użytkownicy mogą je przeszukiwać.
Eksploracja i analiza danych
Firmy korzystają z robotów indeksujących w celu gromadzenia danych na temat trendów rynkowych, preferencji konsumentów i konkurencji. Naukowcy wykorzystują roboty indeksujące do agregowania danych z wielu źródeł na potrzeby badań akademickich.
Monitorowanie SEO
Webmasterzy korzystają z robotów indeksujących, aby zrozumieć, w jaki sposób wyszukiwarki przeglądają ich witryny, co pomaga w optymalizacji struktury, zawartości i wydajności witryny. Wykorzystuje się je również do analizy witryn konkurencji w celu zrozumienia ich strategii SEO.
Agregacja treści
Roboty indeksujące są wykorzystywane przez platformy agregujące wiadomości i treści do gromadzenia artykułów i informacji z różnych źródeł. Agregowanie treści z platform mediów społecznościowych w celu śledzenia trendów, popularnych tematów lub konkretnych wzmianek.
Handel elektroniczny i porównanie cen
Roboty indeksujące pomagają śledzić ceny produktów na różnych platformach handlu elektronicznego, pomagając w tworzeniu konkurencyjnych strategii cenowych. Służą również do katalogowania produktów z różnych witryn e-commerce w jedną platformę.
Wykazy nieruchomości
Roboty indeksujące zbierają oferty nieruchomości z różnych witryn poświęconych nieruchomościom, aby zapewnić użytkownikom skonsolidowany obraz rynku.
Oferty pracy i rekrutacja
Agregowanie ofert pracy z różnych stron internetowych w celu zapewnienia kompleksowej platformy wyszukiwania ofert pracy. Niektórzy rekruterzy używają robotów indeksujących do przeszukiwania sieci w poszukiwaniu potencjalnych kandydatów o określonych kwalifikacjach.
Szkolenia z zakresu uczenia maszynowego i sztucznej inteligencji
Roboty indeksujące mogą gromadzić ogromne ilości danych z Internetu, które można wykorzystać do uczenia modeli uczenia maszynowego w różnych aplikacjach.
Skrobanie sieci a indeksowanie sieci
Przeszukiwanie sieci i przeszukiwanie sieci to dwie techniki powszechnie stosowane w gromadzeniu danych ze stron internetowych, ale służą różnym celom i działają na różne sposoby. Zrozumienie różnic jest kluczowe dla każdego, kto zajmuje się ekstrakcją danych lub analizą sieci.
Skrobanie sieci
- Definicja : Skrobanie sieci to proces wydobywania określonych danych ze stron internetowych. Koncentruje się na przekształcaniu nieustrukturyzowanych danych internetowych (zwykle w formacie HTML) w ustrukturyzowane dane, które można przechowywać i analizować.
- Ukierunkowana ekstrakcja danych : Scraping jest często używany do zbierania określonych informacji ze stron internetowych, takich jak ceny produktów, dane giełdowe, artykuły prasowe, dane kontaktowe itp.
- Narzędzia i techniki : obejmuje użycie narzędzi lub programowania (często Python, PHP, JavaScript) w celu wywołania strony internetowej, przeanalizowania zawartości HTML i wyodrębnienia żądanych informacji.
- Przypadki użycia : badania rynku, monitorowanie cen, generowanie leadów, dane do modeli uczenia maszynowego itp.
Przeszukiwanie sieci
- Definicja : Z drugiej strony przeszukiwanie sieci to proces systematycznego przeglądania sieci w celu pobrania i indeksowania treści internetowych. Jest to kojarzone przede wszystkim z wyszukiwarkami.
- Indeksowanie i śledzenie linków : Roboty indeksujące, czyli pająki, są wykorzystywane do odwiedzania szerokiej gamy stron w celu zrozumienia struktury witryny i powiązań. Zwykle indeksują całą zawartość strony.
- Automatyzacja i skala : indeksowanie sieci jest procesem bardziej zautomatyzowanym, umożliwiającym ekstrakcję danych na dużą skalę z wielu stron internetowych lub całych witryn internetowych.
- Uwagi : Roboty indeksujące muszą przestrzegać zasad określonych przez witryny internetowe, np. te zawarte w plikach robots.txt, i są zaprojektowane tak, aby nawigować bez przeciążania serwerów internetowych.
Narzędzia do przeszukiwania sieci
Narzędzia do przeszukiwania sieci to niezbędne instrumenty w cyfrowym zestawie narzędzi firm, badaczy i programistów, oferujące sposób na automatyzację gromadzenia danych z różnych witryn internetowych. Narzędzia te służą do systematycznego przeglądania stron internetowych, wydobywania przydatnych informacji i przechowywania ich do późniejszego wykorzystania. Oto przegląd narzędzi do przeszukiwania sieci i ich znaczenia:
Funkcjonalność : Narzędzia do przeszukiwania sieci są zaprogramowane tak, aby nawigować po witrynach internetowych, identyfikować istotne informacje i je pobierać. Naśladują zachowanie człowieka podczas przeglądania, ale robią to na znacznie większą skalę i z większą szybkością.
Wyodrębnianie i indeksowanie danych : narzędzia te analizują dane na stronach internetowych, które mogą zawierać tekst, obrazy, łącza i inne multimedia, a następnie organizują je w ustrukturyzowany format. Jest to szczególnie przydatne przy tworzeniu baz danych zawierających informacje, które można łatwo przeszukiwać i analizować.
Dostosowywanie i elastyczność : wiele narzędzi do przeszukiwania sieci oferuje opcje dostosowywania, pozwalające użytkownikom określić, które witryny mają być przeszukiwane, jak głęboko wnikać w architekturę witryny i jakiego rodzaju dane mają zostać wyodrębnione.
Przypadki użycia : są wykorzystywane do różnych celów, takich jak optymalizacja wyszukiwarek (SEO), badania rynku, agregacja treści, analiza konkurencji i gromadzenie danych na potrzeby projektów uczenia maszynowego.
Nasz najnowszy artykuł zawiera szczegółowy przegląd najpopularniejszych narzędzi do przeszukiwania sieci w roku 2024. Przeczytaj ten artykuł, aby dowiedzieć się więcej. Skontaktuj się z nami pod adresem [email protected], aby uzyskać niestandardowe rozwiązania do przeszukiwania sieci.