
Wyzwania i rozwiązania dotyczące skrobania sieci: poruszanie się po złożonościach
Opublikowany: 2023-09-13Web scraping stał się nieocenioną techniką wydobywania danych ze stron internetowych. Niezależnie od tego, czy potrzebujesz zbierać informacje do celów badawczych, śledzić ceny lub trendy, czy też automatyzować niektóre zadania online, skrobanie sieci może zaoszczędzić czas i wysiłek. Poruszanie się po zawiłościach stron internetowych i radzenie sobie z różnymi wyzwaniami związanymi z przeglądaniem stron internetowych może być trudnym zadaniem. W tym artykule zagłębimy się w uproszczenie procesu skrobania sieci, zdobywając jego kompleksowe zrozumienie. Omówimy poszczególne etapy, wybór odpowiednich narzędzi, identyfikację danych docelowych, poruszanie się po strukturach witryny, obsługę uwierzytelniania i captcha oraz obsługę zawartości dynamicznej.
Zrozumienie skrobania sieci
Web scraping to procedura wydobywania danych ze stron internetowych poprzez analizę i parsowanie kodu HTML i CSS. Obejmuje wysyłanie żądań HTTP do stron internetowych, pobieranie treści HTML, a następnie wyodrębnianie odpowiednich informacji. Chociaż ręczne skrobanie sieci poprzez sprawdzanie kodu źródłowego i kopiowanie danych jest możliwe, jest często nieefektywne i czasochłonne, szczególnie w przypadku gromadzenia dużych ilości danych.
Aby zautomatyzować proces skrobania sieci, można zastosować języki programowania, takie jak Python i biblioteki, takie jak Beautiful Soup lub Selenium, a także dedykowane narzędzia do skrobania sieci, takie jak Scrapy lub Beautiful Soup. Narzędzia te oferują funkcje umożliwiające interakcję ze stronami internetowymi, analizowanie kodu HTML i wydajne wyodrębnianie danych.
Wyzwania związane ze skrobaniem sieci
Wybór odpowiednich narzędzi
Wybór odpowiednich narzędzi ma kluczowe znaczenie dla powodzenia Twojego przedsięwzięcia polegającego na skrobaniu stron internetowych. Oto kilka kwestii, które należy wziąć pod uwagę przy wyborze narzędzi do projektu skrobania stron internetowych:
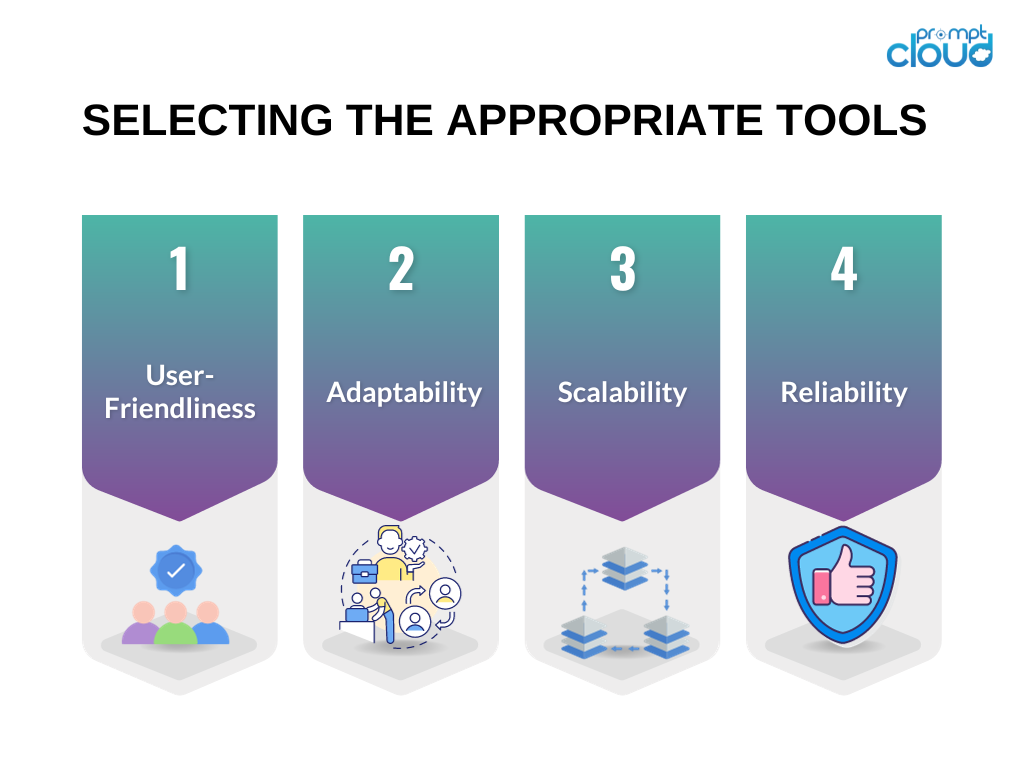
Przyjazność dla użytkownika : traktuj priorytetowo narzędzia z przyjaznymi dla użytkownika interfejsami lub tymi, które zapewniają przejrzystą dokumentację i praktyczne przykłady.
Możliwość adaptacji : wybierz narzędzia zdolne do obsługi różnorodnych typów stron internetowych i dopasowujące się do zmian w strukturze stron internetowych.
Skalowalność : jeśli Twoje zadanie gromadzenia danych obejmuje znaczną ilość danych lub wymaga zaawansowanych możliwości przeglądania stron internetowych, rozważ narzędzia, które poradzą sobie z dużymi wolumenami i oferują funkcje przetwarzania równoległego.
Niezawodność : upewnij się, że narzędzia są przystosowane do zarządzania różnymi typami błędów, takimi jak przekroczenia limitu czasu połączenia lub błędy HTTP, i mają wbudowane mechanizmy obsługi błędów.
W oparciu o te kryteria powszechnie używane narzędzia, takie jak Beautiful Soup i Selenium, są często zalecane do projektów typu web scraping.
Identyfikacja danych docelowych
Przed rozpoczęciem projektu skrobania stron internetowych istotne jest określenie docelowych danych, które chcesz wyodrębnić ze strony internetowej. Mogą to być informacje o produkcie, artykuły prasowe, posty w mediach społecznościowych lub dowolny inny rodzaj treści. Zrozumienie struktury docelowej witryny jest kluczowe dla skutecznego wydobycia pożądanych danych.
Aby zidentyfikować dane docelowe, możesz użyć narzędzi programistycznych przeglądarki, takich jak Chrome DevTools lub Firefox Developer Tools. Narzędzia te pozwalają sprawdzić strukturę HTML strony internetowej, zidentyfikować konkretne elementy zawierające potrzebne dane i zrozumieć selektory CSS lub wyrażenia XPath wymagane do wyodrębnienia tych danych.

Poruszanie się po strukturach serwisu
Strony internetowe mogą mieć złożone struktury z zagnieżdżonymi elementami HTML, dynamiczną zawartością JavaScript lub żądaniami AJAX. Poruszanie się po tych strukturach i wydobywanie odpowiednich informacji wymaga dokładnej analizy i strategii.
Oto kilka technik ułatwiających poruszanie się po skomplikowanych strukturach witryn internetowych:
Używaj selektorów CSS lub wyrażeń XPath : Rozumiejąc strukturę kodu HTML, możesz używać selektorów CSS lub wyrażeń XPath do kierowania na określone elementy i wyodrębniania żądanych danych.
Obsługuj paginację : jeśli dane docelowe są rozproszone na wielu stronach, musisz zaimplementować paginację, aby zeskrobać wszystkie informacje. Można tego dokonać automatyzując proces klikania przycisków „dalej” lub „ładuj więcej” lub konstruując adresy URL o różnych parametrach.
Radź sobie z elementami zagnieżdżonymi : czasami dane docelowe są zagnieżdżone na wielu poziomach elementów HTML. W takich przypadkach należy przeglądać zagnieżdżone elementy, korzystając z relacji rodzic-dziecko lub relacji rodzeństwo, aby wydobyć żądane informacje.
Obsługa uwierzytelniania i Captcha
Niektóre witryny mogą wymagać uwierzytelnienia lub udostępnienia captcha, aby zapobiec automatycznemu skrobaniu. Aby pokonać te wyzwania związane ze skrobaniem sieci, możesz zastosować następujące strategie:
Zarządzanie sesją : Utrzymuj stan sesji za pomocą plików cookie lub tokenów w celu obsługi wymagań uwierzytelniania.
Podszywanie się pod agenta użytkownika : emuluj różnych agentów użytkownika, aby wyglądać jak zwykli użytkownicy i unikać wykrycia.
Usługi rozwiązywania problemów Captcha : skorzystaj z usług stron trzecich, które mogą automatycznie rozwiązywać problemy Captcha w Twoim imieniu.
Pamiętaj, że chociaż uwierzytelnianie i captcha można ominąć, powinieneś upewnić się, że Twoje działania związane z przeglądaniem stron internetowych są zgodne z warunkami korzystania z usługi i ograniczeniami prawnymi witryny.
Radzenie sobie z treścią dynamiczną
Strony internetowe często używają JavaScript do dynamicznego ładowania treści lub pobierania danych za pomocą żądań AJAX. Tradycyjne metody skrobania sieci mogą nie przechwycić tej dynamicznej zawartości. Aby obsłużyć zawartość dynamiczną, rozważ następujące podejścia:
Używaj przeglądarek bezgłowych : narzędzia takie jak Selenium pozwalają programowo kontrolować prawdziwe przeglądarki internetowe i wchodzić w interakcję z dynamiczną zawartością.
Wykorzystaj biblioteki do skrobania stron internetowych : niektóre biblioteki, takie jak Puppeteer lub Scrapy-Splash, obsługują renderowanie JavaScript i dynamiczną ekstrakcję treści.
Korzystając z tych technik, możesz mieć pewność, że będziesz mógł zeskrobać strony internetowe, które w dużym stopniu opierają się na JavaScript do dostarczania treści.
Implementacja obsługi błędów
Skrobanie sieci nie zawsze jest procesem płynnym. Strony internetowe mogą zmieniać swoją strukturę, zwracać błędy lub nakładać ograniczenia na działalność scrapingową. Aby ograniczyć ryzyko związane z wyzwaniami związanymi ze skrobaniem stron internetowych, ważne jest wdrożenie mechanizmów obsługi błędów:
Monitoruj zmiany na stronie internetowej : Regularnie sprawdzaj, czy struktura lub układ strony internetowej uległy zmianie i odpowiednio dostosuj swój kod skrobania.
Mechanizmy ponawiania prób i przekroczenia limitu czasu : zaimplementuj mechanizmy ponawiania prób i przekroczenia limitu czasu, aby sprawnie obsługiwać sporadyczne błędy, takie jak przekroczenia limitu czasu połączenia lub błędy HTTP.
Rejestruj i obsługuj wyjątki : przechwytuj i obsługuj różne typy wyjątków, takie jak błędy analizy lub awarie sieci, aby zapobiec całkowitemu niepowodzeniu procesu skrobania.
Wdrażając techniki obsługi błędów, możesz zapewnić niezawodność i solidność kodu do skrobania sieci.
Streszczenie
Podsumowując, wyzwania związane z web scrapingiem można ułatwić, rozumiejąc proces, wybierając odpowiednie narzędzia, identyfikując dane docelowe, poruszając się po strukturach witryny, obsługując uwierzytelnianie i captcha, radząc sobie z dynamiczną treścią i wdrażając techniki obsługi błędów. Postępując zgodnie z tymi najlepszymi praktykami, możesz przezwyciężyć złożoność przeglądania stron internetowych i skutecznie gromadzić potrzebne dane.