
Scraping danych internetowych w dobie Big Data: możliwości i dylematy etyczne
Opublikowany: 2024-05-29Zbieranie danych internetowych i analiza dużych zbiorów danych
Skrobanie danych internetowych stało się kluczowym mechanizmem gromadzenia danych online. Proces ten obejmuje automatyczne pobieranie informacji ze stron internetowych, przekształcając nieustrukturyzowaną sieć w bogactwo ustrukturyzowanych danych gotowych do analizy.
Źródło obrazu: https://www.sas.com/
Jednocześnie analiza dużych zbiorów danych stworzyła niszę w zakresie rozpoznawalnych wzorców, trendów i spostrzeżeń na podstawie ogromnych zbiorów danych zgromadzonych, często poprzez skrobanie danych internetowych. W miarę jak ogromne ilości danych (około 2,5 biliona bajtów generowanych każdego dnia) stają się coraz bardziej dostępne, synteza skrobania danych internetowych z analizą dużych zbiorów danych otwiera niezliczone możliwości dla przedsiębiorstw, badaczy i decydentów.
Umiejętnie łącząc te możliwości technologiczne, mogą oni czerpać korzyści z podejmowania decyzji w oparciu o dane, pobudzać innowacje w zakresie usług i kształtować strategiczne przedsięwzięcia dostosowane do swoich celów. Niemniej jednak istotne jest przyznanie się do pojawiania się dylematów etycznych wynikających z synergicznego związku między tymi zaawansowanymi narzędziami.
Należy ostrożnie wyznaczyć cienką linię, jeśli chodzi o kluczową równowagę między maksymalizacją wartości danych a ochroną praw osób fizycznych do prywatności, upewniając się, że żaden aspekt nie przesłania drugiego.
Korzyści ze skrobania danych internetowych w projektach Big Data
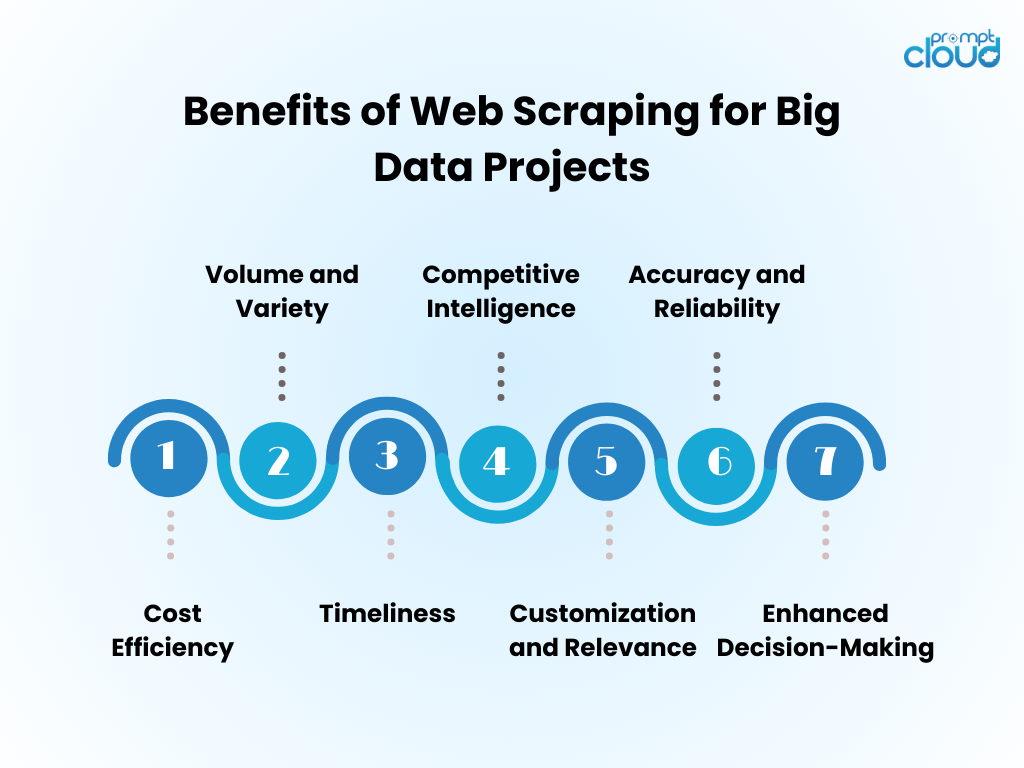
- Efektywność kosztowa : Automatyzacja gromadzenia danych poprzez skanowanie sieci znacznie zmniejsza koszty pracy ludzkiej i skraca czas uzyskania wglądu.
- Objętość i różnorodność : umożliwia przechwytywanie ogromnych ilości danych z różnych źródeł, co ma kluczowe znaczenie dla zasilania analiz dużych zbiorów danych.
- Aktualność : skrobanie sieci zapewnia dane w czasie rzeczywistym lub prawie rzeczywistym, umożliwiając sprawniejsze reagowanie na trendy rynkowe.
- Inteligencja konkurencyjna : umożliwia organizacjom dokładne monitorowanie konkurencji i zmian w branży.
- Dostosowanie i trafność : dane można dostosować do konkretnych potrzeb, zapewniając, że analiza jest istotna i ukierunkowana.
- Dokładność i niezawodność : automatyczne skrobanie minimalizuje błędy ludzkie, co prowadzi do dokładniejszych zestawów danych.
- Lepsze podejmowanie decyzji : Dostęp do aktualnych, odpowiednich danych wspiera świadome podejmowanie decyzji i planowanie strategiczne.
Techniki skrobania sieci: od podstawowych do zaawansowanych

Źródło obrazu: loginworks
Skrobanie danych internetowych ewoluowało wraz z technologią, począwszy od podstawowych technik, które rozwijały się wraz ze wzrostem złożoności danych.
- Podstawowe techniki : Początkowo skrobaki pobierają dane za pomocą prostych żądań HTTP w celu uzyskania stron HTML, analizując zawartość za pomocą bibliotek takich jak Beautiful Soup w Pythonie. Narzędzia te radzą sobie odpowiednio z nieskomplikowanymi stronami internetowymi.
- Techniki średniozaawansowane : w przypadku treści dynamicznych techniki ewoluują i obejmują narzędzia automatyzacji, takie jak Selenium, które mogą wchodzić w interakcję z JavaScriptem i naśladować zachowanie przeglądarki.
- Zaawansowane techniki : w kierunku zaawansowanego skrobania metody obejmują przeglądarki bezobsługowe i serwery proxy do poruszania się po środkach zapobiegających skrobaniu. Ekstrakcja danych staje się wyrafinowana dzięki algorytmom uczenia maszynowego, przetwarzaniu języka naturalnego i obrazów w celu uzyskania informacji.
- Względy etyczne : Niezależnie od złożoności techniki, dylematy etyczne nadal istnieją, co wymaga równowagi między dostępem do danych a poszanowaniem prywatności i własności.
Włączanie danych pochodzących z Internetu do analizy Big Data
Dane z Internetu, po zintegrowaniu z analizą dużych zbiorów danych, mogą ujawnić kompleksowe spostrzeżenia rynkowe i trendy konsumenckie. Analitycy łączą informacje pobrane z Internetu z istniejącymi zbiorami danych, zwiększając głębokość i zakres wyników analiz. To połączenie skutkuje ulepszonymi modelami predykcyjnymi, dostosowanymi strategiami marketingowymi i udoskonalonymi profilami konsumentów.

- Czyszczenie danych: Pobrane dane wymagają dokładnego oczyszczenia, aby zapewnić dokładność analiz.
- Integracja danych: Łączenie zebranych danych z innymi źródłami wymaga zaawansowanych technik integracji danych.
- Ulepszenie analizy: dzięki dodatkowym danym algorytmy uczenia maszynowego mogą ujawnić bardziej szczegółowe wzorce.
- Względy etyczne: Analitycy muszą zapewnić, że wykorzystanie danych internetowych jest zgodne ze standardami prawnymi i etycznymi.
Rozszerzona pula danych napędza innowacje, wymaga jednak rygorystycznej metodologii i nadzoru etycznego.
Najlepsze praktyki dotyczące wydajnego skrobania sieci
- Przestrzegaj protokołów pliku robots.txt; nie usuwaj witryn, które na to nie pozwalają, za pośrednictwem pliku robots.
- Zaplanuj działania scrapingu poza godzinami szczytu, aby zminimalizować wpływ na wydajność serwera docelowego.
- Wykorzystaj buforowanie, aby uniknąć ponownego kopiowania tej samej treści, szanując dane witryny i oszczędzając przepustowość.
- Zaimplementuj odpowiednią obsługę błędów, aby zapobiec awariom skrobaka i uniknąć wysyłania zbyt wielu żądań w przypadku błędów.
- Zmieniaj programy użytkownika i adresy IP, aby zapobiec blokowaniu, symulując bardziej naturalne zachowanie przeglądania.
- Bądź na bieżąco z legalnymi i etycznymi praktykami skrobania stron internetowych, upewniając się, że Twoje działania związane z skrobaniem nie naruszają praw autorskich ani przepisów dotyczących prywatności.
- Zoptymalizuj kod, aby był wydajny i zmniejsz obciążenie zarówno systemu scrapingu, jak i docelowych witryn internetowych.
- Regularnie aktualizuj kod skrobania, aby dostosować się do wszelkich zmian w układzie strony internetowej lub technologii, zachowując skuteczność i dokładność wyszukiwania danych.
- Przechowuj zebrane dane w bezpieczny sposób i zarządzaj nimi zgodnie ze wszystkimi obowiązującymi przepisami o ochronie danych.
Przyszłość Web Scrapingu w erze Big Data
W miarę ciągłego rozwoju Big Data, zbieranie danych internetowych stanie się jeszcze bardziej integralną częścią analizy danych i analityki biznesowej. Przyszłość prawdopodobnie przyniesie:
- Ulepszone modele uczenia maszynowego szkolone na podstawie ogromnych zbiorów danych uzyskanych w drodze skrobania, poprawiające dokładność i spostrzeżenia.
- Zwiększone zapotrzebowanie na zbieranie danych w czasie rzeczywistym, umożliwiające firmom szybsze podejmowanie decyzji opartych na danych.
- Opracowanie bardziej wyrafinowanych narzędzi do skrobania w celu poruszania się po technologiach zapobiegających skrobaniu i utrzymywania praktyk gromadzenia danych etycznych.
- Bardziej rygorystyczne przepisy i przepisy dotyczące prywatności kształtujące metodologie zbierania danych internetowych, zapewniające gromadzenie danych w sposób odpowiedzialny i za zgodą.
- Pojawienie się platform typu scraping jako usługa oferujących dostosowaną do potrzeb ekstrakcję danych dla firm każdej wielkości.
Dzięki tym udoskonaleniom web scraping pozostanie kluczowym narzędziem w zestawie narzędzi Big Data.
Jeśli ręczne przeglądanie stron internetowych wydaje się zniechęcające lub wymagana jest pomoc w rozwiązaniu skomplikowanych problemów związanych z uzyskaniem cennych danych, możesz mieć pewność, że PromptCloud jest gotowy do pomocy!
Specjalizujemy się w dostarczaniu kompleksowych rozwiązań do skrobania sieci, zaprojektowanych specjalnie dla inicjatyw związanych z dużymi zbiorami danych, zapewniających niezawodną ekstrakcję danych na dużą skalę.
Zaufaj nam, że poradzimy sobie z wymagającymi aspektami, umożliwiając Ci skoncentrowanie się na generowaniu świadomych wyborów z wykorzystaniem solidnych i znaczących zbiorów danych. Skontaktuj się z nami pod adresem sales@promptcloud.com, aby dowiedzieć się, w jaki sposób nasza wiedza może ulepszyć Twój plan gry w zakresie Big Data!