
Co to jest ekstrakcja danych: przewodnik dla początkujących
Opublikowany: 2023-11-07W epoce, w której dane są tak samo cenne jak waluta, możliwość skutecznego ich wyodrębnienia może wyróżnić Twoją firmę na tle konkurencji. Ekstrakcja danych to nie tylko proces techniczny; jest to strategia strategiczna, która, jeśli zostanie właściwie wykonana, może ujawnić spostrzeżenia prowadzące do mądrzejszych decyzji biznesowych i solidnego wzrostu. W tym poście na blogu szczegółowo omówiono, co, dlaczego i jak ekstrahować dane, dzięki czemu uzyskasz wiedzę niezbędną do wykorzystania pełnego potencjału tej metody.
Co to jest ekstrakcja danych
Ekstrakcja danych to proces odzyskiwania ustrukturyzowanych lub nieustrukturyzowanych danych z różnych źródeł, takich jak bazy danych, strony internetowe, dokumenty, obrazy itp. Dane te są następnie konwertowane do łatwiejszego w zarządzaniu i użytecznego formatu, takiego jak arkusz kalkulacyjny lub baza danych. Celem jest zebranie tych informacji w sposób zachowujący ich znaczenie, a jednocześnie udostępniający je do analiz i wywiadu biznesowego.
Źródło: https://papersoft-dms.com/
Dlaczego wyodrębnianie danych jest kluczowe
- Świadome podejmowanie decyzji: wyodrębnione dane stanowią podstawę analiz, które mogą odkrywać trendy, przewidywać wyniki i kierować decyzjami strategicznymi.
- Wydajność: automatyzacja procesów ekstrakcji danych oszczędza czas i zasoby, eliminując błędy ręczne i nadmiarowość.
- Integracja: umożliwia łączenie danych z różnych źródeł, zapewniając całościowy obraz operacji.
- Przewaga konkurencyjna: Szybki dostęp do odpowiednich danych może zapewnić firmie przewagę, której potrzebuje, aby wyprzedzić konkurencję.
Rodzaje ekstrakcji danych
W świecie pełnym informacji, w którym żyjemy, umiejętność efektywnego wydobywania danych z różnych źródeł jest nieoceniona. Procesy ekstrakcji danych różnią się nie tylko metodologią, ale także zastosowaniem. Zrozumienie rodzajów ekstrakcji danych pomoże Ci wybrać technikę odpowiednią do Twoich potrzeb.
1. Ręczna ekstrakcja danych
Ręczna ekstrakcja danych to najbardziej podstawowa forma, obejmująca wkład człowieka w zbieranie danych ze źródeł fizycznych lub cyfrowych. Ta metoda jest często powolna i podatna na błędy, ale może być użyteczna w przypadku złożonych informacji wymagających ludzkiej oceny.
2. Automatyczna ekstrakcja danych
Ten typ wykorzystuje oprogramowanie i narzędzia do automatycznego gromadzenia i przetwarzania danych, co znacznie przyspiesza proces i zmniejsza prawdopodobieństwo wystąpienia błędów.
3. Ekstrakcja danych internetowych (skrobanie sieci)
Skrobanie sieci to technika używana do wydobywania danych ze stron internetowych. Odbywa się to za pomocą oprogramowania imitującego przeglądanie Internetu przez człowieka w celu gromadzenia określonych informacji ze źródeł internetowych.
4. Ekstrakcja danych strukturalnych
Ten typ odnosi się do wyszukiwania danych zorganizowanych w ustrukturyzowanym formacie, takim jak bazy danych lub arkusze kalkulacyjne, gdzie dane są spójne i mają określony schemat.
5. Ekstrakcja danych nieustrukturyzowanych
Ekstrakcja danych nieustrukturyzowanych dotyczy danych, które nie mają określonego formatu ani struktury, takich jak wiadomości e-mail, pliki PDF lub multimedia.
6. Ekstrakcja danych półstrukturalnych
Ekstrakcja danych częściowo ustrukturyzowanych dotyczy danych, które nie znajdują się w relacyjnej bazie danych, ale mają pewne właściwości organizacyjne, dzięki czemu są łatwiejsze do analizy niż dane nieustrukturyzowane.
7. Ekstrakcja danych w oparciu o zapytania
Metoda ta polega na użyciu zapytań w celu pobrania danych z baz danych. Jest to wysoce wydajna forma ustrukturyzowanej ekstrakcji danych, która umożliwia pobieranie informacji w czasie rzeczywistym lub według harmonogramu.
Techniki ekstrakcji danych
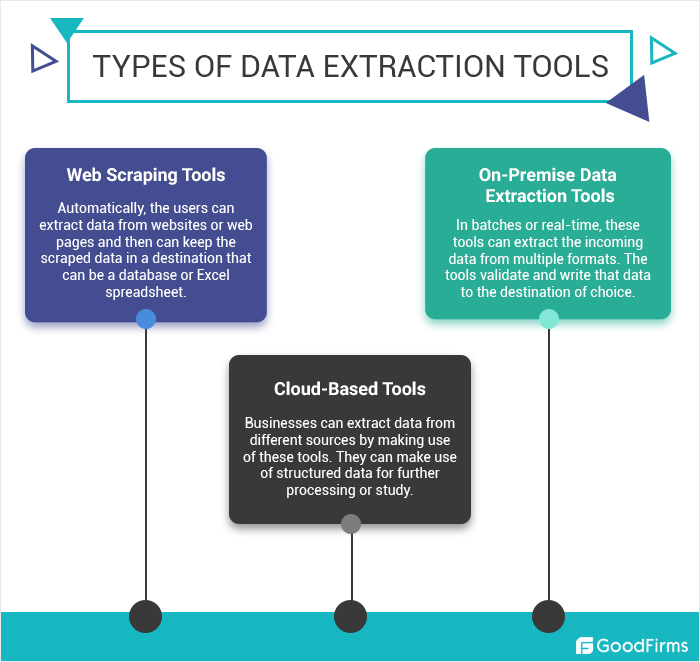
- Automatyczne przechwytywanie danych: narzędzia, które automatycznie wykrywają i wyodrębniają odpowiednie informacje z dokumentów lub stron internetowych.
- Przeszukiwanie sieci: używanie oprogramowania do symulacji eksploracji sieci przez człowieka w celu zebrania określonych danych.
- Analiza tekstu: wykorzystanie przetwarzania języka naturalnego w celu wyodrębnienia informacji z tekstu nieustrukturyzowanego.
- Procesy ETL: oznaczające Extract, Transform, Load, to zintegrowane systemy, które pobierają dane z różnych źródeł, konwertują je do użytecznego formatu i przechowują w hurtowni danych.
Najlepsze praktyki skutecznej ekstrakcji danych
- Zdefiniuj jasne cele: dowiedz się, czego potrzebujesz w zakresie ekstrakcji danych, aby wybrać odpowiednie narzędzia i metody.
- Zapewnij jakość danych: zweryfikuj i wyczyść dane w ramach procesu ekstrakcji, aby zachować integralność.
- Zachowaj zgodność: pamiętaj o przepisach i regulacjach dotyczących prywatności danych, aby mieć pewność, że Twoje metody ekstrakcji danych są legalne.
- Skalowalność: wybierz rozwiązania, które można rozwijać wraz z potrzebami w zakresie danych, aby uniknąć przyszłych remontów.
Wyzwania w ekstrakcji danych
Ekstrakcja danych, choć bezcenna, stwarza szereg wyzwań, które mogą skomplikować proces zarówno dla firm, jak i osób prywatnych. Wyzwania te mogą mieć wpływ na jakość, szybkość i efektywność inicjatyw opartych na danych. Poniżej zagłębiamy się w niektóre typowe przeszkody napotykane w procesie ekstrakcji danych.

- Problemy z jakością danych:
- Niespójne dane: wyodrębnianie danych z różnych źródeł często oznacza radzenie sobie z niespójnościami w formacie, strukturze i jakości, co może prowadzić do niedokładnych zbiorów danych.
- Niekompletne dane: brakujące wartości lub niekompletne zapisy podczas wyodrębniania mogą zniekształcić wyniki analiz.
- Duplikaty: podczas ekstrakcji mogą pojawić się nadmiarowe dane, co prowadzi do nieefektywności i zniekształconych wyników analiz.
- Problemy ze skalowalnością:
- Wolumen: wraz ze wzrostem ilości danych coraz większym wyzwaniem staje się wyodrębnienie informacji w sposób terminowy i skuteczny bez pogarszania wydajności systemu.
- Ewoluujące dane: Ciągła ewolucja danych wymaga skalowalnego procesu ekstrakcji, który można dostosować do zmian bez konieczności rozległej rekonfiguracji.
- Złożone i różnorodne źródła danych:
- Różnorodność: Wyodrębnianie danych z szerokiej gamy źródeł w różnych formatach (pliki PDF, strony internetowe, bazy danych itp.) wymaga wszechstronnych i wyrafinowanych narzędzi do ekstrakcji.
- Dostępność: Dostęp do danych zamkniętych w starszych systemach lub w zastrzeżonych formatach może być szczególnie trudny.
- Ograniczenia techniczne:
- Trudności w integracji: Integracja wyodrębnionych danych z istniejącymi systemami może stwarzać wyzwania techniczne, szczególnie w przypadku różnych technologii lub przestarzałej infrastruktury.
- Brak wiedzy specjalistycznej: Często wymagana jest intensywna nauka narzędzi i technik potrzebnych do wydajnej ekstrakcji danych, wymagająca specjalistycznej wiedzy.
- Kwestie prawne i związane ze zgodnością:
- Przepisy dotyczące prywatności: przestrzeganie rygorystycznych przepisów dotyczących ochrony danych, takich jak RODO lub HIPAA, może skomplikować proces ekstrakcji, ponieważ niektóre dane mogą wymagać dodatkowych protokołów obsługi.
- Własność intelektualna: Podczas wydobywania danych ze źródeł zewnętrznych istnieje ryzyko naruszenia praw własności intelektualnej, co może prowadzić do komplikacji prawnych.
- Ekstrakcja danych w czasie rzeczywistym:
- Opóźnienie: rośnie zapotrzebowanie na ekstrakcję danych w czasie rzeczywistym w niektórych sektorach, takich jak finanse czy bezpieczeństwo, gdzie opóźnienie może znacząco wpłynąć na proces decyzyjny.
- Infrastruktura: Ekstrakcja danych w czasie rzeczywistym wymaga solidnej infrastruktury, która może obsłużyć ciągły przepływ danych bez wąskich gardeł.
- Transformacja danych:
- Konwersja formatu: Wyodrębnione dane często wymagają transformacji do innego formatu na potrzeby analizy, co może być procesem złożonym i podatnym na błędy.
- Utrzymanie kontekstu: zapewnienie, że dane zachowają swoje znaczenie po wyodrębnieniu i przekształceniu, jest sprawą krytyczną, ale wymagającą, szczególnie w przypadku danych nieustrukturyzowanych.
- Obawy dotyczące bezpieczeństwa:
- Naruszenia danych: Zawsze istnieje ryzyko naruszenia danych podczas wydobywania wrażliwych lub poufnych informacji, co wymaga rygorystycznych środków bezpieczeństwa.
- Uszkodzenie danych: Dane mogą zostać uszkodzone podczas wyodrębniania z powodu błędów oprogramowania, problemów ze zgodnością lub awarii sprzętu.
Wniosek
Ekstrakcja danych, będąca podstawą procesu analizy danych, może wydawać się zniechęcająca, ale przy właściwym podejściu staje się katalizatorem wglądu i możliwości. Rozumiejąc jego zasady i wykorzystując obecne technologie, każda organizacja może uwolnić pełny potencjał swoich danych.