
Co to jest etykietowanie danych w uczeniu maszynowym i jak to działa?
Opublikowany: 2022-04-29Dane to nowe bogactwo dla dzisiejszych firm. Ponieważ technologie takie jak sztuczna inteligencja stopniowo przejmują większość naszych codziennych czynności, właściwe wykorzystanie wszelkich danych ma pozytywny wpływ na społeczeństwo. Dzięki efektywnej segregacji i etykietowaniu danych algorytmy ML mogą wykrywać problemy i dostarczać praktyczne i odpowiednie rozwiązania.
Za pomocą etykietowania danych uczymy maszynę różnych technik i wprowadzamy informacje w różnych formatach, aby zachowywały się „mądrze”. Nauka stojąca za oznaczaniem danych wymaga wielu prac domowych w formie adnotacji lub oznaczania zbiorów danych wieloma odmianami tych samych informacji. Chociaż ostateczny rezultat zaskakuje i ułatwia nasze codzienne życie, wysiłek związany z tym samym jest ogromny, a poświęcenie godne pochwały.
Co to jest etykietowanie danych?
W uczeniu maszynowym jakość i rodzaj danych wejściowych określa jakość i rodzaj danych wyjściowych. Jakość danych wykorzystywanych do trenowania maszyny zwiększa dokładność modelu AI.
Innymi słowy, oznaczanie danych to proces uczenia maszyny w zakresie znajdowania różnic i podobieństw między nieustrukturyzowanymi lub ustrukturyzowanymi zestawami danych poprzez oznaczanie ich etykietami lub adnotacjami.
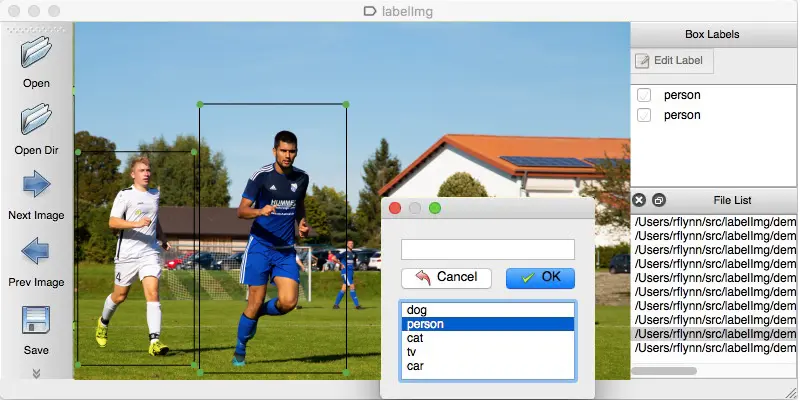
Zrozummy to na przykładzie. Aby nauczyć maszynę, że czerwone światło jest znakiem do zatrzymania, musisz oznaczyć wszystkie czerwone światła na różnych obrazkach, aby maszyna zrozumiała sygnał. Na tej podstawie sztuczna inteligencja tworzy algorytm, który w każdym scenariuszu odczyta czerwone światło jako sygnał stopu. Innym przykładem jest to, że gatunki muzyczne można segregować za pomocą wielu zestawów danych pod nazwami jazz, pop, rock, classic i inne.
Wyzwania w etykietowaniu danych
Wszelkie nowe zmiany/postępy w technologii lub konstrukcji niosą ze sobą korzyści i wyzwania. Nie inaczej jest w przypadku etykietowania danych. Chociaż oznaczanie danych może drastycznie skrócić czas skalowania firmy , wiąże się to z pewnymi kosztami. Zastanówmy się nad niektórymi wyzwaniami, jakie niesie ze sobą etykietowanie danych.
Koszt pod względem czasu i wysiłku
Pozyskiwanie ogromnych ilości danych niszowych jest wyzwaniem samym w sobie. Ręczne dodawanie tagów dla każdego elementu tylko zwiększa i tak czasochłonne zadanie. Jeśli projekt jest obsługiwany wewnętrznie, większość czasu projektu poświęca się na zadania związane z danymi, takie jak zbieranie, przygotowywanie i etykietowanie danych.
Aby skutecznie zarządzać tymi zadaniami i wykonywać pracę od razu, będziesz potrzebować ekspertów zajmujących się etykietowaniem z tą konkretną wiedzą. Jest to również przedsięwzięcie kosztowne, co sprawia, że jest ono kosztowne nie tylko pod względem czasu, ale także pieniędzy.
Niezgodność
Osoby wykonujące adnotacje o różnym doświadczeniu mogą mieć różne kryteria etykietowania. W konsekwencji istnieje duże prawdopodobieństwo niespójnego tagowania. To powiedziawszy, gdy kilka osób oznaczy ten sam zestaw danych, wskaźniki dokładności danych będą znacznie wyższe.
Ekspertyza domeny
W przypadku określonych branż odczujesz potrzebę zatrudnienia osób zajmujących się etykietowaniem z określoną wiedzą specjalistyczną w danej dziedzinie. Na przykład przy tworzeniu aplikacji ML dla sektora opieki zdrowotnej adnotatorom bez odpowiedniej wiedzy w dziedzinie domeny będzie bardzo trudno prawidłowo oznaczyć elementy.
Niedoskonałości
Każda powtarzalna praca wykonywana przez ludzi jest podatna na błędy. Bez względu na poziom wiedzy osoby zajmującej się etykietowaniem, ręczne znakowanie zawsze będzie miało zakres niedoskonałości. Zapewnienie zerowych błędów jest prawie niemożliwe, ponieważ adnotatorzy muszą radzić sobie z dużymi zestawami surowych danych do etykietowania.
Podejścia do etykietowania danych
Jak wspomniano powyżej, etykietowanie danych to czasochłonne zadanie, które wymaga dbałości o szczegóły. W zależności od opisu problemu ilość danych, które mają być oznakowane, złożoność danych i styl, strategia zastosowana do opisywania danych będzie się różnić.
Przyjrzyjmy się różnym podejściom, które Twoja firma może wybrać w oparciu o zasoby finansowe i dostępny czas.
Wewnętrzne etykietowanie danych
W zależności od branży, czasu potrzebnego na ukończenie danego projektu AI oraz dostępności wymaganych zasobów, proces etykietowania danych może być wykonywany we własnym zakresie przez organizacje.
Plusy:
- Wysoka celność
- Wysoka jakość
- Uproszczone śledzenie
Cons:
- Czasochłonne/wolne
- Wymagaj dużych zasobów
Crowdsourcing
Pozyskiwanie zbiorów danych, które są oznaczone przez freelancerów, są dostępne na różnych platformach crowdsourcingowych. Ta metoda może być używana do opisywania uogólnionych danych, takich jak obrazy.
Najbardziej znanym przykładem etykietowania danych poprzez crowdsourcing jest Recaptcha. Użytkownik jest proszony o zidentyfikowanie określonych rodzajów obrazów, aby udowodnić, że są ludźmi. Są one weryfikowane na podstawie danych wprowadzonych przez innych użytkowników. Działa jako baza danych etykiet dla tablicy obrazów.
Plusy:
- Szybko i łatwo
- Opłacalne
Cons:
- Nie można używać do danych, które wymagają wiedzy specjalistycznej w dziedzinie
- Jakość nie jest gwarantowana
Outsourcing
Outsourcing może działać jako środek pośredni między wewnętrznym etykietowaniem danych a crowdsourcingiem. Zatrudnianie organizacji zewnętrznych lub osób z doświadczeniem w dziedzinie domeny może pomóc organizacjom we wszystkich — długoterminowych i krótkoterminowych projektach.
Plusy:
- Optymalny dla tymczasowych projektów wysokiego poziomu
- Zewnętrzne firmy outsourcingowe zapewniają sprawdzony personel
- Zapewnia zarówno gotowe, jak i niestandardowe narzędzia do etykietowania danych zgodnie z potrzebami Twojej firmy
- Może uzyskać opcję wyspecjalizowanych w niszach ekspertów w zakresie etykietowania danych
Cons:
- Zarządzanie stroną trzecią może być czasochłonne
Oparta na maszynie
Jedną z najnowszych form oznaczania danych i adnotacji, która jest szeroko stosowana i akceptowana przez branże, jest adnotacja maszynowa. Automatyzacja procesu znakowania danych za pomocą oprogramowania do znakowania danych zmniejsza ingerencję człowieka i zwiększa szybkość, z jaką można wykonać znakowanie. Dzięki technice zwanej aktywnym uczeniem dane mogą być oznaczane, w oparciu o które tagi mogą być automatycznie dodawane do treningowych zestawów danych.
Plusy:
- Szybsze przetwarzanie danych i etykietowanie
- Obejmuje mniejszą interwencję człowieka
Cons:
- Chociaż lepsza jakość, ale nie dorównuje ludzkiemu tagowaniu
- W przypadku błędów nadal wymagana jest interwencja człowieka

Jak działa oznaczanie danych?
W oparciu o potrzeby biznesowe możesz wybrać podejście, które najlepiej odpowiada Twoim wymaganiom. Jednak proces oznaczania danych działa w następującej kolejności chronologicznej.
Zbieranie danych
Podstawą każdego projektu uczenia maszynowego są dane. Zebranie odpowiedniej ilości surowych danych w różnych formatach to pierwszy etap etykietowania danych. Zbieranie danych może mieć dwie formy – jedną, którą firma zbiera wewnętrznie, a drugą, która jest zbierana ze źródeł zewnętrznych, które są publicznie dostępne.
Będąc w postaci surowej, dane te wymagają oczyszczenia i przetworzenia przed utworzeniem etykiet dla zestawów danych. Te oczyszczone i wstępnie przetworzone dane są następnie przekazywane do modelu w celu uczenia. Im większe i bardziej zróżnicowane dane, tym dokładniejsze będą wyniki.
Adnotacja do danych
Po oczyszczeniu danych eksperci domeny przeglądają dane i dodają etykiety, stosując różne podejścia do etykietowania danych. Do modelu dołączony jest znaczący kontekst, który można wykorzystać jako podstawową prawdę . Są to zmienne docelowe, takie jak obrazy, które model ma przewidywać.

Zapewnienie jakości
Powodzenie uczenia modelu ML w dużym stopniu zależy od jakości danych, które powinny być wiarygodne, dokładne i spójne. Aby zapewnić precyzyjne i dokładne etykiety danych, należy przeprowadzać regularne kontrole jakości. Za pomocą algorytmów kontroli jakości, takich jak test konsensusu i test alfa Cronbacha, można określić dokładność tych adnotacji. Regularne kontrole QA znacznie przyczyniają się do dokładności wyników.
Szkolenie i testowanie modeli
Wykonanie wszystkich powyższych kroków ma sens tylko wtedy, gdy dane są testowane pod kątem dokładności. Wprowadzenie nieustrukturyzowanego zestawu danych w celu sprawdzenia, czy dostarcza on oczekiwanych wyników, spowoduje przetestowanie procesu.
Branżowe przypadki użycia do etykietowania danych
Teraz, gdy już wiemy, czym jest etykietowanie danych i jak działa, przyjrzyjmy się najbardziej znanym przypadkom użycia.
Widzenie komputerowe (CV)
Jest to podzbiór sztucznej inteligencji, który umożliwia maszynom uzyskanie znaczącej interpretacji na podstawie danych wejściowych dostarczonych w postaci wizualizacji i filmów (zdjęcia wyodrębnione w celu oznaczenia).
Adnotacje wizji komputerowej mogą być wykorzystywane w różnych branżach do wdrażania praktycznych korzyści płynących ze sztucznej inteligencji.
- W branży motoryzacyjnej oznaczanie obrazów i filmów w celu segmentowania dróg, budynków, pieszych i innych obiektów pomoże autonomicznym pojazdom rozróżniać te podmioty, aby uniknąć kontaktu w prawdziwym życiu.
- W branży opieki zdrowotnej objawy choroby można podzielić na segmenty za pomocą prześwietlenia rentgenowskiego, rezonansu magnetycznego i tomografii komputerowej. Za pomocą obrazów mikroskopowych większość krytycznych chorób można zdiagnozować na wczesnym etapie.
- Kody QR, kody kreskowe etykiet itp. mogą być używane jako etykiety w branży transportowej i logistycznej do śledzenia towarów.
Przetwarzanie języka naturalnego (NLP)
Jest to podzbiór, który umożliwia maszynom AI interpretowanie ludzkiego języka i statystyk. Wywodząc znaczenie z tekstu i mowy, algorytm może analizować różne aspekty językowe.
NLP jest coraz częściej stosowany w wielu rozwiązaniach dla przedsiębiorstw .
- Jest powszechnie używany we wszystkich branżach jako asystent poczty e-mail, funkcja autouzupełniania, sprawdzanie pisowni, segregowanie wiadomości spamowych i niebędących spamem oraz wiele innych.
- W postaci chatbotów , podstawowe zapytania zgłaszane przez klientów są interpretowane i udzielane na nie bez ingerencji człowieka w czasie rzeczywistym. Przewiduje się, że do 2023 roku 70% interakcji z klientami będzie zarządzanych przez chatboty i aplikacje do komunikacji mobilnej.
- Zrozumienie negatywnej i pozytywnej polaryzacji tekstu w celu uchwycenia nastrojów klientów odbywa się poprzez etykietowanie danych w e-commerce.
Appinventiv z powodzeniem zbudował aplikację społecznościową dla Vyrb , która umożliwia użytkownikom wysyłanie i odbieranie wiadomości audio zoptymalizowanych pod kątem urządzeń do noszenia Bluetooth.

Przegląd rynku etykietowania danych AI
Etykietowanie danych to kwitnąca branża wywodząca się z technologii AI . Ponieważ oznaczanie danych jest w dużej mierze zależne od dokładnych danych przekazywanych do uczenia maszynowego, w ciągu najbliższych kilku lat z pewnością wzrośnie.
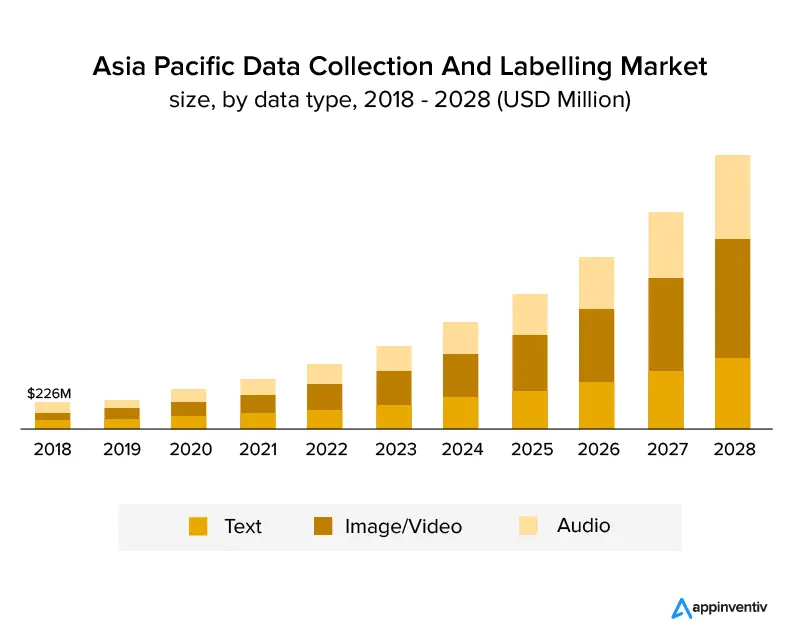
Poniższy wykres wyraźnie pokazuje, że branża rozwijała się i będzie rosła w nadchodzących latach. Oczekuje się, że do 2028 r. będzie rosnąć ze złożonym rocznym wzrostem na poziomie 25,6% i osiągnie wielkość rynku 8,22 mld USD. Poniższy wykres przedstawia wzrost według typu danych.
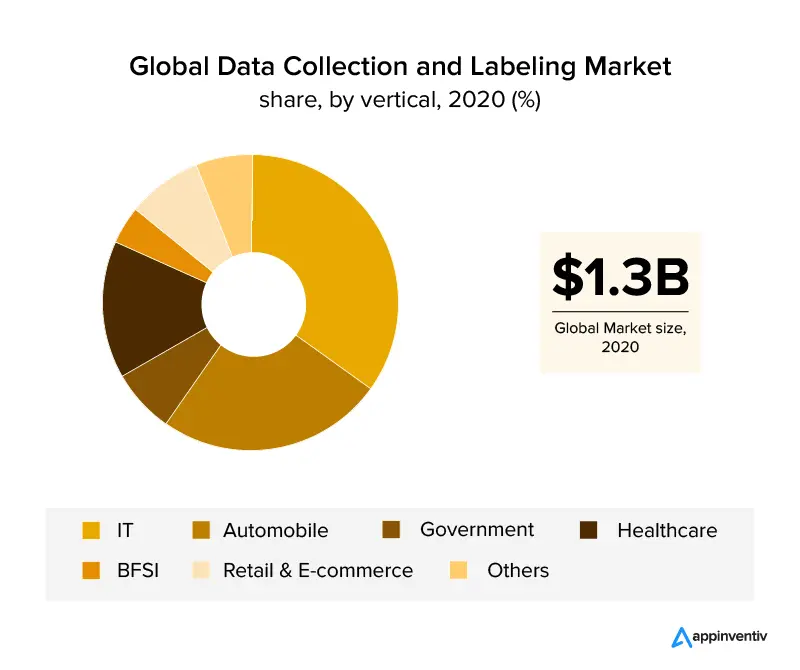
Przegląd branż, które wykorzystywały etykietowanie danych, to sektory IT i motoryzacyjny, które obejmują ponad 30% udziału w globalnych przychodach. Oczekuje się, że wraz z rozwojem branży opieki zdrowotnej nastąpi boom na etykietowanie danych ze względu na dokładne wymagania dotyczące danych dla wydajnych aplikacji opartych na sztucznej inteligencji w tym sektorze. Dzięki etykietowaniu wizerunkowemu również branża handlu detalicznego i handlu elektronicznego zapewniła sobie znaczny udział w rynku w branży etykietowania danych.
Etykietowanie danych za pomocą Appinventiv
Strategicznie firmy zlecają usługi gromadzenia danych i etykietowania w celu budowania silnych modeli uczenia maszynowego.
Appinventiv to firma zajmująca się rozwojem AI i ML, która od wielu lat pomaga organizacjom w odkrywaniu nowych możliwości dzięki rozwiązaniom opartym na sztucznej inteligencji . Dzięki prawie dziesięcioletniemu doświadczeniu w przekształcaniu przedsiębiorstw, z powodzeniem zrealizowaliśmy wiele złożonych projektów AI dla różnych branż.
Na przykład Appinventiv z powodzeniem zautomatyzował proces bankowy dla wiodącego banku w Europie. Proces automatyzacji pomógł bankowi poprawić dokładność o 50%, a poziom obsługi bankomatów o 92%.
Kolejny przykład, w którym Appinventiv pomógł YouCOMM zbudować rewolucyjne rozwiązanie do przekształcenia komunikacji wewnątrzszpitalnej z pacjentem poprzez zapewnienie dostępu do pomocy medycznej w czasie rzeczywistym. Dzięki dostosowywanemu systemowi komunikatów dla pacjentów pacjenci mogą łatwo powiadamiać personel o swoich potrzebach za pomocą poleceń głosowych i gestów głowy.
Dzięki naszej wiedzy i zespołowi skoncentrowanemu na kliencie zapewniamy usługi znakowania danych, które pomogą Ci przezwyciężyć wyzwania, zapewniając holistyczne usługi znakowania danych w oparciu o Twoje specyficzne potrzeby i wymagania.
Wykorzystując szeroką gamę narzędzi wymaganych do tagowania i adnotacji danych, Appinventiv może usprawnić procesy uczenia danych, aby uprościć złożone modele. Dzięki temu osiągamy lepsze wyniki pod względem dokładności segmentacji, klasyfikacji, a następnie oznaczania danych, co będzie szybkie i łatwe.
Zawijanie!
„Moc sztucznej inteligencji jest tak niesamowita, że zmieni społeczeństwo na bardzo głębokie sposoby”. – Bill Gates
Sztuczna inteligencja ma potencjał, aby ułatwić życie ludzkie, czyniąc dobro społeczeństwu. Jego zdolność do sortowania ogromnych ilości danych w zrozumiałe instrukcje za pomocą etykietowania danych pomogła branży w skokowym rozwoju i rozwoju.
FAQ
P. Jakie są najlepsze praktyki doskonalenia etykietowania danych?
O. W zależności od przyjętego podejścia do oznaczania danych istnieje kilka najlepszych praktyk, które można zastosować:
- Upewnij się, że gromadzone dane są odpowiednie, odpowiednio oczyszczone i przetworzone.
- W zależności od branży przypisz zadanie tylko do osób zajmujących się etykietowaniem danych będących ekspertami w danej dziedzinie.
- Upewnij się, że zespół stosuje jednolite podejście, dostarczając mu kryteriów technik adnotacji, których należy przestrzegać.
- Postępuj zgodnie z procesem sprawdzania twórcy, przypisując wiele adnotatorów do etykietowania krzyżowego.
P. Jakie są zalety etykietowania danych?
O. Etykietowanie danych pomaga w zapewnieniu lepszej jasności kontekstu, jakości i użyteczności w celu precyzyjnego przewidywania danych. To z kolei pomaga w poprawie użyteczności danych zmiennych w modelu.
P. Jakie są różne elementy, które należy wziąć pod uwagę podczas tworzenia krótkiej listy firm etykietujących dane?
O. Przy wyborze usług etykietowania danych na potrzeby uczenia maszynowego należy wziąć pod uwagę pięć parametrów.
- Skalowalność procesu znakowania danych
- Koszt usługi znakowania danych
- Ochrona danych
- Platforma do etykietowania danych