
Czym jest Robots.txt w SEO: jak go tworzyć i optymalizować?
Opublikowany: 2022-04-22Dzisiejszy temat nie jest bezpośrednio związany z monetyzacją ruchu. Jednak plik robots.txt może wpłynąć na SEO Twojej witryny i ostatecznie na ilość otrzymywanego ruchu. Wielu administratorów stron internetowych zrujnowało rankingi swoich witryn z powodu nieudanych wpisów w pliku robots.txt. Ten przewodnik pomoże ci uniknąć wszystkich tych pułapek. Koniecznie przeczytaj do końca!
- Co to jest plik robots.txt?
- Jak wygląda plik robots.txt?
- Jak znaleźć plik robots.txt
- Jak działa plik Robots.txt?
- Składnia pliku robots.txt
- Obsługiwane dyrektywy
- Agent użytkownika*
- Umożliwić
- Uniemożliwić
- Mapa strony
- Nieobsługiwane dyrektywy
- Opóźnienie indeksowania
- Noindeks
- Nofollow
- Czy potrzebujesz pliku robots.txt?
- Tworzenie pliku robots.txt
- Plik robots.txt: najlepsze praktyki SEO
- Użyj nowej linii dla każdej dyrektywy
- Użyj symboli wieloznacznych, aby uprościć instrukcje
- Użyj znaku dolara „$”, aby określić koniec adresu URL
- Użyj każdego klienta użytkownika tylko raz
- Użyj konkretnych instrukcji, aby uniknąć niezamierzonych błędów
- Wpisz komentarze w pliku robots.txt z haszem
- Użyj różnych plików robots.txt dla każdej subdomeny
- Nie blokuj dobrych treści
- Nie nadużywaj opóźnienia indeksowania
- Zwróć uwagę na wielkość liter
- Inne sprawdzone metody:
- Używanie robots.txt do zapobiegania indeksowaniu treści
- Używanie robots.txt do ochrony prywatnych treści
- Używanie robots.txt do ukrywania złośliwych duplikatów treści
- Pełny dostęp dla wszystkich botów
- Brak dostępu dla wszystkich botów
- Zablokuj jeden podkatalog dla wszystkich botów
- Zablokuj jeden podkatalog dla wszystkich botów (jeden plik w dozwolonym zakresie)
- Zablokuj jeden plik dla wszystkich botów
- Blokuj jeden typ pliku (PDF) dla wszystkich botów
- Blokuj wszystkie sparametryzowane adresy URL tylko dla Googlebota
- Jak przetestować plik robots.txt pod kątem błędów
- Przesłany adres URL zablokowany przez plik robots.txt
- Zablokowany przez plik robots.txt
- Zindeksowany, choć zablokowany przez robots.txt
- Robots.txt vs roboty meta vs roboty x
- Dalsze czytanie
- Zawijanie
Co to jest plik robots.txt?
Plik robots.txt lub protokół wykluczania robotów to zestaw standardów internetowych, które kontrolują sposób, w jaki roboty wyszukiwarek indeksują każdą stronę internetową, aż do znaczników schematu na tej stronie. Jest to standardowy plik tekstowy, który może nawet uniemożliwić robotom indeksującym dostęp do całej witryny lub jej części.
Dostosowując SEO i rozwiązując problemy techniczne, możesz zacząć uzyskiwać pasywny dochód z reklam. Pojedyncza linijka kodu na Twojej stronie zwraca regularne wypłaty!
Do treści ↑Jak wygląda plik robots.txt?
Składnia jest prosta: dajesz botom reguły, określając ich agenta użytkownika i dyrektywy. Plik ma następujący podstawowy format:
Mapa witryny: [lokalizacja adresu URL mapy witryny]
Klient użytkownika: [identyfikator bota]
[dyrektywa 1]
[dyrektywa 2]
[dyrektywa …]
User-agent: [inny identyfikator bota]
[dyrektywa 1]
[dyrektywa 2]
[dyrektywa …]
Jak znaleźć plik robots.txt
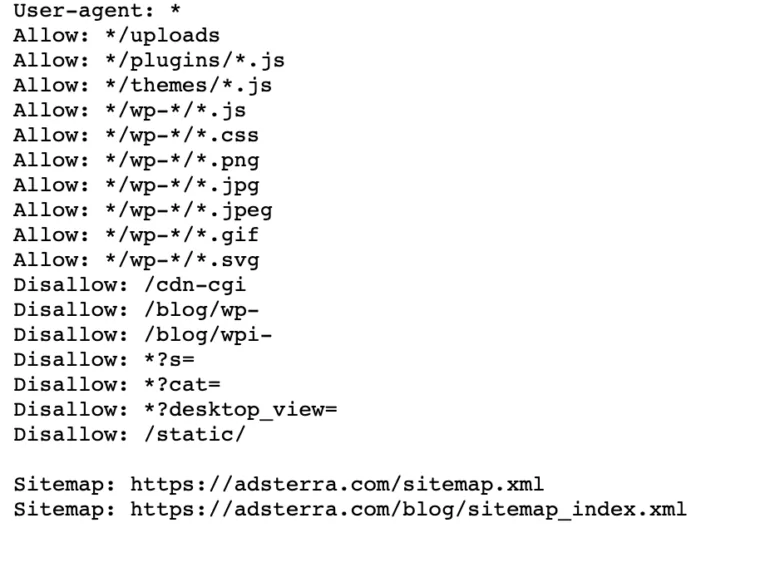
Jeśli w Twojej witrynie znajduje się już plik robot.txt, możesz go znaleźć, przechodząc do tego adresu URL: https://nazwatwojejdomeny.com/robots.txt w przeglądarce. Na przykład oto nasz plik
Jak działa plik Robots.txt?
Plik robots.txt to zwykły plik tekstowy, który nie zawiera żadnego kodu znaczników HTML (stąd rozszerzenie .txt). Plik ten, podobnie jak wszystkie inne pliki na stronie, jest przechowywany na serwerze WWW. Użytkownicy prawdopodobnie nie odwiedzą tej strony, ponieważ nie jest ona połączona z żadną z Twoich stron, ale większość robotów indeksujących wyszukuje ją przed zindeksowaniem całej witryny.
Plik robots.txt może przekazywać botom instrukcje, ale nie może ich egzekwować. Dobry bot, taki jak robot sieciowy lub bot kanału informacyjnego, sprawdzi plik i postępuje zgodnie z instrukcjami przed odwiedzeniem dowolnej strony domeny. Jednak złośliwe boty zignorują lub przetworzą plik w celu znalezienia zabronionych stron internetowych.
W sytuacji, gdy plik robots.txt zawiera sprzeczne polecenia, bot użyje najbardziej szczegółowego zestawu instrukcji.
Do treści ↑Składnia pliku robots.txt
Plik robots.txt składa się z kilku sekcji „dyrektyw”, z których każda zaczyna się od klienta użytkownika. Klient użytkownika określa bota indeksującego, z którym komunikuje się kod. Możesz adresować wszystkie wyszukiwarki jednocześnie lub zarządzać poszczególnymi wyszukiwarkami.
Za każdym razem, gdy bot indeksuje witrynę, działa na jej części, które ją wywołują.
Agent użytkownika: *
Uniemożliwić: /
Klient użytkownika: Googlebot
Uniemożliwić:
Klient użytkownika: Bingbot
Nie zezwalaj: /nie-dla-bing/
Obsługiwane dyrektywy
Dyrektywy są wytycznymi, których chcesz, aby klienci użytkownika, których deklarujesz, przestrzegali. Google obsługuje obecnie następujące dyrektywy.
Agent użytkownika*
Kiedy program łączy się z serwerem WWW (robotem lub zwykłą przeglądarką internetową), wysyła nagłówek HTTP zwany „user-agent” zawierający podstawowe informacje o jego tożsamości. Każda wyszukiwarka ma klienta użytkownika. Roboty Google są znane jako Googlebot, Yahoo — jako Slurp, a Bing — jako BingBot. Klient użytkownika inicjuje sekwencję dyrektyw, które mogą dotyczyć określonych klientów użytkownika lub wszystkich klientów użytkownika.
Umożliwić
Dyrektywa allow nakazuje wyszukiwarkom indeksowanie strony lub podkatalogu, nawet katalogu z ograniczeniami. Na przykład, jeśli chcesz, aby wyszukiwarki nie miały dostępu do wszystkich postów na Twoim blogu z wyjątkiem jednego, plik robots.txt może wyglądać tak:
Agent użytkownika: *
Nie zezwalaj: /blog
Zezwól: /blog/allowed-post
Wyszukiwarki mogą jednak uzyskać dostęp do /blog/allowed-post, ale nie mogą uzyskać dostępu do:
/blog/kolejny-post
/blog/jeszcze-kolejny-post
/blog/pobierz-me.pd
Uniemożliwić
Dyrektywa disallow (dodawana do pliku robots.txt witryny) informuje wyszukiwarki, aby nie indeksowały określonej strony. W większości przypadków zapobiegnie to również wyświetlaniu strony w wynikach wyszukiwania.
Możesz użyć tej dyrektywy, aby poinstruować wyszukiwarki, aby nie indeksowały plików i stron w określonym folderze, który ukrywasz przed opinią publiczną. Na przykład treści, nad którymi nadal pracujesz, ale które zostały omyłkowo opublikowane. Twój plik robots.txt może wyglądać tak, jeśli chcesz uniemożliwić wszystkim wyszukiwarkom dostęp do Twojego bloga:
Agent użytkownika: *
Nie zezwalaj: /blog
Oznacza to, że wszystkie podkatalogi katalogu /blog również nie zostałyby przeszukane. To również zablokowałoby Google dostęp do adresów URL zawierających /blog.
Do treści ↑Mapa strony
Mapy witryn to lista stron, które wyszukiwarki mają przeszukiwać i indeksować. Jeśli użyjesz dyrektywy sitemap, wyszukiwarki będą znały lokalizację Twojej mapy witryny XML. Najlepszą opcją jest przesłanie ich do narzędzi dla webmasterów wyszukiwarek, ponieważ każdy z nich może dostarczyć cennych informacji o Twojej witrynie dla odwiedzających.
Należy pamiętać, że powtarzanie dyrektywy mapy witryny dla każdego klienta użytkownika jest niepotrzebne i nie ma zastosowania do jednego agenta wyszukiwania. Dodaj dyrektywy mapy witryny na początku lub na końcu pliku robots.txt.
Przykład dyrektywy mapy witryny w pliku:
Mapa witryny: https://www.domain.com/sitemap.xml
Klient użytkownika: Googlebot
Nie zezwalaj: /blog/
Zezwól: /blog/tytuł-postu/
Klient użytkownika: Bingbot
Nie zezwalaj: /usługi/
Do treści ↑Nieobsługiwane dyrektywy
Poniżej znajdują się dyrektywy, których Google już nie obsługuje — niektóre z nich nigdy nie zostały technicznie zatwierdzone.
Opóźnienie indeksowania
Yahoo, Bing i Yandex szybko reagują na indeksowanie stron internetowych i reagują na dyrektywę o opóźnieniu indeksowania, która utrzymuje je w ryzach przez jakiś czas.
Zastosuj tę linię do swojego bloku:
Klient użytkownika: Bingbot
Opóźnienie indeksowania: 10
Oznacza to, że wyszukiwarki mogą czekać dziesięć sekund przed zaindeksowaniem witryny lub dziesięć sekund przed ponownym dostępem do witryny po zaindeksowaniu, co jest tym samym, ale nieco innym w zależności od używanego klienta użytkownika.
Noindeks
Metatag noindex to świetny sposób, aby uniemożliwić wyszukiwarkom indeksowanie jednej z Twoich stron. Tag umożliwia botom dostęp do stron internetowych, ale także informuje roboty, aby ich nie indeksowały.
- Nagłówek odpowiedzi HTTP ze znacznikiem noindex. Możesz zaimplementować ten tag na dwa sposoby: nagłówek odpowiedzi HTTP z X-Robots-Tag lub tagiem <meta> umieszczonym w sekcji <head>. Oto jak powinien wyglądać Twój tag <meta>:
<nazwa meta=”roboty” content=”noindex”>
- Kod stanu 404 i 410 HTTP. Kody stanu 404 i 410 wskazują, że strona nie jest już dostępna. Po zindeksowaniu i przetworzeniu stron 404/410 automatycznie usuwają je z indeksu Google. Aby zmniejszyć ryzyko stron z błędami 404 i 410, regularnie indeksuj swoją witrynę i korzystaj z przekierowań 301, aby w razie potrzeby skierować ruch na istniejącą stronę.
Nofollow
Nofollow nakazuje wyszukiwarkom, aby nie klikały linków na stronach i plikach pod określoną ścieżką. Od 1 marca 2020 r. Google nie uważa już atrybutów nofollow za dyrektywy. Zamiast tego będą podpowiedziami, podobnie jak znaczniki kanoniczne. Jeśli chcesz mieć atrybut „nofollow” dla wszystkich linków na stronie, użyj metatagu robota, nagłówka x-robots lub atrybutu linku rel= „nofollow” .
Wcześniej można było użyć następującej dyrektywy, aby uniemożliwić Google śledzenie wszystkich linków w Twoim blogu:
Klient użytkownika: Googlebot
Nofollow: /blog/
Czy potrzebujesz pliku robots.txt?
Wiele mniej skomplikowanych stron internetowych nie potrzebuje takiego. Chociaż Google zwykle nie indeksuje stron internetowych zablokowanych przez plik robots.txt, nie ma możliwości zagwarantowania, że strony te nie pojawią się w wynikach wyszukiwania. Posiadanie tego pliku zapewnia większą kontrolę i bezpieczeństwo treści w Twojej witrynie w porównaniu z wyszukiwarkami.
Pliki robotów pomagają również w realizacji następujących zadań:
- Zapobiegaj indeksowaniu duplikatów treści.
- Zachowaj prywatność dla różnych sekcji witryny.
- Ogranicz indeksowanie wewnętrznych wyników wyszukiwania.
- Zapobiegaj przeciążeniu serwera.
- Zapobiegaj marnotrawstwu „budżetu indeksowania”.
- Trzymaj obrazy, filmy i pliki zasobów poza wynikami wyszukiwania Google.
Środki te ostatecznie wpływają na Twoje taktyki SEO. Na przykład zduplikowana treść dezorientuje wyszukiwarki i zmusza je do wybrania, która z dwóch stron ma być pierwsza w rankingu. Niezależnie od tego, kto utworzył treść, Google może nie wybrać oryginalnej strony dla najlepszych wyników wyszukiwania.

W przypadkach, gdy Google wykryje zduplikowane treści mające na celu oszukanie użytkowników lub manipulowanie rankingami, dostosuje indeksowanie i ranking Twojej witryny. W rezultacie pozycja Twojej witryny może ucierpieć lub zostać całkowicie usunięta z indeksu Google, znikając z wyników wyszukiwania.
Zachowanie prywatności w różnych sekcjach witryny poprawia również bezpieczeństwo witryny i chroni ją przed hakerami. Na dłuższą metę te środki sprawią, że Twoja witryna będzie bezpieczniejsza, godna zaufania i zyskowna.
Czy jesteś właścicielem strony internetowej, który chce czerpać zyski z ruchu? Dzięki Adsterra uzyskasz pasywny dochód z dowolnej strony internetowej!
Do treści ↑Tworzenie pliku robots.txt
Będziesz potrzebował edytora tekstu, takiego jak Notatnik.
- Utwórz nowy arkusz, zapisz pustą stronę jako „robots.txt” i zacznij wpisywać dyrektywy w pustym dokumencie .txt.
- Zaloguj się do swojego cPanel, przejdź do katalogu głównego witryny, poszukaj folderu public_html .
- Przeciągnij plik do tego folderu, a następnie dwukrotnie sprawdź, czy uprawnienia do pliku są prawidłowo ustawione.
Możesz pisać, czytać i edytować plik jako właściciel, ale osoby trzecie nie są dozwolone. W pliku powinien pojawić się kod uprawnień „0644” . Jeśli nie, kliknij plik prawym przyciskiem myszy i wybierz „uprawnienia do pliku”.
Plik robots.txt: najlepsze praktyki SEO
Użyj nowej linii dla każdej dyrektywy
Musisz zadeklarować każdą dyrektywę w osobnym wierszu. W przeciwnym razie wyszukiwarki będą zdezorientowane.
Agent użytkownika: *
Nie zezwalaj: /katalog/
Disallow: /inny-katalog/
Użyj symboli wieloznacznych, aby uprościć instrukcje
Podczas deklarowania dyrektyw możesz używać symboli wieloznacznych (*) dla wszystkich klientów użytkownika i dopasowywać wzorce adresów URL. Symbol wieloznaczny sprawdza się dobrze w przypadku adresów URL o jednolitym wzorze. Możesz na przykład uniemożliwić indeksowanie wszystkich stron filtrujących ze znakiem zapytania (?) w adresach URL.
Agent użytkownika: *
Uniemożliwić: /*?
Użyj znaku dolara „$”, aby określić koniec adresu URL
Wyszukiwarki nie mogą uzyskać dostępu do adresów URL, które kończą się rozszerzeniami, takimi jak .pdf. Oznacza to, że nie będą mogli uzyskać dostępu do /file.pdf, ale będą mogli uzyskać dostęp do /file.pdf?id=68937586, który nie kończy się na „.pdf”. Na przykład, jeśli chcesz uniemożliwić wyszukiwarkom dostęp do wszystkich plików PDF w Twojej witrynie, plik robots.txt może wyglądać tak:
Agent użytkownika: *
Odrzuć: /*.pdf$
Użyj każdego klienta użytkownika tylko raz
W Google nie ma znaczenia, czy używasz tego samego klienta użytkownika więcej niż raz. Po prostu skompiluje wszystkie reguły z różnych deklaracji w jedną dyrektywę i zastosuje się do niej. Jednak zadeklarowanie każdego klienta użytkownika tylko raz ma sens, ponieważ jest mniej mylące.
Utrzymywanie porządku i prostoty dyrektyw zmniejsza ryzyko błędów krytycznych. Na przykład, jeśli plik robots.txt zawierał następujące klienty użytkownika i dyrektywy.
Klient użytkownika: Googlebot
Nie zezwalaj: /a/
Klient użytkownika: Googlebot
Odrzuć: /b/
Użyj konkretnych instrukcji, aby uniknąć niezamierzonych błędów
Podczas ustawiania dyrektyw, niedostarczenie konkretnych instrukcji może spowodować błędy, które mogą zaszkodzić SEO. Załóżmy, że masz witrynę wielojęzyczną i pracujesz nad niemiecką wersją podkatalogu /de/.
Nie chcesz, aby wyszukiwarki miały do niego dostęp, ponieważ nie jest jeszcze gotowy. Poniższy plik robots.txt uniemożliwi wyszukiwarkom indeksowanie tego podfolderu i jego zawartości:
Agent użytkownika: *
Nie zezwalaj: /de
Jednak ograniczy wyszukiwarkom indeksowanie stron lub plików zaczynających się od /de. W tym przypadku dodanie końcowego ukośnika jest prostym rozwiązaniem.
Agent użytkownika: *
Nie zezwalaj: /de/
Do treści ↑Wpisz komentarze w pliku robots.txt z haszem
Komentarze pomagają programistom, a być może nawet Tobie, zrozumieć Twój plik robots.txt. Rozpocznij linię hashem (#), aby dołączyć komentarz. Roboty indeksujące ignorują wiersze zaczynające się od skrótu.
# To instruuje bota Bing, aby nie indeksował naszej witryny.
Klient użytkownika: Bingbot
Uniemożliwić: /
Użyj różnych plików robots.txt dla każdej subdomeny
Plik robots.txt wpływa tylko na indeksowanie w jego domenie hosta. Będziesz potrzebować innego pliku, aby ograniczyć indeksowanie w innej subdomenie. Jeśli na przykład Twoja główna witryna jest hostowana na example.com, a blog na blog.example.com, potrzebne będą dwa pliki robots.txt. Umieść jeden plik w katalogu głównym domeny głównej, a drugi plik powinien znajdować się w katalogu głównym bloga.
Nie blokuj dobrych treści
Nie używaj pliku robots.txt ani tagu noindex do blokowania wysokiej jakości treści, które chcesz upublicznić, aby uniknąć negatywnego wpływu na wyniki SEO. Dokładnie sprawdź tagi noindex i odrzuć reguły na swoich stronach.
Nie nadużywaj opóźnienia indeksowania
Wyjaśniliśmy opóźnienie indeksowania, ale nie należy go często używać, ponieważ ogranicza to boty do indeksowania wszystkich stron. Może działać w przypadku niektórych witryn, ale jeśli masz dużą witrynę, możesz zaszkodzić swoim rankingom i ruchowi.
Zwróć uwagę na wielkość liter
W pliku Robots.txt rozróżniana jest wielkość liter, dlatego należy upewnić się, że plik robots został utworzony w odpowiednim formacie. Plik robots powinien mieć nazwę „robots.txt” ze wszystkimi małymi literami. W przeciwnym razie to nie zadziała.
Inne sprawdzone metody:
- Upewnij się, że nie blokujesz indeksowania treści ani sekcji swojej witryny.
- Nie używaj pliku robots.txt do przechowywania poufnych danych (prywatnych informacji użytkownika) poza wynikami SERP. Użyj innej metody, takiej jak szyfrowanie danych lub metadyrektywa noindex , aby ograniczyć dostęp, jeśli inne strony prowadzą bezpośrednio do strony prywatnej.
- Niektóre wyszukiwarki mają więcej niż jednego klienta użytkownika. Na przykład Google używa Googlebota do bezpłatnych wyszukiwań, a Googlebota-Image do zdjęć. Określanie dyrektyw dla wielu przeszukiwaczy każdej wyszukiwarki nie jest konieczne, ponieważ większość programów użytkownika z tej samej wyszukiwarki stosuje te same reguły.
- Wyszukiwarka buforuje zawartość pliku robots.txt, ale codziennie je aktualizuje. Jeśli zmienisz plik i chcesz go szybciej zaktualizować, możesz przesłać adres URL pliku do Google.
Używanie robots.txt do zapobiegania indeksowaniu treści
Wyłączenie strony to najskuteczniejszy sposób, aby uniemożliwić botom jej indeksowanie bezpośrednio. Jednak nie zadziała w następujących sytuacjach:
- Jeśli inne źródło zawiera linki do strony, boty nadal będą ją indeksować i indeksować.
- Nielegalne boty będą nadal przeszukiwać i indeksować zawartość.
Używanie robots.txt do ochrony prywatnych treści
Niektóre prywatne treści, takie jak pliki PDF lub strony z podziękowaniami, nadal mogą być indeksowane, nawet jeśli zablokujesz boty. Umieszczenie wszystkich swoich ekskluzywnych stron za loginem jest jednym z najlepszych sposobów wzmocnienia dyrektywy zakazującej. Twoje treści pozostaną dostępne, ale odwiedzający zrobią dodatkowy krok, aby uzyskać do nich dostęp.
Używanie robots.txt do ukrywania złośliwych duplikatów treści
Zduplikowana treść jest identyczna lub bardzo podobna do innej treści w tym samym języku. Google stara się indeksować i wyświetlać strony o unikalnej treści. Na przykład, jeśli Twoja witryna zawiera wersje „zwykłe” i „drukowane” każdego artykułu, a tag noindex nie blokuje żadnej z nich, zostanie wyświetlona jedna z nich.
Przykładowe pliki robots.txt
Poniżej znajduje się kilka przykładowych plików robots.txt. Są to przede wszystkim pomysły, ale jeśli któryś z nich odpowiada Twoim potrzebom, skopiuj go i wklej do dokumentu tekstowego, zapisz jako „robots.txt” i prześlij do odpowiedniego katalogu.
Pełny dostęp dla wszystkich botów
Istnieje kilka sposobów na poinformowanie wyszukiwarek o dostępie do wszystkich plików, w tym posiadanie pustego pliku robots.txt lub jego braku.
Agent użytkownika: *
Uniemożliwić:
Brak dostępu dla wszystkich botów
Poniższy plik robots.txt instruuje wszystkie wyszukiwarki, aby unikały dostępu do całej witryny:
Agent użytkownika: *
Uniemożliwić: /
Zablokuj jeden podkatalog dla wszystkich botów
Agent użytkownika: *
Nie zezwalaj: /folder/
Zablokuj jeden podkatalog dla wszystkich botów (jeden plik w dozwolonym zakresie)
Agent użytkownika: *
Nie zezwalaj: /folder/
Zezwól: /folder/strona.html
Zablokuj jeden plik dla wszystkich botów
Agent użytkownika: *
Disallow: /to-jest-plik.pdf
Blokuj jeden typ pliku (PDF) dla wszystkich botów
Agent użytkownika: *
Odrzuć: /*.pdf$
Blokuj wszystkie sparametryzowane adresy URL tylko dla Googlebota
Klient użytkownika: Googlebot
Uniemożliwić: /*?
Jak przetestować plik robots.txt pod kątem błędów
Błędy w pliku Robots.txt mogą być poważne, dlatego ważne jest, aby je monitorować. Regularnie sprawdzaj raport „Pokrycie” w Search Console pod kątem problemów związanych z plikiem robot.txt. Poniżej wymieniono niektóre z błędów, które możesz napotkać, ich znaczenie i sposoby ich naprawy.
Przesłany adres URL zablokowany przez plik robots.txt
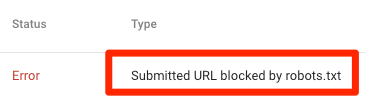
Wskazuje, że plik robots.txt zablokował co najmniej jeden z adresów URL w mapach witryn. Jeśli mapa witryny jest poprawna i nie zawiera stron kanonizowanych, nieindeksowanych ani przekierowanych, plik robots.txt nie powinien blokować żadnych wysyłanych stron. Jeśli tak, zidentyfikuj strony, których dotyczy problem, i usuń blokadę z pliku robots.txt.
Możesz użyć testera robots.txt Google, aby zidentyfikować dyrektywę blokującą. Zachowaj ostrożność podczas edytowania pliku robots.txt, ponieważ błąd może wpłynąć na inne strony lub pliki.
Zablokowany przez plik robots.txt
Ten błąd wskazuje, że plik robots.txt zablokował treści, których Google nie może zindeksować. Usuń blokadę indeksowania z pliku robots.txt, jeśli ta treść jest kluczowa i powinna zostać zindeksowana. (Sprawdź też, czy zawartość nie jest indeksowana).
Jeśli chcesz wykluczyć treść z indeksu Google, użyj metatagu robota lub x-robots-header i usuń blokadę indeksowania. To jedyny sposób na uniknięcie zawartości indeksu Google.
Zindeksowany, choć zablokowany przez robots.txt
Oznacza to, że Google nadal indeksuje część treści blokowanych przez plik robots.txt. Plik robots.txt nie jest rozwiązaniem zapobiegającym wyświetlaniu treści w wynikach wyszukiwania Google.
Aby zapobiec indeksowaniu, usuń blokadę indeksowania i zastąp ją metatagiem robots lub nagłówkiem HTTP x-robots-tag. Jeśli przypadkowo zablokowałeś tę treść i chcesz, aby Google ją zindeksował, usuń blokadę indeksowania z pliku robots.txt. Może pomóc w poprawie widoczności treści w wynikach wyszukiwania Google.
Robots.txt vs roboty meta vs roboty x
Co odróżnia te trzy polecenia robota? Robots.txt to prosty plik tekstowy, podczas gdy meta i x-robots to meta dyrektywy. Poza podstawowymi rolami te trzy mają różne funkcje. Robots.txt określa zachowanie indeksowania dla całej witryny lub katalogu, podczas gdy meta i x-robots definiują zachowanie indeksowania dla poszczególnych stron (lub elementów strony).
Dalsze czytanie
Przydatne zasoby
- Wikipedia: Protokół wykluczania robotów
- Dokumentacja Google dotycząca Robots.txt
- Dokumentacja Bing (i Yahoo) w pliku Robots.txt
- Wyjaśnienie dyrektyw
- Dokumentacja Yandex na temat Robots.txt
Zawijanie
Mamy nadzieję, że w pełni zrozumiałeś znaczenie pliku robot.txt i jego wkład w ogólną praktykę SEO i rentowność witryny. Jeśli nadal masz problemy z uzyskiwaniem dochodów ze swojej witryny, nie musisz kodować, aby zacząć zarabiać na reklamach Adsterra. Umieść kod reklamy w swojej witrynie HTML, WordPress lub Blogger i zacznij zarabiać już dziś!