
Melhores práticas e casos de uso para extração de dados do site
Publicados: 2023-12-28Ao extrair dados do site, é essencial respeitar os regulamentos e a estrutura do site de destino. A adesão às melhores práticas não é apenas uma questão de ética, mas também serve para evitar complicações legais e garantir a fiabilidade da extracção de dados. Aqui estão as principais considerações:
- Siga o robots.txt : sempre verifique este arquivo primeiro para entender o que o proprietário do site definiu como proibido para extração.
- Utilize APIs : se disponível, use a API oficial do site, que é um método mais estável e aprovado para acessar dados.
- Esteja atento às taxas de solicitação : a coleta excessiva de dados pode sobrecarregar os servidores do site, portanto, controle suas solicitações de maneira atenciosa.
- Identifique-se : por meio da string do agente do usuário, seja transparente sobre sua identidade e propósito ao fazer scraping.
- Manuseie os dados com responsabilidade : armazene e use dados copiados de acordo com as leis de privacidade e regulamentos de proteção de dados.
Seguir essas práticas garante a eliminação ética, mantendo a integridade e a disponibilidade do conteúdo online.
Compreendendo o Marco Legal
Ao extrair dados de um site, é crucial navegar pelas restrições legais interligadas. Os principais textos legislativos incluem:
- A Lei de Fraude e Abuso de Computadores (CFAA): Legislação nos Estados Unidos torna ilegal o acesso a um computador sem a devida autorização.
- Regulamento Geral de Proteção de Dados da União Europeia (GDPR) : exige o consentimento para o uso de dados pessoais e concede aos indivíduos o controle sobre seus dados.
- A Lei de Direitos Autorais do Milênio Digital (DMCA) : protege contra a distribuição de conteúdo protegido por direitos autorais sem permissão.
Os raspadores também devem respeitar os acordos de “termos de uso” dos sites, que muitas vezes limitam a extração de dados. Garantir a conformidade com essas leis e políticas é essencial para descartar dados de sites de maneira ética e legal.
Selecionando as ferramentas certas para raspagem
Escolher as ferramentas corretas é crucial ao iniciar um projeto de web scraping. Os fatores a serem considerados incluem:
- Complexidade do site : sites dinâmicos podem exigir ferramentas como Selenium, que podem interagir com JavaScript.
- Quantidade de dados : para raspagem em grande escala, são aconselháveis ferramentas com recursos de raspagem distribuída, como o Scrapy.
- Legalidade e Ética : Selecione ferramentas com recursos para respeitar o robots.txt e definir strings de agente do usuário.
- Facilidade de uso : os novatos podem preferir interfaces fáceis de usar encontradas em softwares como o Octoparse.
- Conhecimento de programação : os não programadores podem preferir software com GUI, enquanto os programadores podem optar por bibliotecas como BeautifulSoup.
Fonte da imagem: https://fastercapital.com/
Melhores práticas para extrair dados do site com eficácia
Para extrair dados do site de maneira eficiente e responsável, siga estas diretrizes:
- Respeite os arquivos robots.txt e os termos do site para evitar problemas legais.
- Use cabeçalhos e alterne os agentes do usuário para imitar o comportamento humano.
- Implemente atraso entre solicitações para reduzir a carga do servidor.
- Utilize proxies para evitar proibições de IP.
- Raspe fora dos horários de pico para minimizar a interrupção do site.
- Armazene sempre os dados de forma eficiente, evitando entradas duplicadas.
- Garanta a precisão dos dados extraídos com verificações regulares.
- Esteja atento às leis de privacidade de dados ao armazenar e usar dados.
- Mantenha suas ferramentas de scraping atualizadas para lidar com as alterações do site.
- Esteja sempre preparado para adaptar estratégias de scraping caso os sites atualizem sua estrutura.
Casos de uso de coleta de dados em todos os setores
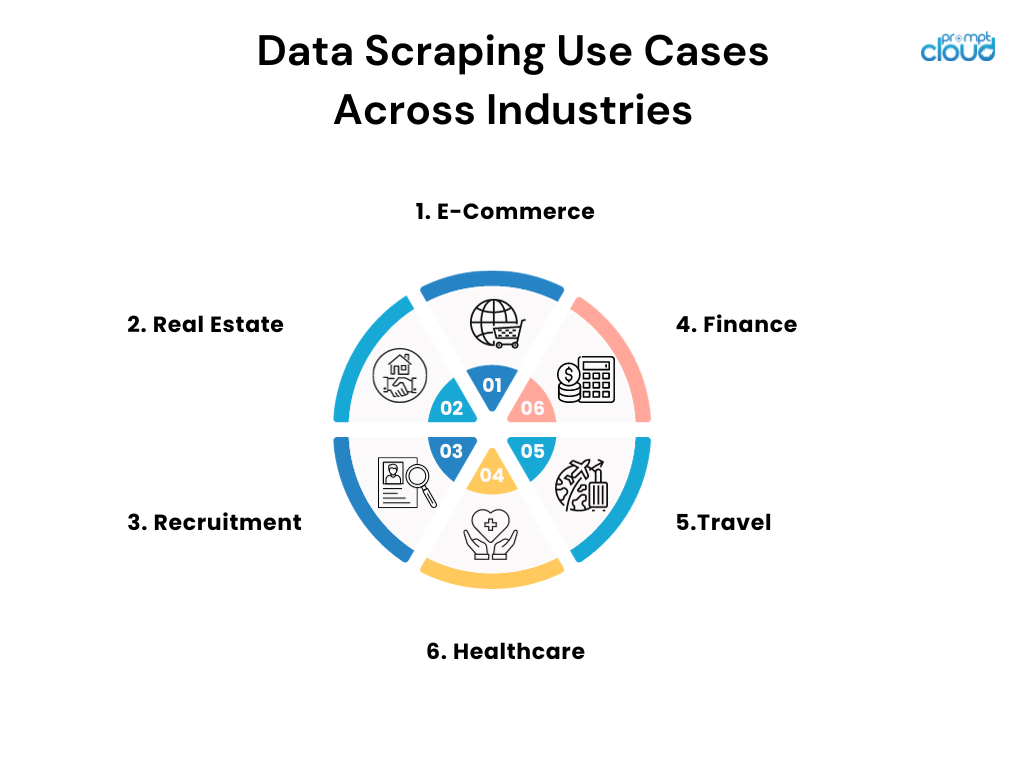
- Comércio eletrônico: Os varejistas on-line implantam o scraping para monitorar os preços dos concorrentes e ajustar suas estratégias de preços de acordo.
- Imobiliário: Agentes e empresas coletam listagens para agregar informações, tendências e dados de preços de propriedades de várias fontes.
- Recrutamento: As empresas vasculham os painéis de empregos e as redes sociais para encontrar candidatos potenciais e analisar as tendências do mercado de trabalho.
- Finanças: Os analistas coletam registros públicos e documentos financeiros para informar estratégias de investimento e acompanhar os sentimentos do mercado.
- Viagens: as agências reduzem os preços das companhias aéreas e dos hotéis para oferecer aos clientes as melhores ofertas e pacotes possíveis.
- Saúde: Os pesquisadores vasculham bancos de dados e periódicos médicos para se manterem atualizados sobre as últimas descobertas e ensaios clínicos.
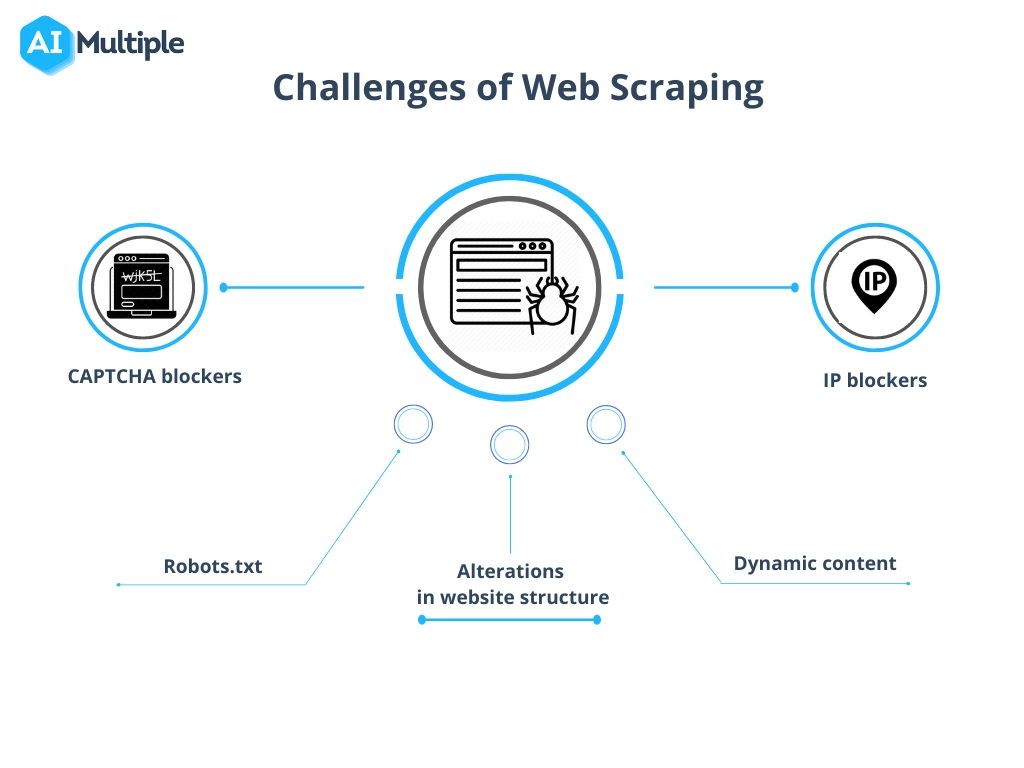
Enfrentando desafios comuns na extração de dados
O processo de extração de dados de um site, embora imensamente valioso, frequentemente envolve a superação de obstáculos como alterações na estrutura do site, medidas anti-raspagem e preocupações com a qualidade dos dados.

Fonte da imagem: https://research.aimultiple.com/
Para navegar neles de forma eficaz:
- Mantenha-se adaptável : atualize regularmente os scripts de raspagem para corresponder às atualizações do site. O uso do aprendizado de máquina pode ajudar na adaptação dinâmica às mudanças estruturais.
- Respeite os limites legais : entenda e cumpra as legalidades da raspagem para evitar litígios. Certifique-se de revisar o arquivo robots.txt e os termos de serviço em um site.
- Início do formulário
- Imitar a interação humana : os sites podem bloquear scrapers que enviam solicitações muito rapidamente. Implemente atrasos e intervalos aleatórios entre solicitações para parecer menos robótico.
- Lidar com CAPTCHAs : Estão disponíveis ferramentas e serviços que podem resolver ou contornar os CAPTCHAs, embora seu uso deva ser considerado em relação às implicações éticas e legais.
- Manter a integridade dos dados : Garanta a precisão dos dados extraídos. Valide regularmente os dados e limpe-os para manter a qualidade e a utilidade.
Essas estratégias ajudam a superar obstáculos comuns e facilitam a extração de dados valiosos.
Conclusão
A extração eficiente de dados de sites é um método valioso com diversas aplicações, que vão desde pesquisas de mercado até análises competitivas. É essencial aderir às melhores práticas, garantindo a legalidade, respeitando as diretrizes do robots.txt e controlando cuidadosamente a frequência de scraping para evitar sobrecarga do servidor.
A aplicação responsável desses métodos abre a porta para fontes de dados ricas que podem fornecer insights acionáveis e impulsionar a tomada de decisões informadas para empresas e indivíduos. A implementação adequada, juntamente com considerações éticas, garante que a recolha de dados continue a ser uma ferramenta poderosa no cenário digital.
Pronto para turbinar seus insights coletando dados do site? Não procure mais! PromptCloud oferece serviços de web scraping éticos e confiáveis, adaptados às suas necessidades. Conecte-se conosco em sales@promptcloud.com para transformar dados brutos em inteligência acionável. Vamos aprimorar sua tomada de decisão juntos!
perguntas frequentes
É aceitável extrair dados de sites?
Com certeza, a coleta de dados é aceitável, mas você precisa seguir as regras. Antes de mergulhar em qualquer aventura de scraping, dê uma boa olhada nos termos de serviço e no arquivo robots.txt do site em questão. Mostrar algum respeito pelo layout do site, respeitar os limites de frequência e manter as coisas éticas são fundamentais para práticas responsáveis de coleta de dados.
Como posso extrair dados do usuário de um site por meio de scraping?
A extração de dados do usuário por meio de scraping requer uma abordagem meticulosa em alinhamento com as normas legais e éticas. Sempre que possível, é recomendado aproveitar APIs disponíveis publicamente fornecidas pelo site para recuperação de dados. Na ausência de uma API, é imperativo garantir que os métodos de scraping empregados cumpram as leis de privacidade, os termos de uso e as políticas estabelecidas pelo site para mitigar possíveis ramificações legais.
A coleta de dados do site é considerada ilegal?
A legalidade do web scraping depende de vários fatores, incluindo a finalidade, a metodologia e a conformidade com as leis pertinentes. Embora o web scraping em si não seja inerentemente ilegal, o acesso não autorizado, a violação dos termos de serviço de um site ou o desrespeito às leis de privacidade podem levar a consequências legais. A conduta responsável e ética nas atividades de web scraping é fundamental, envolvendo uma profunda consciência dos limites legais e das considerações éticas.
Os sites podem detectar instâncias de web scraping?
Os sites implementaram mecanismos para detectar e prevenir atividades de web scraping, monitorando elementos como strings de agente de usuário, endereços IP e padrões de solicitação. Para mitigar a detecção, as melhores práticas incluem o emprego de técnicas como rotação de agentes de usuário, utilização de proxies e implementação de atrasos aleatórios entre solicitações. No entanto, é crucial observar que as tentativas de contornar as medidas de detecção podem violar os termos de serviço de um website e potencialmente resultar em consequências legais. Práticas responsáveis e éticas de web scraping priorizam a transparência e a adesão aos padrões legais e éticos.