
Técnicas eficazes de rastreamento da Web para aplicativos de Big Data
Publicados: 2024-06-06Na era do big data, o rastreamento de sites surgiu como um processo indispensável para as empresas que desejam aproveitar a vasta riqueza de informações disponíveis online. Ao coletar, processar e analisar dados da Web em escala e com eficiência, as empresas podem desbloquear insights valiosos e obter vantagem competitiva em vários setores.
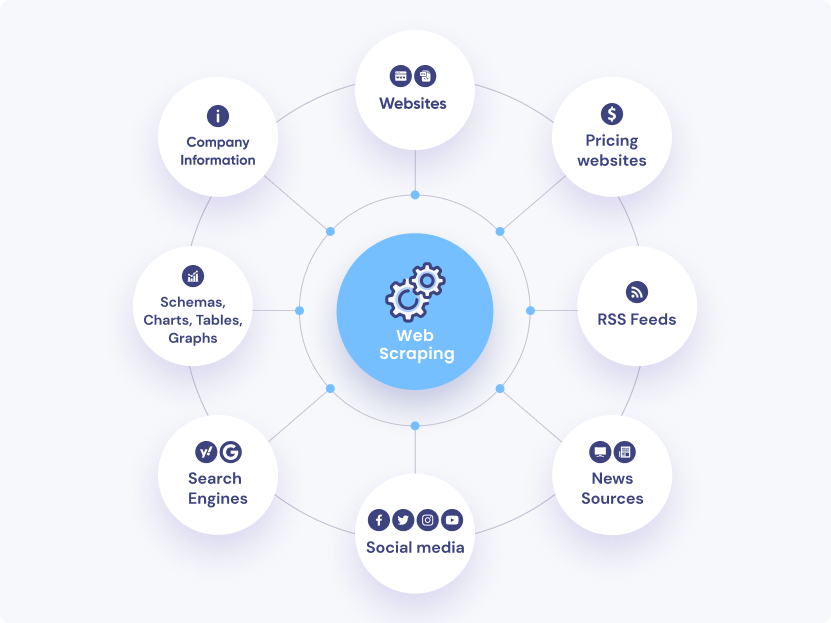
Os dados da Web possuem um potencial imenso, oferecendo insights profundos sobre tendências de mercado, comportamento do consumidor e cenários competitivos. A capacidade de coletar e analisar esses dados com eficiência pode transformar informações brutas em inteligência acionável, impulsionando a tomada de decisões estratégicas e o crescimento dos negócios.
Fonte: scrapehero
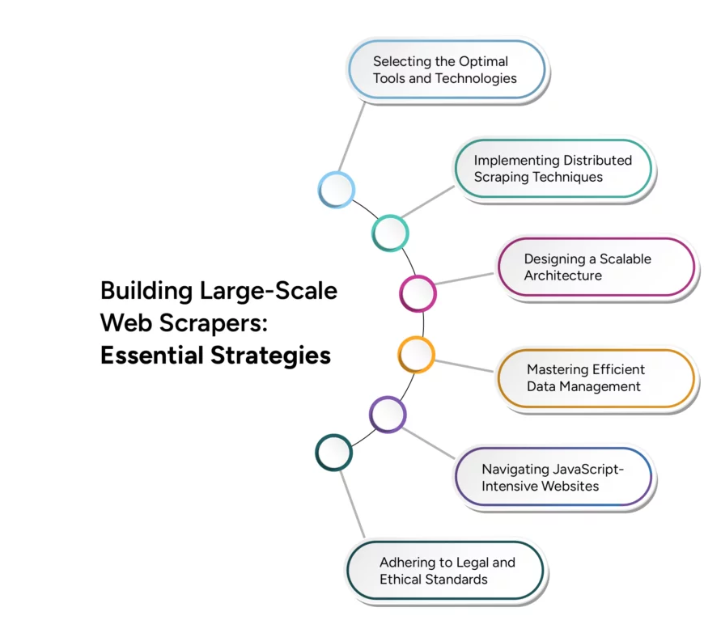
No entanto, a transição do web scraping em pequena escala para o web crawling em grande escala apresenta desafios técnicos significativos. O dimensionamento eficaz requer uma consideração cuidadosa de vários fatores, incluindo infraestrutura, gerenciamento de dados e eficiência de processamento. Este artigo investiga técnicas e estratégias avançadas necessárias para superar esses desafios, garantindo que suas operações de rastreamento da Web possam crescer para atender às demandas de aplicativos de big data.
Desafios do rastreamento de sites para aplicativos de Big Data
O rastreamento de sites para aplicações de big data apresenta vários desafios significativos que as empresas devem enfrentar para aproveitar de forma eficaz o poder da vasta informação online. Compreender e superar esses desafios é crucial para construir uma infraestrutura de rastreamento da web robusta e escalável.
Um dos principais desafios é o grande volume e variedade de dados na web, que continua a crescer exponencialmente. Além disso, a diversidade de tipos de dados, desde texto e imagens até vídeos e conteúdo dinâmico, adiciona complexidade ao processo de rastreamento de sites. Sites modernos costumam usar conteúdo dinâmico gerado por JavaScript e AJAX, dificultando
rastreadores tradicionais para capturar todas as informações relevantes. Além disso, os websites podem impor limites de taxas ou bloquear endereços IP para evitar rastreamento excessivo, o que pode atrapalhar os esforços de coleta de dados.
Garantir a precisão e a consistência dos dados recolhidos de várias fontes pode ser difícil, especialmente quando se lida com grandes conjuntos de dados. Dimensionar as operações de rastreamento da Web para lidar com cargas crescentes de dados sem comprometer o desempenho é um grande desafio técnico. Além disso, aderir às diretrizes legais e éticas para rastrear sites é crucial para evitar possíveis problemas legais e manter uma boa reputação. O gerenciamento eficiente dos recursos de computação para equilibrar a velocidade de rastreamento e a economia também é fundamental.
Técnicas para extração eficiente de dados
A implementação de técnicas avançadas de extração de dados garante que os dados coletados sejam relevantes, precisos e prontos para análise. Aqui estão algumas técnicas importantes para aumentar a eficiência da extração de dados:
- Processamento Paralelo : Utilize o processamento paralelo para distribuir tarefas de extração de dados em vários threads ou máquinas, aumentando a velocidade da extração de dados ao lidar com diversas solicitações simultaneamente e reduzindo o tempo total necessário para coletar dados.
- Rastreamento Incremental : Implemente o rastreamento incremental para atualizar apenas as partes do conjunto de dados que foram alteradas desde o último rastreamento, reduzindo a quantidade de dados processados e a carga nos servidores web, tornando o processo de rastreamento mais eficiente e que consome menos recursos.
- Navegadores sem cabeça : use navegadores sem cabeça como Puppeteer ou Selenium para renderizar e interagir com conteúdo dinâmico da web, permitindo a extração precisa de dados de sites que dependem fortemente de JavaScript e AJAX, garantindo uma coleta de dados abrangente.
- Priorização de conteúdo : Priorize o conteúdo com base na relevância e importância, concentrando-se primeiro em dados de alto valor, garantindo que os dados mais críticos sejam coletados prontamente e otimizando a utilização de recursos e a relevância dos dados.
- Políticas de agendamento e polidez de URL : Implemente políticas inteligentes de agendamento e polidez de URL para gerenciar a frequência de solicitações a um único servidor, evitando a sobrecarga de servidores web e reduzindo o risco de bloqueio de IP, garantindo acesso sustentado às fontes de dados.
- Desduplicação de dados : Empregue técnicas de desduplicação de dados para eliminar entradas duplicadas durante o processo de extração, melhorando a qualidade dos dados e reduzindo os requisitos de armazenamento, garantindo que apenas dados exclusivos sejam armazenados e processados.
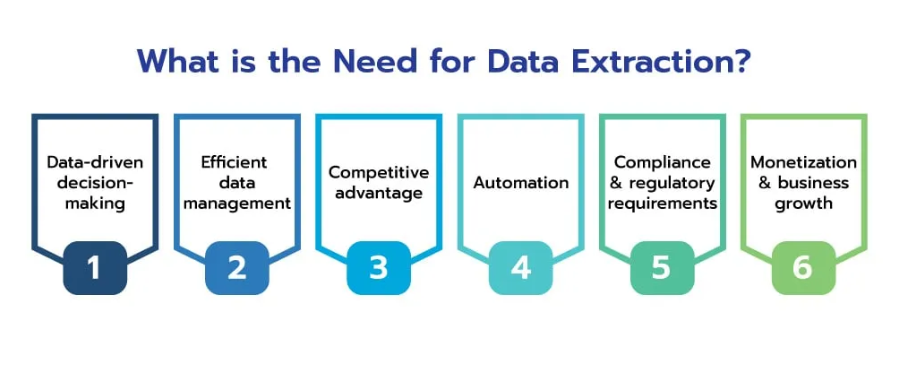
Soluções de rastreamento da Web em tempo real
Fonte: Médio

No cenário digital acelerado de hoje, a capacidade de extrair e processar dados em tempo real é
crucial para as empresas que procuram manter uma vantagem competitiva. As soluções de rastreamento da web em tempo real permitem a coleta contínua e instantânea de dados, permitindo análise e ação imediatas. A implementação de uma arquitetura orientada a eventos pode melhorar significativamente os recursos em tempo real, onde os rastreadores são acionados por eventos ou alterações específicas na web, garantindo que os dados sejam coletados assim que estiverem disponíveis.
Escalabilidade em rastreamento da Web multilíngue
A natureza global da Internet exige a capacidade de rastrear e processar dados em vários idiomas, apresentando desafios únicos que exigem soluções especializadas. As operações de rastreamento de sites para lidar com conteúdo multilíngue envolvem a implementação de algoritmos de detecção de idioma para identificar automaticamente o idioma das páginas da web e garantir que as técnicas de processamento apropriadas e específicas do idioma sejam aplicadas. O uso de bibliotecas e estruturas de análise que suportam múltiplas linguagens, como BeautifulSoup, fornece ferramentas robustas para extrair conteúdo de diversas páginas da web. A integração de serviços de tradução escalonáveis, como o Google Cloud Translation, ao pipeline de processamento de dados permite a tradução de conteúdo em tempo real, permitindo uma análise perfeita em diferentes idiomas.
Conclusão
Fonte: grupobwt
À medida que avançamos na era digital, a importância de rastrear websites para aplicações de big data continua a crescer. O futuro do rastreamento da web reside na sua capacidade de escalar com eficiência, adaptar-se a ambientes dinâmicos da web e fornecer insights em tempo real. Os avanços na inteligência artificial e na aprendizagem automática desempenharão um papel fundamental no aprimoramento das capacidades dos rastreadores da Web, tornando-os mais inteligentes e eficientes no processamento de grandes quantidades de dados.
A integração de sistemas distribuídos e infraestruturas baseadas em nuvem melhorará ainda mais a escalabilidade, permitindo que as empresas lidem com facilidade com conjuntos de dados cada vez maiores. À medida que as tecnologias de rastreamento da Web continuam a evoluir, elas não só melhorarão os processos de recolha de dados, mas também garantirão que as empresas possam manter uma vantagem competitiva num cenário digital em constante mudança.
Adotar estes avanços não é apenas uma opção, mas uma necessidade para as organizações que pretendem aproveitar eficazmente o big data. O futuro do rastreamento da web promete ser uma força transformadora, impulsionando a inovação e fornecendo as ferramentas necessárias para desbloquear todo o potencial do vasto ecossistema de dados da web.
Leve seus aplicativos de big data para o próximo nível com os serviços personalizáveis de web scraping do PromptCloud com integração e escalabilidade perfeitas. Contate-nos hoje para aproveitar o poder do rastreamento avançado da web para o seu negócio.