
Raspagem dinâmica de páginas da Web com Python – guia prático
Publicados: 2024-06-08Web scraping dinâmico envolve a recuperação de dados de sites que geram conteúdo em tempo real por meio de JavaScript ou Python. Ao contrário das páginas da web estáticas, o conteúdo dinâmico é carregado de forma assíncrona, tornando as técnicas tradicionais de scraping ineficientes.
Usos de web scraping dinâmico:
- Sites baseados em AJAX
- Aplicativos de página única (SPAs)
- Sites com elementos de carregamento atrasado
Principais ferramentas e tecnologias:
- Selenium – Automatiza as interações do navegador.
- BeautifulSoup – Analisa conteúdo HTML.
- Solicitações – busca o conteúdo da página da web.
- lxml – Analisa XML e HTML.
O python de web scraping dinâmico requer uma compreensão mais profunda das tecnologias da web para coletar dados em tempo real com eficácia.
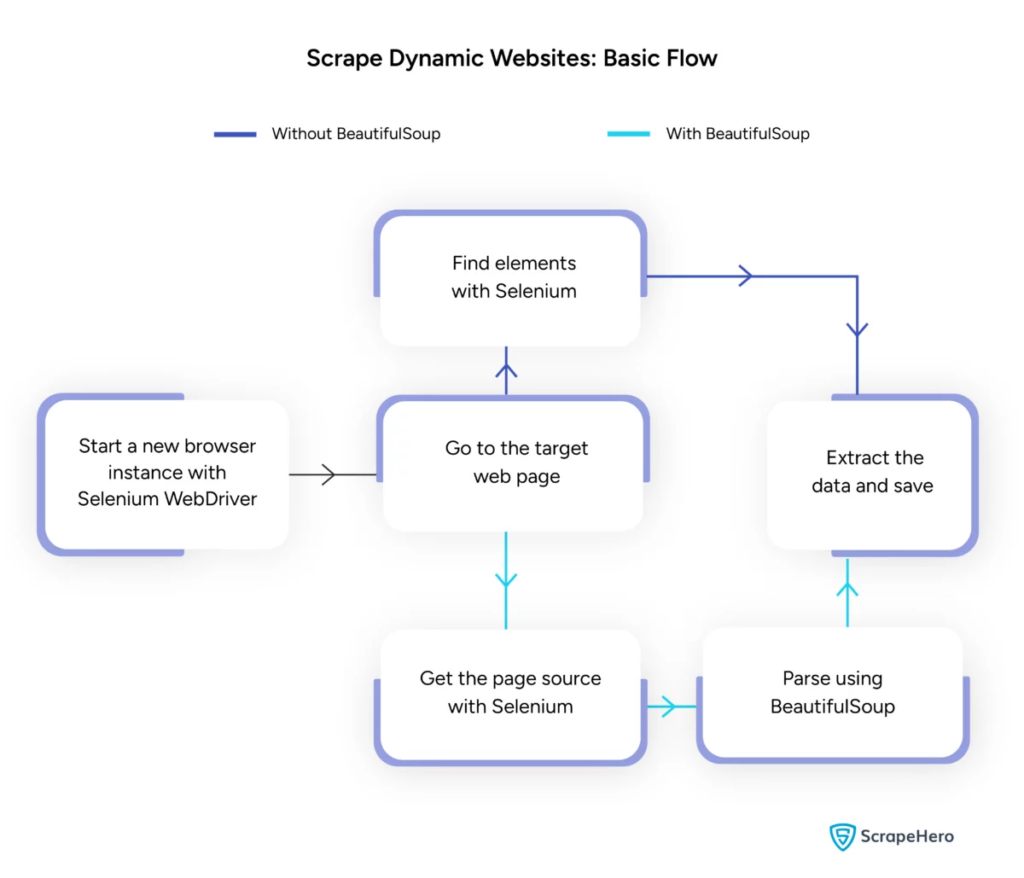
Fonte da imagem: https://www.scrapehero.com/scrape-a-dynamic-website/
Configurando o ambiente Python
Para iniciar o web scraping dinâmico em Python, é essencial configurar o ambiente corretamente. Siga esses passos:
- Instale o Python : certifique-se de que o Python esteja instalado na máquina. A versão mais recente pode ser baixada do site oficial do Python.
- Crie um ambiente virtual :

Ative o ambiente virtual:

- Instale as bibliotecas necessárias :

- Configure um editor de código : use um IDE como PyCharm, VSCode ou Jupyter Notebook para escrever e executar scripts.
- Familiarize-se com HTML/CSS : Compreender a estrutura da página da web ajuda a navegar e extrair dados de maneira eficaz.
Essas etapas estabelecem uma base sólida para projetos python de web scraping dinâmico.
Compreendendo os princípios básicos das solicitações HTTP
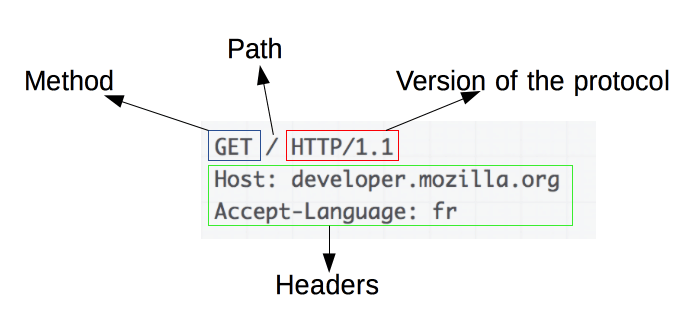
Fonte da imagem: https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview
As solicitações HTTP são a base do web scraping. Quando um cliente, como um navegador ou web scraper, deseja recuperar informações de um servidor, ele envia uma solicitação HTTP. Essas solicitações seguem uma estrutura específica:
- Método : A ação a ser executada, como GET ou POST.
- URL : o endereço do recurso no servidor.
- Cabeçalhos : metadados sobre a solicitação, como tipo de conteúdo e agente do usuário.
- Corpo : dados opcionais enviados com a solicitação, normalmente usados com POST.
Compreender como interpretar e construir esses componentes é essencial para uma web scraping eficaz. Bibliotecas Python como solicitações simplificam esse processo, permitindo controle preciso sobre as solicitações.
Instalando bibliotecas Python
Fonte da imagem: https://ajaytech.co/what-are-python-libraries/
Para web scraping dinâmico com Python, certifique-se de que o Python esteja instalado. Abra o terminal ou prompt de comando e instale as bibliotecas necessárias usando pip:
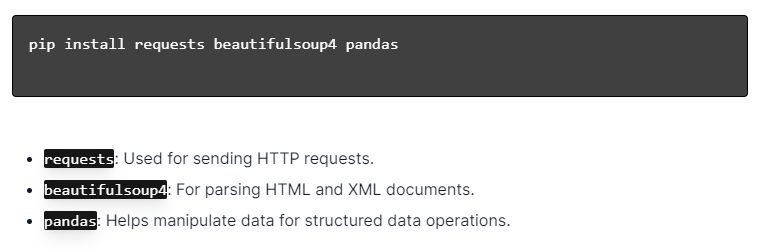
A seguir, importe essas bibliotecas para o seu script:

Ao fazer isso, cada biblioteca ficará disponível para tarefas de web scraping, como envio de solicitações, análise de HTML e gerenciamento eficiente de dados.
Construindo um script simples de web scraping
Para construir um script básico de web scraping dinâmico em Python, é necessário primeiro instalar as bibliotecas necessárias. A biblioteca “requests” lida com solicitações HTTP, enquanto “BeautifulSoup” analisa o conteúdo HTML.
Passos a seguir:
- Instalar dependências:

- Importar bibliotecas:

- Obtenha conteúdo HTML:
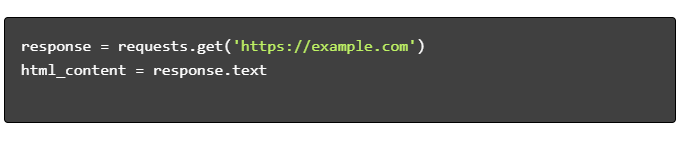
- Analisar HTML:

- Extrair dados:

Lidando com Web Scraping Dinâmico com Python
Sites dinâmicos geram conteúdo dinamicamente, muitas vezes exigindo técnicas mais sofisticadas.

Considere as seguintes etapas:
- Identifique os elementos de destino : inspecione a página da web para localizar o conteúdo dinâmico.
- Escolha uma estrutura Python : utilize bibliotecas como Selenium ou Playwright.
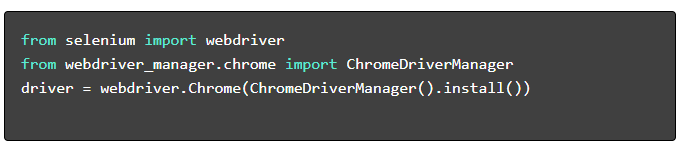
- Instale os pacotes necessários :
- Configure o WebDriver :

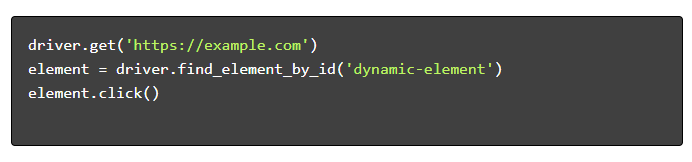
- Navegue e interaja :
Práticas recomendadas para raspagem na Web
É recomendado seguir as melhores práticas de web scraping para garantir eficiência e legalidade. Abaixo estão as principais diretrizes e estratégias de tratamento de erros:
- Respeite Robots.txt : sempre verifique o arquivo robots.txt do site de destino.
- Limitação : implemente atrasos para evitar sobrecarga do servidor.
- User-Agent : Use uma string User-Agent personalizada para evitar possíveis bloqueios.
- Lógica de nova tentativa : use blocos try-except e configure a lógica de nova tentativa para lidar com tempos limite do servidor.
- Registro em log : mantenha registros abrangentes para depuração.
- Tratamento de exceções : captura especificamente erros de rede, erros de HTTP e erros de análise.
- Detecção de Captcha : Incorpore estratégias para detectar e resolver ou contornar CAPTCHAs.
Desafios comuns de web scraping dinâmico
Captchas
Muitos sites usam CAPTCHAs para prevenir bots automatizados. Para contornar isso:
- Use serviços de resolução de CAPTCHA como 2Captcha.
- Implementar intervenção humana para resolução de CAPTCHA.
- Use proxies para limitar as taxas de solicitação.
Bloqueio de IP
Os sites podem bloquear IPs fazendo muitas solicitações. Contrarie isso:
- Usando proxies rotativos.
- Implementando a limitação de solicitações.
- Empregar estratégias de rotação usuário-agente.
Renderização JavaScript
Alguns sites carregam conteúdo via JavaScript. Enfrente este desafio:
- Usando Selenium ou Puppeteer para automação do navegador.
- Empregando Scrapy-splash para renderizar conteúdo dinâmico.
- Explorando navegadores headless para interagir com JavaScript.
Questões legais
Às vezes, a raspagem da Web pode violar os termos de serviço. Garanta a conformidade:
- Consultoria assessoria jurídica.
- Raspar dados acessíveis ao público.
- Honrando as diretivas do robots.txt.
Análise de dados
Lidar com estruturas de dados inconsistentes pode ser um desafio. As soluções incluem:
- Usando bibliotecas como BeautifulSoup para análise de HTML.
- Empregando expressões regulares para extração de texto.
- Utilizando analisadores JSON e XML para dados estruturados.
Armazenando e analisando dados extraídos
Armazenar e analisar dados copiados são etapas cruciais no web scraping. A decisão de onde armazenar os dados depende do volume e do formato. As opções de armazenamento comuns incluem:
- Arquivos CSV : fáceis para pequenos conjuntos de dados e análises simples.
- Bancos de dados : bancos de dados SQL para dados estruturados; NoSQL para não estruturado.
Depois de armazenados, a análise dos dados pode ser realizada usando bibliotecas Python:
- Pandas : Ideal para manipulação e limpeza de dados.
- NumPy : Eficiente para operações numéricas.
- Matplotlib e Seaborn : Adequado para visualização de dados.
- Scikit-learn : Fornece ferramentas para aprendizado de máquina.
O armazenamento e a análise adequados de dados melhoram a acessibilidade e os insights dos dados.
Conclusão e próximos passos
Depois de percorrer um web scraping dinâmico em Python, é fundamental ajustar o entendimento das ferramentas e bibliotecas destacadas.
- Revise o código : consulte o script final e modularize sempre que possível para aumentar a reutilização.
- Bibliotecas adicionais : explore bibliotecas avançadas como Scrapy ou Splash para necessidades mais complexas.
- Armazenamento de dados : considere opções robustas de armazenamento – bancos de dados SQL ou armazenamento em nuvem para gerenciar grandes conjuntos de dados.
- Considerações legais e éticas : mantenha-se atualizado sobre as diretrizes legais sobre web scraping para evitar possíveis infrações.
- Próximos projetos : Lidar com novos projetos de web scraping com complexidades diferentes consolidará ainda mais essas habilidades.
Procurando integrar web scraping dinâmico profissional com Python em seu projeto? Para aquelas equipes que necessitam de extração de dados em alta escala sem a complexidade de lidar com eles internamente, a PromptCloud oferece soluções personalizadas. Explore os serviços da PromptCloud para obter uma solução robusta e confiável. Contate-nos hoje!