
Análise Fatorial Exploratória em R
Publicados: 2017-02-16O que é análise fatorial exploratória em R?
A Análise Fatorial Exploratória (EFA) ou mais ou menos conhecida como análise fatorial em R é uma técnica estatística que é usada para identificar a estrutura relacional latente entre um conjunto de variáveis e reduzi-la a um número menor de variáveis. Isso significa essencialmente que a variância de um grande número de variáveis pode ser descrita por algumas variáveis resumidas, ou seja, fatores. Aqui está uma visão geral da análise fatorial exploratória em R.
Como o nome sugere, a EFA é de natureza exploratória – não conhecemos realmente as variáveis latentes, e as etapas são repetidas até chegarmos a um número menor de fatores. Neste tutorial, veremos o EFA usando R. Agora, vamos primeiro obter a ideia básica do conjunto de dados.
1. Os Dados
Este conjunto de dados contém 90 respostas para 14 variáveis diferentes que os clientes consideram ao comprar um carro. As perguntas da pesquisa foram estruturadas usando uma escala Likert de 5 pontos, sendo 1 muito baixo e 5 muito alto. As variaveis foram as seguintes:
- Preço
- Segurança
- Aparência externa
- Espaço e conforto
- Tecnologia
- Serviço pós-venda
- Valor de revenda
- Tipo de combustível
- Eficiência do combustível
- Cor
- Manutenção
- Passeio de teste
- Revisão de produtos
- Depoimentos
Clique aqui para baixar o conjunto de dados codificado.
2. Importando WebData
Agora vamos ler o conjunto de dados presente no formato CSV em R e armazená-lo como uma variável.
[code language=”r”] dados <- read.csv(file.choose( ),header=TRUE) [/code]
Abrirá uma janela para escolher o arquivo CSV e a opção `header` garantirá que a primeira linha do arquivo seja considerada o cabeçalho. Digite o seguinte para ver as primeiras linhas do quadro de dados e confirme se os dados foram armazenados corretamente.
[code language=”r”] head(data) [/code]
3. Instalação do Pacote
Agora vamos instalar os pacotes necessários para realizar uma análise mais aprofundada. Esses pacotes são `psych` e `GPArotation`. No código abaixo, estamos chamando `install.packages()` para instalação.
[code language=”r”] install.packages('psych') install.packages('GPArotation') [/code]
4. Número de Fatores
Em seguida, descobriremos o número de fatores que selecionaremos para a análise fatorial. Isso é avaliado através de métodos como `Análise Paralela` e `valor próprio`, etc.
Análise paralela
Estaremos usando a função `fa.parallel` do pacote `Psych` para executar a análise paralela. Aqui especificamos o data frame e o método do fator (`minres` no nosso caso). Execute o seguinte para encontrar um número aceitável de fatores e gerar o `scree plot`:
[code language=”r”] paralelo <- fa.parallel(data, fm = 'minres', fa = 'fa') [/code]
O console mostraria o número máximo de fatores que podemos considerar. Aqui está como ficaria.
“A análise paralela sugere que o número de fatores = 5 e o número de componentes = NA“
Dado abaixo no `scree plot` gerado a partir do código acima:
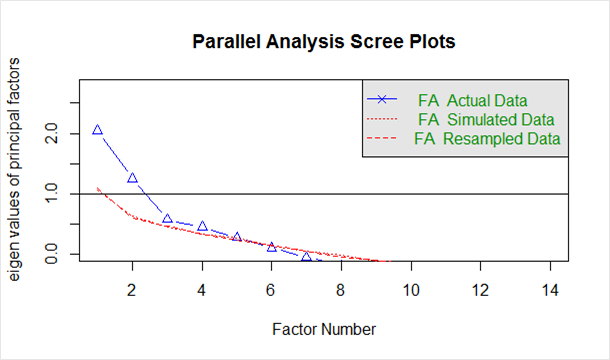
A linha azul mostra os autovalores dos dados reais e as duas linhas vermelhas (colocadas uma em cima da outra) mostram os dados simulados e reamostrados. Aqui, observamos as grandes quedas nos dados reais e identificamos o ponto em que ele se nivela à direita. Além disso, localizamos o ponto de inflexão – o ponto em que a lacuna entre os dados simulados e os dados reais tende a ser mínima.

Olhando para este gráfico e análise paralela, em qualquer lugar entre 2 a 5 fatores seria uma boa escolha.
Análise Fatorial
Agora que chegamos a um número provável de fatores, vamos começar com 3 como o número de fatores. Para realizar a análise fatorial, usaremos a função `psych` packages`fa(). Abaixo estão os argumentos que forneceremos:
- r – Dados brutos ou matriz de correlação ou covariância
- nfactors – Número de fatores para extrair
- girar – Embora existam vários tipos de rotações, `Varimax` e `Oblimin` são os mais populares
- fm – Uma das técnicas de extração de fatores como `Mínimo Residual (OLS)`, `Maximum Liklihood`, `Principal Axis` etc.
Neste caso, selecionaremos a rotação oblíqua (rotate = “oblimin”), pois acreditamos que existe uma correlação nos fatores. Observe que a rotação Varimax é usada sob a suposição de que os fatores são completamente não correlacionados. Usaremos a fatoração `Mínimo Quadrado Ordinário/Minres` (fm = “minres”), pois é conhecido por fornecer resultados semelhantes a `Probabilidade Máxima` sem assumir uma distribuição normal multivariada e derivar soluções por meio de autodecomposição iterativa como um eixo principal.
Execute o seguinte para iniciar a análise.
[linguagem de código=”r”] três fatores <- fa(data,nfactors = 3, girar = “oblimin”,fm=”minres”) print(threefactor) [/code]
Aqui está a saída mostrando fatores e carregamentos:
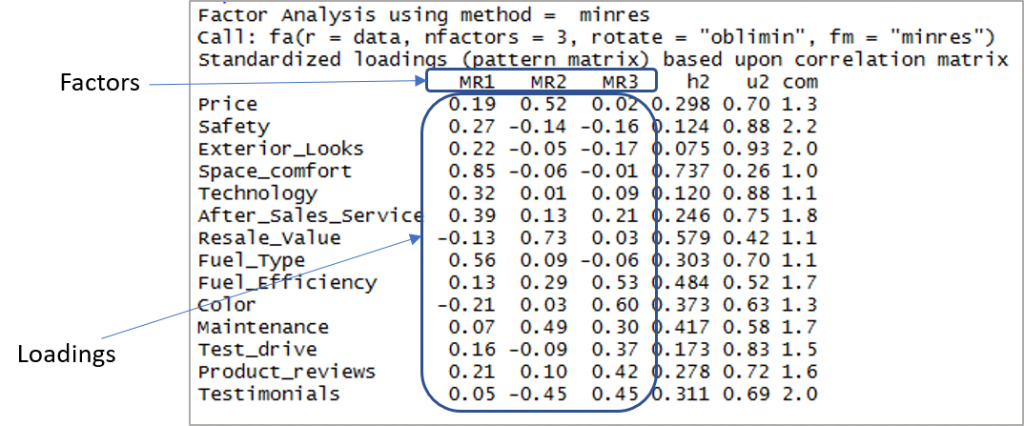
Agora precisamos considerar as cargas de mais de 0,3 e não carregar em mais de um fator. Observe que valores negativos são aceitáveis aqui. Então, vamos primeiro estabelecer o corte para melhorar a visibilidade.
[code language=”r”] print(threefactor$loadings,cutoff = 0.3) [/code]
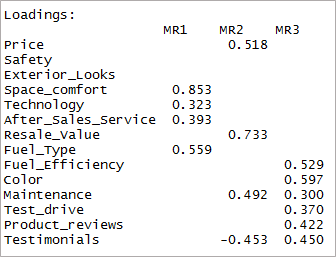
Como você pode ver, duas variáveis se tornaram insignificantes e outras duas têm carregamento duplo. A seguir, consideraremos os '4' fatores.
[linguagem de código=”r”] fourfactor <- fa(data,nfactors = 4, girar = “oblimin”,fm=”minres”) print(fourfactor$loadings,cutoff = 0.3) [/code]
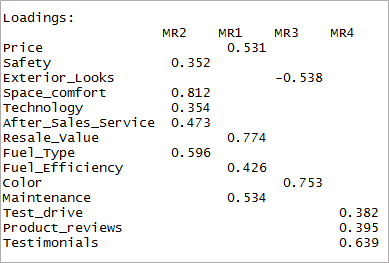
Podemos ver que isso resulta em apenas um único carregamento. Isso é conhecido como estrutura simples.
Clique no seguinte para ver o mapeamento de fatores.
[code language=”r”] fa.diagram(fourfactor) [/code]
Teste de adequação
Agora que alcançamos uma estrutura simples, é hora de validarmos nosso modelo. Vejamos a saída da análise fatorial para prosseguir.

A raiz significa que o quadrado dos resíduos (RMSR) é 0,05. Isso é aceitável, pois esse valor deve estar mais próximo de 0. Em seguida, devemos verificar o índice RMSEA (root mean square error of approximation). Seu valor, 0,001 mostra um bom ajuste do modelo, pois está abaixo de 0,05. Por fim, o Índice Tucker-Lewis (TLI) é 0,93 – um valor aceitável considerando que está acima de 0,9.
Nomeando os Fatores

Após estabelecer a adequação dos fatores, é hora de nomearmos os fatores. Este é o lado teórico da análise onde formamos os fatores dependendo das cargas variáveis. Neste caso, aqui está como os fatores podem ser criados.
Conclusão
Neste tutorial para análise em r, discutimos a ideia básica da EFA (análise fatorial exploratória em R), abordamos a análise paralela e a interpretação do scree plot. Em seguida, passamos para a análise fatorial em R para obter uma estrutura simples e validar a mesma para garantir a adequação do modelo. Finalmente chegou aos nomes dos fatores das variáveis. Agora vá em frente, experimente e poste suas descobertas na seção de comentários.