
A Voz do Bazar
Publicados: 2024-04-24Este artigo sobre modernização de sistemas legados é um complemento de uma palestra que apresentei recentemente no AWS Data Summit para empresas de software sobre como gerar valor a partir de dados, aproveitando nossas práticas recomendadas para garantir o sucesso em projetos de aprendizado de máquina. Você pode pular direto aqui para assistir, se preferir.
Sejamos realistas: software é mais fácil de escrever do que manter. É por isso que nós, como engenheiros de software, preferimos simplesmente “arrancá-lo e começar de novo” em vez de tentar entender o que outro desenvolvedor (ou nosso eu passado) estava pensando. Parecemos ter esquecido coletivamente que “os programas devem ser escritos para as pessoas lerem e apenas incidentalmente para as máquinas executarem”.
Você sabe que é verdade - todos nós tivemos que rastrear meticulosamente uma caçarola de código espaguete e abstrações finas do velho mundo procurando a essência do programa apenas para encontrar nada além de uma bagunça no fundo de nossos pratos.
É fácil gritar “WTF” e culpar o desenvolvedor anterior, mas a verdade costuma ser mais complicada. Não podemos ver o futuro, por isso é impossível entender como os requisitos, a tecnologia ou as metas de negócios crescerão quando projetarmos um novo sistema. Como resultado, os sistemas podem tornar-se ilegíveis à medida que o seu âmbito aumenta juntamente com a dependência dos negócios relativamente a eles. Isto é um pouco paradoxal: sistemas mais antigos e mais difíceis de manter geralmente fornecem o maior valor. É difícil trabalhar neles porque cresceram com a empresa, e assustador porque quebrá-los pode ser uma catástrofe.
É aqui que estou chamando você: se você gosta de problemas difíceis e gratificantes... experimente. Pegue o sistema mais antigo que você possui e torne-o sustentável. Você sabe de quem estou falando - aquele que ninguém “possuirá”. Aquele do qual os outros departamentos dependem, mas os engenheiros odeiam. Aquele em que você teve que corrigir o Log4Shell primeiro . Faça isso. Atreva-se.
Recentemente, tive a oportunidade de atualizar um sistema de aprendizado de máquina com uma década de existência no Bazaarvoice. Superficialmente, não parecia empolgante : essa coisa nem tinha redes neurais! Quem se importa! Bem... isso importava. Este sistema processa quase todas as análises de produtos geradas por usuários recebidas pelo Bazaarvoice – quase 9 milhões por mês – e faz isso com 90 milhões de chamadas de inferência para modelos de aprendizado de máquina. Sim – 90 milhões de inferências! É uma escala enorme e eu mal podia esperar para mergulhar nisso.
Neste post, compartilharei como a modernização desse sistema legado por meio de uma rearquitetura, em vez de uma reescrita, nos permitiu torná-lo escalonável e econômico, sem precisar extrair todo o código e começar de novo. O sistema resultante não tem servidor, é conteinerizado e pode ser mantido, ao mesmo tempo que reduz nossos custos de hospedagem em quase 80%.
O que é um sistema legado?
Um sistema legado refere-se a software e/ou hardware de computação obsoleto que permanece em operação. Embora ainda possa cumprir o seu propósito original, falta-lhe escalabilidade para crescimento futuro.
Sistemas legados antigos
Primeiro, vamos dar uma olhada no que estamos lidando aqui. O sistema legado que minha equipe estava atualizando modera o conteúdo gerado pelo usuário para todo o Bazaarvoice. Especificamente, determina se cada conteúdo é apropriado para os sites de nossos clientes.

Isso parece simples – eliminar infrações óbvias, como discurso de ódio, linguagem obscena ou solicitações – mas, na prática, é muito mais sutil. Cada cliente tem requisitos únicos para o que considera apropriado. As marcas de cerveja, por exemplo, esperariam discussões sobre álcool, mas uma marca infantil talvez não. Capturamos essas opções específicas do cliente quando integramos novos clientes, e nossa equipe de atendimento ao cliente as codifica em um banco de dados de gerenciamento.
Para aumentar a complexidade, também testamos um subconjunto de nosso conteúdo para ser moderado por moderadores humanos. Isso nos permite medir continuamente o desempenho dos nossos modelos e descobrir oportunidades para construir mais modelos.
A arquitetura completa do nosso sistema legado é mostrada abaixo:
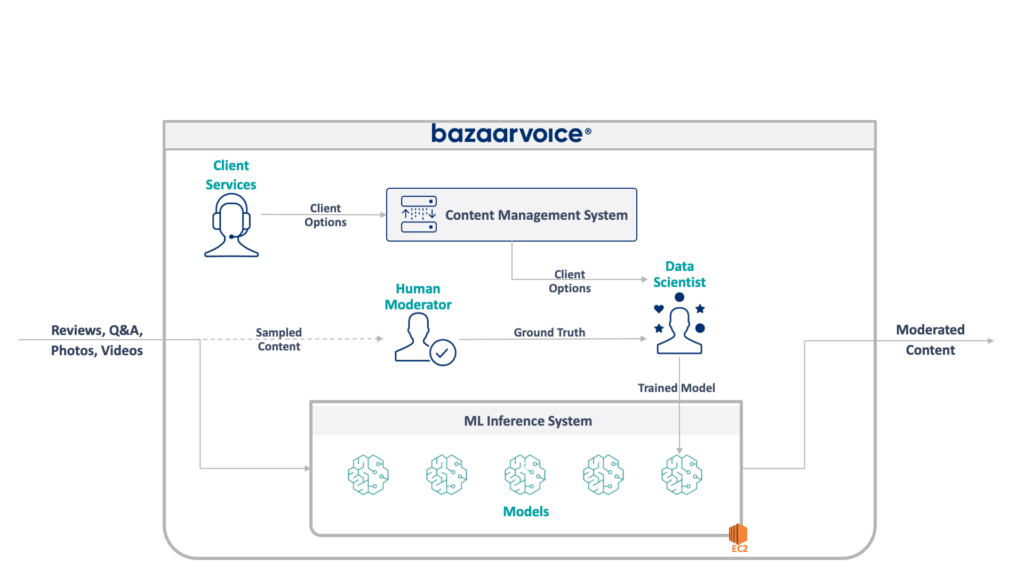
Este sistema tem algumas desvantagens sérias. Especificamente – todos os modelos são hospedados em uma única instância EC2. Isso não se deveu a má engenharia – apenas à incapacidade dos programadores originais de prever a escala desejada pela empresa. Ninguém pensou que cresceria tanto quanto cresceu.
Além disso, o sistema sofreu rejeição dos desenvolvedores: foi escrito em Scala, o que poucos engenheiros entendiam. Assim, muitas vezes era esquecido para melhorias, uma vez que ninguém queria tocá-lo.
Como resultado, o sistema continuou a crescer de maneira constante. Assim que começamos a rearquitetá-lo, ele estava sendo executado em uma única instância x1e.8xlarge. Essa coisa tinha quase um terabyte de memória RAM e custava cerca de US$ 5.000/mês (sem reserva) para operar. Não se preocupe, acabamos de lançar um segundo para redundância e um terceiro para controle de qualidade.
A execução desse sistema era cara e apresentava alto risco de falha (um único modelo ruim pode derrubar todo o serviço). Além disso, a base de código não havia sido desenvolvida ativamente e, portanto, estava significativamente desatualizada em relação aos pacotes modernos de ciência de dados e não seguia nossas práticas padrão para serviços escritos em Scala.
Um novo sistema
Ao redesenhar este sistema tínhamos um objetivo claro: torná-lo escalável. A redução dos custos operacionais era uma meta secundária, assim como a facilitação do gerenciamento de modelos e códigos.
O novo design que criamos é ilustrado abaixo:

Nossa abordagem para resolver tudo isso foi colocar cada modelo de aprendizado de máquina em um endpoint isolado do SageMaker Serverless. Assim como as funções do AWS Lambda, os endpoints sem servidor são desligados quando não estão em uso, economizando custos de tempo de execução para modelos usados com pouca frequência. Eles também podem expandir rapidamente em resposta ao aumento do tráfego.

Além disso, expusemos as opções do cliente a um único microsserviço que roteia o conteúdo para os modelos apropriados. Essa foi a maior parte do novo código que tivemos que escrever: uma pequena API que fosse fácil de manter e permitisse que nossos cientistas de dados atualizassem e implantassem novos modelos com mais facilidade.
Essa abordagem tem os seguintes benefícios:
- Diminuiu o tempo de valorização em mais de 6x. Especificamente, o roteamento do tráfego para modelos existentes é instantâneo e a implantação de novos modelos pode ser feita em menos de 5 minutos em vez de 30
- Dimensione sem limites – atualmente temos 400 modelos, mas planejamos dimensionar para milhares para continuar a aumentar a quantidade de conteúdo que podemos moderar automaticamente
- Vimos uma redução de custos de 82% ao sair do EC2, pois as funções são desligadas quando não estão em uso e não estamos pagando por máquinas de primeira linha que são subutilizadas
Contudo, simplesmente projetar uma arquitetura ideal não é a parte realmente interessante e difícil de reconstruir um sistema legado — você precisa migrar para ele.
Nosso primeiro desafio na migração foi descobrir como migrar um modelo Java WEKA para rodar no SageMaker, quanto mais no SageMaker Serverless.
Felizmente, o SageMaker implanta modelos em contêineres Docker, então pelo menos poderíamos congelar as versões Java e de dependência para corresponder ao nosso código antigo. Isso ajudaria a garantir que os modelos hospedados no novo sistema retornassem os mesmos resultados que o legado.

Para tornar o contêiner compatível com o SageMaker, tudo que você precisa fazer é implementar alguns endpoints HTTP específicos:
-
POST /invocation– aceita entrada, realiza inferência e retorna resultados. -
GET /ping— retorna 200 se o servidor JVM estiver íntegro
(Optamos por ignorar todo o lixo em torno dos contêineres multimodelos BYO e do kit de ferramentas de inferência SageMaker.)
Algumas abstrações rápidas sobre com.sun.net.httpserver.HttpServer e estávamos prontos para começar.
E sabe de uma coisa? Na verdade, isso foi muito divertido. Brincar com contêineres Docker e forçar algo com 10 anos no SageMaker Serverless teve uma vibração um pouco complicada. Foi muito emocionante quando o colocamos em funcionamento - especialmente quando obtivemos o código do sistema legado para construí-lo em nossa nova pilha sbt em vez de maven.
A nova pilha sbt facilitou o trabalho e a conteinerização garantiu que pudéssemos obter um comportamento adequado durante a execução no ambiente SageMaker.
Migrando para um novo sistema
Portanto, temos os modelos em contêineres e podemos implantá-los no SageMaker — quase pronto, certo? Não exatamente.
A lição difícil sobre a migração para uma nova arquitetura é que você deve construir três vezes o seu sistema real apenas para suportar a migração. Além do novo sistema, tivemos que construir:
- Um pipeline de captura de dados no sistema antigo para registrar entradas e saídas do modelo. Usamos isso para confirmar que o novo sistema retornaria os mesmos resultados
- Um pipeline de processamento de dados no novo sistema para calcular resultados e compará-los com os dados do sistema antigo. Isso envolveu uma grande quantidade de medições com o Datadog e precisava oferecer a capacidade de reproduzir dados quando encontrássemos discrepâncias
- Um sistema completo de implantação de modelo para evitar impactar os usuários do sistema antigo (que simplesmente carregaria modelos para S3). Sabíamos que queríamos migrá-los para uma API eventualmente, mas para o lançamento inicial, precisávamos fazer isso perfeitamente
Tudo isso era código descartável que sabíamos que poderíamos descartar assim que terminássemos a migração de todos os usuários, mas ainda tínhamos que construí-lo e garantir que as saídas do novo sistema correspondessem às antigas.
Espere isso antecipadamente.
Embora a construção de ferramentas e sistemas de migração certamente tenha levado mais de 60% do nosso tempo de engenharia neste projeto, também foi uma experiência divertida. Os testes unitários tornaram-se mais parecidos com experimentos de ciência de dados: escrevemos suítes inteiras para garantir que nossa saída correspondesse exatamente . Foi uma maneira diferente de pensar que tornou o trabalho ainda mais divertido. Um passo fora de nossas caixas normais, por assim dizer.
Modernizando sistemas legados por meio de uma rearquitetura
Da próxima vez que você se sentir tentado a reconstruir um sistema a partir do código, gostaria de encorajá-lo a tentar migrar a arquitetura em vez do código. Você encontrará desafios técnicos interessantes e gratificantes e provavelmente gostará muito mais deles do que depurar casos extremos inesperados de seu novo código.
Quer saber mais? Assista abaixo à palestra que proferi no AWS Data Summit, que se aprofunda no lado MLOps.