
Como funciona um rastreador da Web
Publicados: 2023-12-05Os web crawlers têm uma função vital na indexação e estruturação da extensa informação presente na internet. Sua função envolve percorrer páginas da web, coletar dados e torná-los pesquisáveis. Este artigo investiga a mecânica de um rastreador da web, fornecendo insights sobre seus componentes, operações e diversas categorias. Vamos mergulhar no mundo dos rastreadores da web!
O que é um rastreador da Web
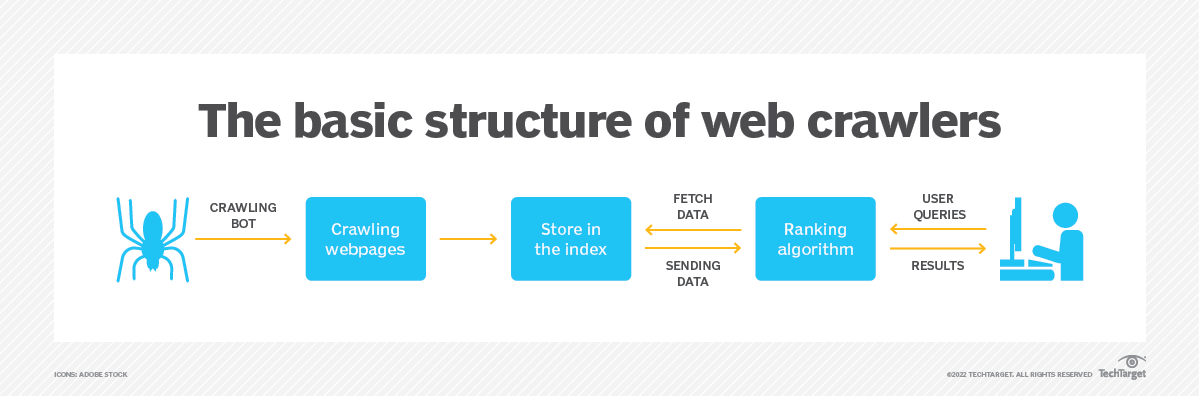
Um rastreador da web, conhecido como spider ou bot, é um script ou programa automatizado projetado para navegar metodicamente em sites da Internet. Começa com uma URL inicial e depois segue links HTML para visitar outras páginas da web, formando uma rede de páginas interconectadas que podem ser indexadas e analisadas.
Fonte da imagem: https://www.techtarget.com/
O objetivo de um rastreador da Web
O principal objetivo de um rastreador da web é coletar informações de páginas da web e gerar um índice pesquisável para recuperação eficiente. Os principais mecanismos de pesquisa, como Google, Bing e Yahoo, dependem fortemente de rastreadores da web para construir seus bancos de dados de pesquisa. Através do exame sistemático do conteúdo da web, os mecanismos de pesquisa podem fornecer aos usuários resultados de pesquisa pertinentes e atuais.
É importante observar que a aplicação de rastreadores da web vai além dos mecanismos de pesquisa. Eles também são usados por diversas organizações para tarefas como mineração de dados, agregação de conteúdo, monitoramento de sites e até segurança cibernética.
Os componentes de um rastreador da Web
Um rastreador da web compreende vários componentes que trabalham juntos para atingir seus objetivos. Aqui estão os principais componentes de um rastreador da web:
- URL Frontier: Este componente gerencia a coleção de URLs aguardando para serem rastreadas. Ele prioriza URLs com base em fatores como relevância, atualização ou importância do site.
- Downloader: O downloader recupera páginas da web com base nos URLs fornecidos pela fronteira de URL. Ele envia solicitações HTTP para servidores web, recebe respostas e salva o conteúdo web obtido para processamento posterior.
- Analisador: O analisador processa as páginas da web baixadas, extraindo informações úteis como links, texto, imagens e metadados. Ele analisa a estrutura da página e extrai as URLs das páginas vinculadas para serem adicionadas à fronteira da URL.
- Armazenamento de dados: O componente de armazenamento de dados armazena os dados coletados, incluindo páginas da web, informações extraídas e dados de indexação. Esses dados podem ser armazenados em vários formatos, como um banco de dados ou um sistema de arquivos distribuído.
Como funciona um rastreador da Web
Tendo obtido insights sobre os elementos envolvidos, vamos nos aprofundar no procedimento sequencial que elucida o funcionamento de um web crawler:
- URL inicial: o rastreador começa com um URL inicial, que pode ser qualquer página da web ou uma lista de URLs. Este URL é adicionado à fronteira de URL para iniciar o processo de rastreamento.
- Busca: o rastreador seleciona uma URL da fronteira de URL e envia uma solicitação HTTP ao servidor web correspondente. O servidor responde com o conteúdo da página da web, que é então obtido pelo componente de download.
- Análise: O analisador processa a página da web buscada, extraindo informações relevantes como links, texto e metadados. Ele também identifica e adiciona novos URLs encontrados na página à fronteira de URL.
- Análise de link: o rastreador prioriza e adiciona os URLs extraídos à fronteira do URL com base em determinados critérios como relevância, atualização ou importância. Isso ajuda a determinar a ordem em que o rastreador visitará e rastreará as páginas.
- Repita o processo: o rastreador continua o processo selecionando URLs da fronteira de URL, buscando seu conteúdo da web, analisando as páginas e extraindo mais URLs. Esse processo é repetido até que não haja mais URLs para rastrear ou até que um limite predefinido seja atingido.
- Armazenamento de dados: durante todo o processo de rastreamento, os dados coletados são armazenados no componente de armazenamento de dados. Esses dados podem ser usados posteriormente para indexação, análise ou outros fins.
Tipos de rastreadores da Web
Os rastreadores da Web vêm em diferentes variações e têm casos de uso específicos. Aqui estão alguns tipos de rastreadores da web comumente usados:

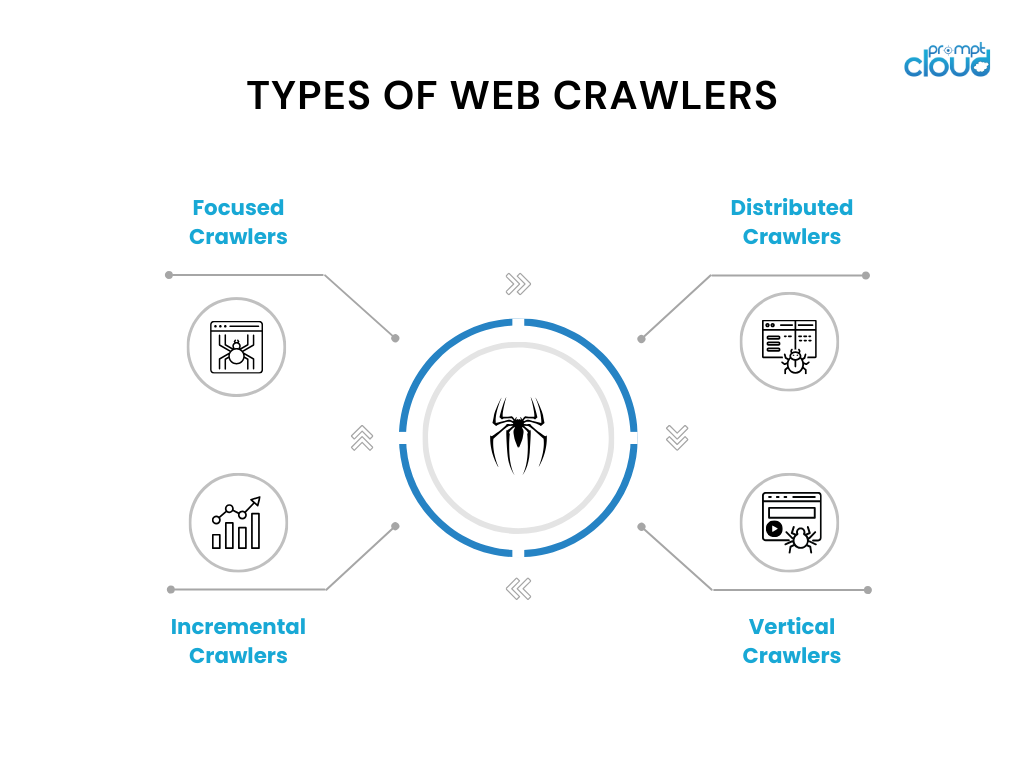
- Rastreadores focados: esses rastreadores operam em um domínio ou tópico específico e rastreiam páginas relevantes para esse domínio. Os exemplos incluem rastreadores de tópicos usados para sites de notícias ou artigos de pesquisa.
- Rastreadores incrementais: os rastreadores incrementais concentram-se no rastreamento de conteúdo novo ou atualizado desde o último rastreamento. Eles utilizam técnicas como análise de carimbo de data/hora ou algoritmos de detecção de alterações para identificar e rastrear páginas modificadas.
- Rastreadores distribuídos: em rastreadores distribuídos, várias instâncias do rastreador são executadas em paralelo, compartilhando a carga de trabalho de rastreamento de um grande número de páginas. Essa abordagem permite rastreamento mais rápido e melhor escalabilidade.
- Rastreadores verticais: os rastreadores verticais visam tipos específicos de conteúdo ou dados em páginas da web, como imagens, vídeos ou informações de produtos. Eles são projetados para extrair e indexar tipos específicos de dados para mecanismos de busca especializados.
Com que frequência você deve rastrear páginas da web?
A frequência do rastreamento de páginas da web depende de vários fatores, incluindo o tamanho e a frequência de atualização do site, a importância das páginas e os recursos disponíveis. Alguns sites podem exigir rastreamento frequente para garantir que as informações mais recentes sejam indexadas, enquanto outros podem ser rastreados com menos frequência.
Para sites de alto tráfego ou com conteúdo que muda rapidamente, o rastreamento mais frequente é essencial para manter as informações atualizadas. Por outro lado, sites menores ou páginas com atualizações pouco frequentes podem ser rastreados com menos frequência, reduzindo a carga de trabalho e os recursos necessários.
Rastreador da Web interno versus ferramentas de rastreamento da Web
Ao contemplar a criação de um rastreador da web, é crucial avaliar a complexidade, a escalabilidade e os recursos necessários. Construir um rastreador do zero pode ser uma tarefa demorada, abrangendo atividades como gerenciamento de simultaneidade, supervisão de sistemas distribuídos e solução de obstáculos de infraestrutura. Por outro lado, optar por ferramentas ou estruturas de rastreamento da web pode oferecer uma resolução mais rápida e eficaz.
Alternativamente, o uso de ferramentas ou estruturas de rastreamento da web pode fornecer uma solução mais rápida e eficiente. Essas ferramentas oferecem recursos como regras de rastreamento personalizáveis, recursos de extração de dados e opções de armazenamento de dados. Ao aproveitar as ferramentas existentes, os desenvolvedores podem se concentrar em seus requisitos específicos, como análise de dados ou integração com outros sistemas.
No entanto, é crucial considerar as limitações e os custos associados à utilização de ferramentas de terceiros, tais como restrições à personalização, propriedade de dados e potenciais modelos de preços.
Conclusão
Os motores de busca dependem fortemente de web crawlers, que são fundamentais na tarefa de organizar e catalogar a extensa informação presente na internet. Compreender a mecânica, os componentes e as diversas categorias dos rastreadores da Web permite uma compreensão mais profunda da intrincada tecnologia que sustenta esse processo fundamental.
Seja optando por construir um rastreador da web do zero ou aproveitando ferramentas pré-existentes para rastreamento da web, torna-se imperativo adotar uma abordagem alinhada com suas necessidades específicas. Isso envolve considerar fatores como escalabilidade, complexidade e os recursos à sua disposição. Ao levar esses elementos em consideração, você pode utilizar efetivamente o rastreamento da web para coletar e analisar dados valiosos, impulsionando assim seus negócios ou esforços de pesquisa .
Na PromptCloud, nos especializamos na extração de dados da web, obtendo dados de recursos online disponíveis publicamente. Entre em contato conosco em sales@promptcloud.com