
Como impedir que IAs rastreiem seu conteúdo
Publicados: 2023-10-24Ferramentas geradoras de IA, como Google Bard e Bing Chat, são criadas a partir de muitas fontes de conteúdo, incluindo a web. Para consternação de muitos, os mecanismos de pesquisa têm treinado silenciosamente seus modelos de IA em todo o conteúdo que encontram enquanto rastreiam a pesquisa tradicional na web.
O Bing e o Google anunciaram agora métodos para bloquear o uso de conteúdo para treinamento de IA, enquanto permanecem indexados para pesquisa na web.
Então, você deveria bloquear as IAs e como fazer isso?
- Você deve bloquear IAs?
- Como você bloqueia bots de IA?
- Como bloquear a IA do Bing
- Como bloquear a IA do Google
- Como bloquear ChatGPT
- Teste
Você deve bloquear IAs?
As empresas que fabricam os seus próprios produtos podem considerar um benefício incluir o seu conteúdo em modelos de IA. Informações, como especificações técnicas ou suporte ao produto, podem ajudar nas vendas e reduzir os custos de suporte ao cliente.
Mas para muitos outros negócios online, o conteúdo é o seu produto. Existem preocupações válidas de que a energia investida na criação de conteúdos será utilizada para melhorar os produtos de IA propriedade das grandes empresas tecnológicas, sem agregar qualquer valor sob a forma de tráfego.
O Google e o Bing estão tentando encontrar maneiras de creditar as fontes e fornecer algum tráfego de referência, mas é provável que seja menor do que a pesquisa tradicional na web e mais provável que seja transacional do que consultas de pesquisa informativas.
É importante observar que o bloqueio de conteúdo dessas IAs não afetará o comportamento de rastreamento. O Google diz que 'o token do agente do usuário robots.txt é usado para fins de controle'. Seu site será rastreado normalmente pelos bots para construir seus índices de pesquisa.
E se os mecanismos de pesquisa já estiverem impedidos de rastrear determinadas páginas, você não precisa bloqueá-los especificamente para as IAs.
Como você bloqueia bots de IA?
Atualmente é possível bloquear Google, Bing e ChatGPT usando métodos familiares à maioria dos SEOs, o arquivo robots.txt e as diretivas de robôs no nível da página.
Google e ChatGPT optaram pelo método robots.txt que permite especificar padrões de URL, e o Bing optou por usar diretivas de robôs aplicadas a páginas individuais.
O robots.txt tem a vantagem de ser fácil de configurar para um site inteiro em um único lugar. É muito transparente quais URLs estão sendo bloqueados em comparação com as diretivas de robôs no nível da página, que devem ser testadas buscando cada página.
Como bloquear a IA do Bing
O Bing procura as diretivas de robôs nocache ou noarchive, que podem ser adicionadas a uma página como uma meta tag ou em um cabeçalho de resposta X-Robots-Tag.
O Nocache permitirá que páginas sejam incluídas nas respostas do Bing Chat usando apenas URLs, títulos e snippets no treinamento dos modelos de IA da Microsoft.
O Noarchive não permite a inclusão de páginas no Bing Chat e nenhum conteúdo será usado no treinamento dos modelos de IA da Microsoft.
Se uma página tiver Nocache e Noarchive, o Nocache menos restritivo terá precedência.
O token ' robôs ' aplicará a diretiva a todos os rastreadores. Isso inclui o Google, que impedirá que a página apareça com um link em cache nos resultados de pesquisa.
<meta name=”robôs” content=”noarchive”>
Você pode usar os tokens mais específicos ' bingbot ' ou ' msnbot ' para evitar afetar outros mecanismos de pesquisa.
<meta nome=”bingbot” content=”nocache”>
Como bloquear a IA do Google
O Google optou pelo método robots.txt, que permite especificar padrões de URL para corresponder às páginas que você não deseja que sejam usadas no Bard e em seu equivalente da API Vertex. Atualmente, não se aplica à Search Generative Experience (SGE).
Eles corresponderão a um token de agente de usuário estendido pelo Google. O caso do token não importa.
Agente do usuário: Google-Extended
Proibir: /
Se não houver um bloco de regras específico para o token estendido do Google, ele corresponderá ao token curinga (*).

Agente de usuário: *
Proibir: /
Tenha cuidado se você tiver um bloco de regras específico para o Googlebot e um bloco curinga separado. Estendido pelo Google corresponderá ao bloco curinga, não ao bloco do Googlebot.
Agente do usuário: Googlebot
Permitir: /
Agente de usuário: *
Proibir: /
Você pode listar vários agentes de usuário antes que a regra seja bloqueada para ser mais preciso.
Agente do usuário: Google-Extended
Agente do usuário: Googlebot
Permitir: /
Agente de usuário: *
Proibir: /
Como bloquear ChatGPT
ChatGPT também optou pelo método robots.txt.
O Chat GPT tem dois tokens de agente de usuário diferentes, ChatGPT-User para consultas em nome de usuários do ChatGPT e GPTBot, que é o rastreador da Web da OpenAI usado para construir seus modelos.
O sistema de opt-out atualmente trata ambos os agentes de usuário da mesma forma, portanto, qualquer proibição de robots.txt para um agente cobrirá ambos. Isso pode mudar no futuro, por isso recomendamos bloqueá-los separadamente.
Agente de usuário: GPTBot
Agente do usuário: ChatGPT-User
Proibir: /
Teste
O teste é simples se você estiver bloqueando todo o seu site.
Para verificar se o Google e o ChatGPT estão bloqueados, você precisa ver se o seu robots.txt tem uma regra de proibir tudo para os bots que você deseja bloquear.
Agente do usuário: Google-Extended
Agente do usuário: GPTbot
Proibir: /
Se você deseja bloquear apenas alguns URLs, pode ser necessário um conjunto mais complexo de diretivas robots.txt. Você pode considerar testar vários URLs que espera que sejam bloqueados e não bloqueados.
Tomo é nossa ferramenta gratuita de robots.txt que pode ajudá-lo a testar se URLs específicos estão bloqueados em robots.txt. Você pode definir testes na forma de uma lista de URLs e o status não permitido esperado para cada URL.
Ele pode ser configurado com os tokens de agente de usuário Google-Extended, GPTBot e ChatGPT-User para mostrar quais URLs estão bloqueados para cada um e se isso corresponde ao resultado de teste esperado.
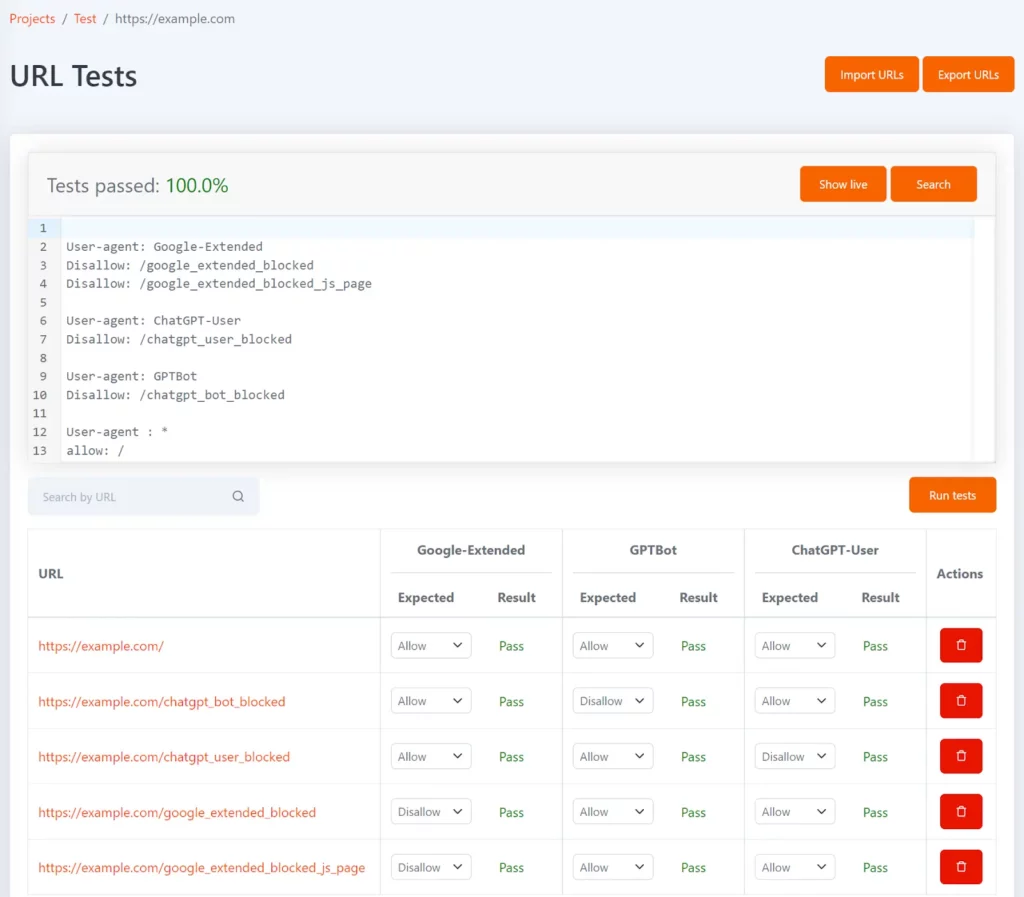
Sempre que seu arquivo robots.txt for atualizado, os testes serão executados novamente e você será notificado se os resultados não corresponderem ao esperado.
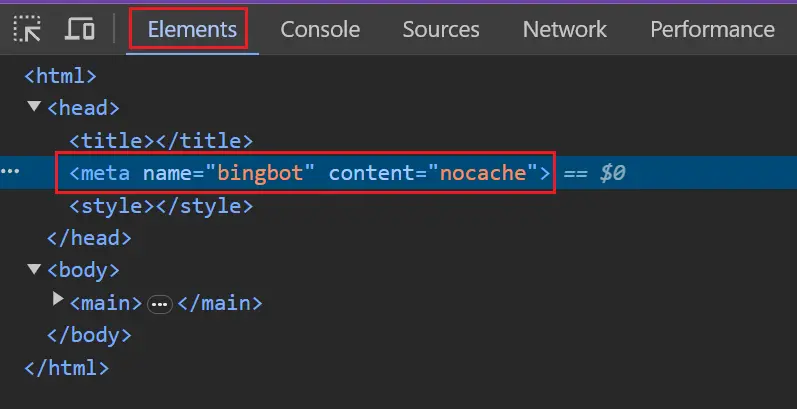
Para testar se o Bing está bloqueado, você pode inspecionar os modelos de página principais no navegador e confirmar se ele possui a tag robots.
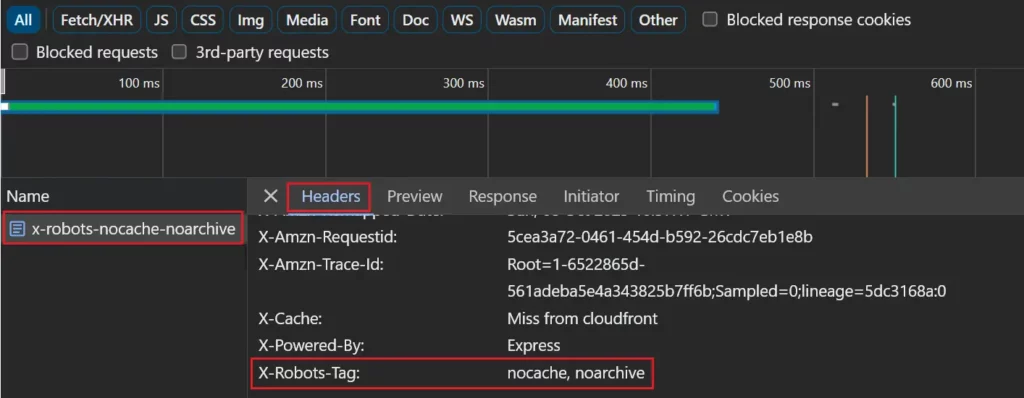
Se você estiver usando um cabeçalho de resposta X-Robots-Tag, ele poderá ser visto na guia de rede selecionando a página na lista de solicitações de rede e visualizando a guia ‘Cabeçalhos’.
O teste será mais complicado se você bloquear um conjunto específico de páginas, mas existem algumas ferramentas que podem ajudar.
O rastreador Lumar também reportará automaticamente todas as páginas onde as IAs do Google e do Bing estão bloqueadas.
Você precisa de suporte técnico adicional? Saiba mais sobre a oferta de tecnologia da Semetrical ou entre em contato para mais informações!