
Dominando raspadores de páginas da Web: um guia para iniciantes na extração de dados online
Publicados: 2024-04-09O que são raspadores de páginas da Web?
O raspador de página da Web é uma ferramenta projetada para extrair dados de sites. Simula a navegação humana para coletar conteúdo específico. Os iniciantes geralmente utilizam esses scrapers para diversas tarefas, incluindo pesquisa de mercado, monitoramento de preços e compilação de dados para projetos de aprendizado de máquina.
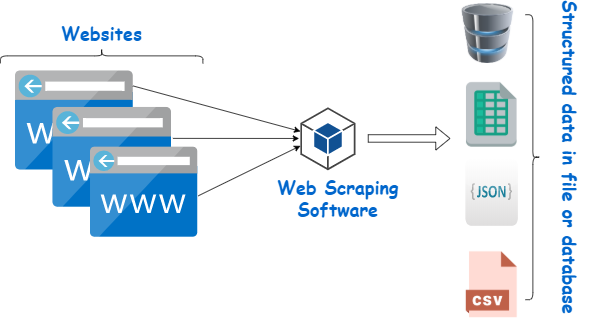
Fonte da imagem: https://www.webharvy.com/articles/what-is-web-scraping.html
- Facilidade de uso: Eles são fáceis de usar, permitindo que indivíduos com habilidades técnicas mínimas capturem dados da web de maneira eficaz.
- Eficiência: Scrapers podem coletar grandes quantidades de dados rapidamente, superando em muito os esforços manuais de coleta de dados.
- Precisão: a raspagem automatizada reduz o risco de erro humano, melhorando a precisão dos dados.
- Econômico: Eles eliminam a necessidade de entrada manual, economizando tempo e custos de mão de obra.
Compreender a funcionalidade dos scrapers de páginas da web é fundamental para quem deseja aproveitar o poder dos dados da web.
Criando um raspador de página da Web simples com Python
Para começar a criar um raspador de página da web em Python, é necessário instalar certas bibliotecas, ou seja, solicitações para fazer solicitações HTTP para uma página da web e BeautifulSoup do bs4 para analisar documentos HTML e XML.
- Ferramentas de coleta:
- Bibliotecas: Use solicitações para buscar páginas da web e BeautifulSoup para analisar o conteúdo HTML baixado.
- Direcionando a página da web:
- Defina o URL da página da web que contém os dados que queremos extrair.
- Baixando o Conteúdo:
- Usando solicitações, baixe o código HTML da página da web.
- Analisando o HTML:
- BeautifulSoup transformará o HTML baixado em um formato estruturado para fácil navegação.
- Extraindo os dados:
- Identifique as tags HTML específicas que contêm as informações desejadas (por exemplo, títulos de produtos dentro das tags <div>).
- Usando os métodos BeautifulSoup, extraia e processe os dados necessários.
Lembre-se de direcionar elementos HTML específicos relevantes para as informações que você deseja extrair.
Processo passo a passo para raspar uma página da web
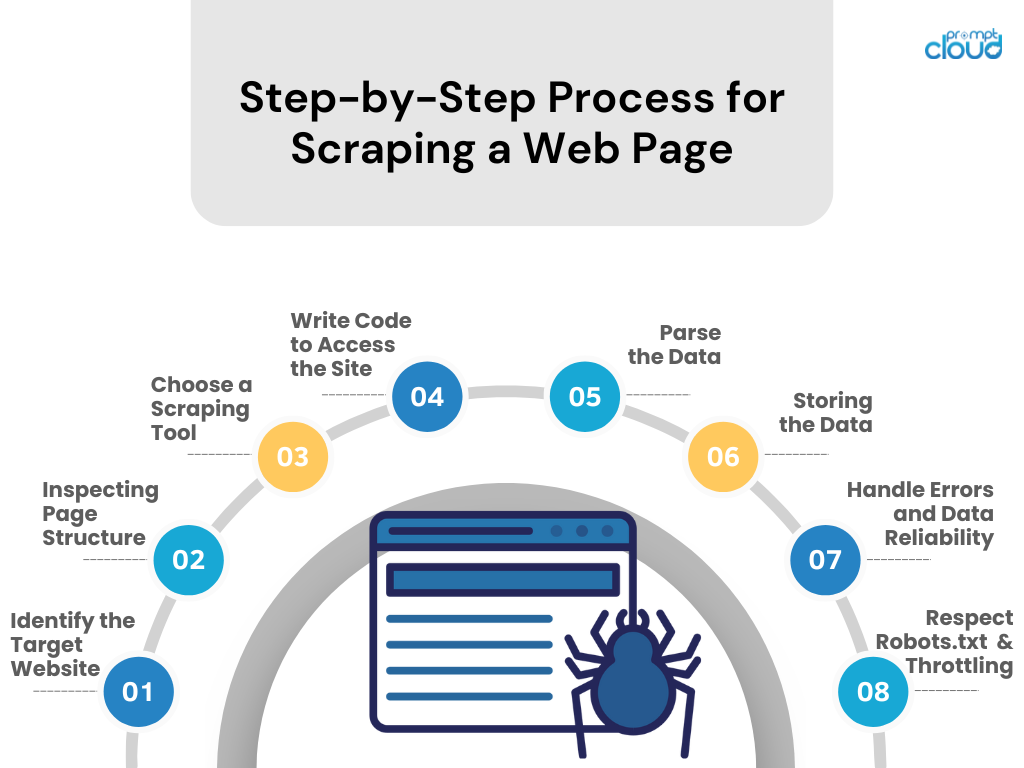
- Identifique o site alvo
Pesquise o site que você gostaria de raspar. Certifique-se de que é legal e ético fazê-lo. - Inspecionando a estrutura da página
Use as ferramentas de desenvolvedor do navegador para examinar a estrutura HTML, os seletores CSS e o conteúdo baseado em JavaScript. - Escolha uma ferramenta de raspagem
Selecione uma ferramenta ou biblioteca em uma linguagem de programação com a qual você se sinta confortável (por exemplo, BeautifulSoup ou Scrapy do Python). - Escreva o código para acessar o site
Crie um script que solicite dados do site, usando chamadas de API, se disponíveis, ou solicitações HTTP. - Analise os dados
Extraia os dados relevantes da página da web analisando HTML/CSS/JavaScript. - Armazenando os Dados
Salve os dados extraídos em um formato estruturado, como CSV, JSON ou diretamente em um banco de dados. - Lidar com erros e confiabilidade de dados
Implemente o tratamento de erros para gerenciar falhas de solicitação e manter a integridade dos dados. - Respeite Robots.txt e limitação
Siga as regras do arquivo robots.txt do site e evite sobrecarregar o servidor controlando a taxa de solicitação.
Selecionando as ferramentas de web scraping ideais para suas necessidades
Ao explorar a web, é crucial selecionar ferramentas alinhadas com sua proficiência e objetivos. Os iniciantes devem considerar:
- Facilidade de uso: opte por ferramentas intuitivas com assistência visual e documentação clara.
- Requisitos de dados: Avalie a estrutura e a complexidade dos dados alvo para determinar se é necessária uma extensão simples ou um software robusto.
- Orçamento: pese o custo em relação aos recursos; muitos raspadores eficazes oferecem níveis gratuitos.
- Personalização: Certifique-se de que a ferramenta seja adaptável para necessidades específicas de raspagem.
- Suporte: O acesso a uma comunidade de usuários útil ajuda na solução de problemas e na melhoria.
Escolha sabiamente para uma jornada de raspagem tranquila.
Dicas e truques para otimizar seu raspador de página da web
- Use bibliotecas de análise eficientes como BeautifulSoup ou Lxml em Python para processamento HTML mais rápido.
- Implemente o cache para evitar novos downloads de páginas e reduzir a carga no servidor.
- Respeite os arquivos robots.txt e use a limitação de taxa para evitar ser banido pelo site de destino.
- Alterne agentes de usuário e servidores proxy para imitar o comportamento humano e evitar detecção.
- Programe scrapers fora dos horários de pico para minimizar o impacto no desempenho do site.
- Opte por endpoints de API, se disponíveis, pois eles fornecem dados estruturados e geralmente são mais eficientes.
- Evite extrair dados desnecessários sendo seletivo em suas consultas, reduzindo a largura de banda e o armazenamento necessários.
- Atualize regularmente seus scrapers para se adaptarem às mudanças na estrutura do site e manter a integridade dos dados.
Lidando com problemas comuns e solução de problemas de raspagem de páginas da Web
Ao trabalhar com scrapers de páginas da web, os iniciantes podem enfrentar vários problemas comuns:

- Problemas de seletor : certifique-se de que os seletores correspondam à estrutura atual da página da web. Ferramentas como ferramentas de desenvolvedor de navegador podem ajudar a identificar os seletores corretos.
- Conteúdo dinâmico : algumas páginas da web carregam conteúdo dinamicamente com JavaScript. Nesses casos, considere usar navegadores headless ou ferramentas que renderizem JavaScript.
- Solicitações bloqueadas : os sites podem bloquear scrapers. Empregue estratégias como rotação de agentes de usuário, uso de proxies e respeito ao robots.txt para mitigar o bloqueio.
- Problemas de formato de dados : os dados extraídos podem precisar de limpeza ou formatação. Use expressões regulares e manipulação de strings para padronizar os dados.
Lembre-se de consultar a documentação e os fóruns da comunidade para obter orientações específicas sobre solução de problemas.
Conclusão
Os iniciantes agora podem coletar dados da web de maneira conveniente por meio do raspador de páginas da web, tornando a pesquisa e a análise mais eficientes. Compreender os métodos corretos e considerar os aspectos legais e éticos permite que os usuários aproveitem todo o potencial do web scraping. Siga estas diretrizes para uma introdução tranquila à raspagem de páginas da web, repleta de insights valiosos e tomada de decisão informada.
Perguntas frequentes:
O que é raspar uma página?
Web scraping, também conhecido como data scraping ou web harvesting, consiste na extração automática de dados de sites por meio de programas de computador que imitam comportamentos de navegação humana. Com um raspador de página da web, grandes quantidades de informações podem ser classificadas rapidamente, concentrando-se apenas em seções significativas, em vez de compilá-las manualmente.
As empresas aplicam web scraping para funções como examinar custos, gerenciar reputações, analisar tendências e executar análises competitivas. A implementação de projetos de web scraping garante a verificação de que os sites visitados aprovam a ação e a observância de todos os protocolos relevantes robots.txt e no-follow.
Como faço para raspar uma página inteira?
Para copiar uma página da web inteira, geralmente são necessários dois componentes: uma maneira de localizar os dados necessários na página da web e um mecanismo para salvar esses dados em outro lugar. Muitas linguagens de programação suportam web scraping, principalmente Python e JavaScript.
Existem várias bibliotecas de código aberto para ambos, simplificando ainda mais o processo. Algumas escolhas populares entre os desenvolvedores Python incluem BeautifulSoup, Requests, LXML e Scrapy. Alternativamente, plataformas comerciais como ParseHub e Octoparse permitem que indivíduos menos técnicos criem visualmente fluxos de trabalho complexos de web scraping. Depois de instalar as bibliotecas necessárias e compreender os conceitos básicos por trás da seleção dos elementos DOM, comece identificando os pontos de dados de interesse na página da web de destino.
Utilize ferramentas de desenvolvedor de navegador para inspecionar tags e atributos HTML e, em seguida, traduza essas descobertas na sintaxe correspondente suportada pela biblioteca ou plataforma escolhida. Por último, especifique as preferências de formato de saída, seja CSV, Excel, JSON, SQL ou outra opção, juntamente com os destinos onde residem os dados salvos.
Como faço para usar o raspador do Google?
Ao contrário da crença popular, o Google não oferece diretamente uma ferramenta pública de web scraping por si só, apesar de fornecer APIs e SDKs para facilitar a integração perfeita com vários produtos. No entanto, desenvolvedores qualificados criaram soluções de terceiros baseadas nas principais tecnologias do Google, expandindo efetivamente os recursos além da funcionalidade nativa. Os exemplos incluem SerpApi, que abstrai aspectos complicados do Google Search Console e apresenta uma interface fácil de usar para rastreamento de classificação de palavras-chave, estimativa de tráfego orgânico e exploração de backlinks.
Embora tecnicamente distintos do web scraping tradicional, esses modelos híbridos confundem os limites que separam as definições convencionais. Outros casos mostram esforços de engenharia reversa aplicados para reconstruir a lógica interna que impulsiona a Plataforma Google Maps, a API de dados do YouTube v3 ou os Serviços de Compras do Google, produzindo funcionalidades notavelmente próximas das contrapartes originais, embora sujeitas a vários graus de riscos de legalidade e sustentabilidade. Em última análise, os aspirantes a raspadores de páginas da web devem explorar diversas opções e avaliar os méritos em relação aos requisitos específicos antes de se comprometerem com um determinado caminho.
O raspador do Facebook é legal?
Conforme declarado nas Políticas de Desenvolvedores do Facebook, web scraping não autorizado constitui uma clara violação dos padrões da comunidade. Os usuários concordam em não desenvolver ou operar aplicativos, scripts ou outros mecanismos projetados para contornar ou exceder os limites de taxa de API designados, nem tentar decifrar, descompilar ou fazer engenharia reversa de qualquer aspecto do Site ou Serviço. Além disso, destaca as expectativas em torno da protecção de dados e da privacidade, exigindo o consentimento explícito do utilizador antes de partilhar informações pessoalmente identificáveis fora dos contextos permitidos.
Qualquer falha na observância dos princípios delineados desencadeia medidas disciplinares crescentes, começando com advertências e avançando progressivamente em direção ao acesso restrito ou à revogação completa de privilégios, dependendo dos níveis de gravidade. Apesar das exceções criadas para pesquisadores de segurança que operam sob programas aprovados de recompensa por bugs, o consenso geral defende evitar iniciativas não sancionadas de raspagem do Facebook para evitar complicações desnecessárias. Em vez disso, considere procurar alternativas compatíveis com as normas e convenções prevalecentes endossadas pela plataforma.