
Rastreador da Web Python – Tutorial passo a passo
Publicados: 2023-12-07Os rastreadores da Web são ferramentas fascinantes no mundo da coleta de dados e da web scraping. Eles automatizam o processo de navegação na web para coletar dados, que podem ser usados para diversos fins, como indexação de mecanismos de busca, mineração de dados ou análise competitiva. Neste tutorial, embarcaremos em uma jornada informativa para construir um rastreador da web básico usando Python, uma linguagem conhecida por sua simplicidade e recursos poderosos no tratamento de dados da web.
Python, com seu rico ecossistema de bibliotecas, oferece uma excelente plataforma para o desenvolvimento de web crawlers. Quer você seja um desenvolvedor iniciante, um entusiasta de dados ou simplesmente curioso sobre como funcionam os rastreadores da web, este guia passo a passo foi projetado para apresentar os fundamentos do rastreamento da web e equipá-lo com as habilidades necessárias para criar seu próprio rastreador. .
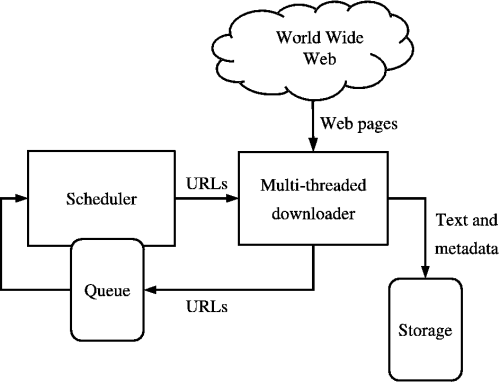
Fonte: https://medium.com/kariyertech/web-crawling-general-perspective-713971e9c659
Python Web Crawler – Como construir um Web Crawler
Etapa 1: Compreendendo o básico
Um web crawler, também conhecido como spider, é um programa que navega na World Wide Web de maneira metódica e automatizada. Para nosso rastreador, usaremos Python devido à sua simplicidade e bibliotecas poderosas.
Etapa 2: configure seu ambiente
Instale o Python : certifique-se de ter o Python instalado. Você pode baixá-lo em python.org.
Instalar bibliotecas : você precisará de solicitações para fazer solicitações HTTP e do BeautifulSoup do bs4 para analisar HTML. Instale-os usando pip:
solicitações de instalação de pip pip install beautifulsoup4
Etapa 3: escrever o rastreador básico
Importar bibliotecas :
importar solicitações do bs4 import BeautifulSoup
Buscar uma página da Web :
Aqui, buscaremos o conteúdo de uma página da web. Substitua 'URL' pela página da web que você deseja rastrear.
url = 'URL' resposta = solicitações.get(url) conteúdo = resposta.content
Analise o conteúdo HTML :
sopa = BeautifulSoup(content, 'html.parser')
Extrair informações :
Por exemplo, para extrair todos os hiperlinks, você pode fazer:
para link em sopa.find_all('a'): print(link.get('href'))
Etapa 4: expanda seu rastreador
Tratamento de URLs relativos :
Use urljoin para lidar com URLs relativos.
de urllib.parse importar urljoin
Evite rastrear a mesma página duas vezes :
Mantenha um conjunto de URLs visitados para evitar redundância.
Adicionando atrasos :
O rastreamento respeitoso inclui atrasos entre solicitações. Utilize time.sleep().
Etapa 5: respeite Robots.txt
Certifique-se de que seu rastreador respeite o arquivo robots.txt dos sites, que indica quais partes do site não devem ser rastreadas.
Etapa 6: tratamento de erros
Implemente blocos try-except para lidar com possíveis erros, como tempos limite de conexão ou acesso negado.
Etapa 7: Indo mais fundo
Você pode aprimorar seu rastreador para lidar com tarefas mais complexas, como envios de formulários ou renderização de JavaScript. Para sites com muito JavaScript, considere usar Selenium.
Etapa 8: armazene os dados
Decida como armazenar os dados que você rastreou. As opções incluem arquivos simples, bancos de dados ou até mesmo o envio direto de dados para um servidor.
Etapa 9: seja ético
- Não sobrecarregue os servidores; adicione atrasos em suas solicitações.
- Siga os termos de serviço do site.
- Não copie ou armazene dados pessoais sem permissão.
Ser bloqueado é um desafio comum durante o rastreamento da web, especialmente quando se trata de sites que possuem medidas em vigor para detectar e bloquear o acesso automatizado. Aqui estão algumas estratégias e considerações para ajudá-lo a lidar com esse problema em Python:
Compreendendo por que você foi bloqueado
Solicitações frequentes: Solicitações rápidas e repetidas do mesmo IP podem desencadear bloqueios.
Padrões não humanos: os bots geralmente exibem um comportamento distinto dos padrões de navegação humana, como acessar páginas muito rapidamente ou em uma sequência previsível.
Gerenciamento incorreto de cabeçalhos: cabeçalhos HTTP ausentes ou incorretos podem fazer com que suas solicitações pareçam suspeitas.
Ignorar o robots.txt: o não cumprimento das diretivas do arquivo robots.txt de um site pode levar a bloqueios.
Estratégias para evitar ser bloqueado
Respeite o robots.txt : Sempre verifique e cumpra o arquivo robots.txt do site. É uma prática ética e pode evitar bloqueios desnecessários.
Agentes de usuário rotativos : os sites podem identificá-lo por meio de seu agente de usuário. Ao girá-lo, você reduz o risco de ser sinalizado como bot. Use a biblioteca fake_useragent para implementar isso.
de fake_useragent import UserAgent ua = UserAgent() headers = {'User-Agent': ua.random}

Adicionando atrasos : implementar um atraso entre as solicitações pode imitar o comportamento humano. Use time.sleep() para adicionar um atraso aleatório ou fixo.
tempo de importação time.sleep(3) # Aguarda 3 segundos
Rotação de IP : Se possível, use serviços de proxy para girar seu endereço IP. Existem serviços gratuitos e pagos disponíveis para isso.
Usando sessões : um objeto requests.Session em Python pode ajudar a manter uma conexão consistente e compartilhar cabeçalhos, cookies, etc., entre solicitações, fazendo com que seu rastreador pareça mais uma sessão normal do navegador.
com requests.Session() como sessão: session.headers = {'User-Agent': ua.random} resposta = session.get(url)
Manipulação de JavaScript : alguns sites dependem muito de JavaScript para carregar conteúdo. Ferramentas como Selenium ou Puppeteer podem imitar um navegador real, incluindo renderização de JavaScript.
Tratamento de erros : implemente um tratamento robusto de erros para gerenciar e responder a bloqueios ou outros problemas de maneira elegante.
Considerações éticas
- Sempre respeite os termos de serviço de um site. Se um site proíbe explicitamente o web scraping, é melhor obedecer.
- Esteja atento ao impacto que seu rastreador tem nos recursos do site. Sobrecarregar um servidor pode causar problemas para o proprietário do site.
Técnicas Avançadas
- Estruturas de Web Scraping : considere usar estruturas como o Scrapy, que possuem recursos integrados para lidar com vários problemas de rastreamento.
- Serviços de resolução de CAPTCHA : Para sites com desafios de CAPTCHA, existem serviços que podem resolver CAPTCHAs, embora seu uso levante questões éticas.
Melhores práticas de rastreamento da Web em Python
O envolvimento em atividades de rastreamento da web exige um equilíbrio entre eficiência técnica e responsabilidade ética. Ao usar Python para rastreamento da web, é importante aderir às práticas recomendadas que respeitam os dados e os sites de onde eles são originados. Aqui estão algumas considerações importantes e práticas recomendadas para rastreamento da web em Python:
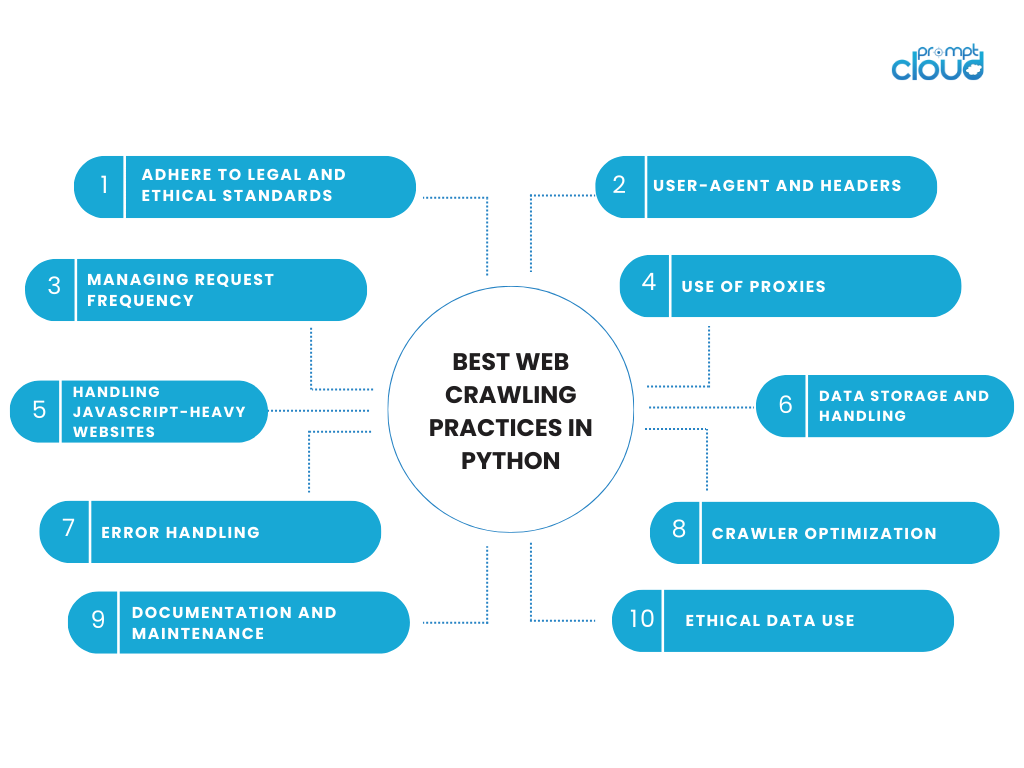
Aderir aos padrões legais e éticos
- Respeite o robots.txt: Verifique sempre o arquivo robots.txt do site. Este arquivo descreve as áreas do site que o proprietário do site prefere que não sejam rastreadas.
- Siga os Termos de Serviço: Muitos sites incluem cláusulas sobre web scraping em seus termos de serviço. Cumprir estes termos é ético e legalmente prudente.
- Evite sobrecarregar os servidores: Faça solicitações em um ritmo razoável para evitar sobrecarregar o servidor do site.
Agente de usuário e cabeçalhos
- Identifique-se: use uma string de agente do usuário que inclua suas informações de contato ou a finalidade do rastreamento. Essa transparência pode construir confiança.
- Use cabeçalhos adequadamente: cabeçalhos HTTP bem configurados podem reduzir a probabilidade de serem bloqueados. Eles podem incluir informações como agente do usuário, idioma de aceitação, etc.
Gerenciando a frequência de solicitações
- Adicionar atrasos: implemente um atraso entre as solicitações para imitar os padrões de navegação humana. Use a função time.sleep() do Python.
- Limitação de taxa: esteja ciente de quantas solicitações você envia a um site em um determinado período.
Uso de proxies
- Rotação de IP: Usar proxies para alternar seu endereço IP pode ajudar a evitar o bloqueio baseado em IP, mas isso deve ser feito de forma responsável e ética.
Lidando com sites com muito JavaScript
- Conteúdo Dinâmico: Para sites que carregam conteúdo dinamicamente com JavaScript, ferramentas como Selenium ou Puppeteer (em combinação com Pyppeteer para Python) podem renderizar as páginas como um navegador.
Armazenamento e tratamento de dados
- Armazenamento de dados: armazene os dados rastreados de forma responsável, considerando as leis e regulamentos de privacidade de dados.
- Minimize a extração de dados: extraia apenas os dados necessários. Evite coletar informações pessoais ou confidenciais, a menos que seja absolutamente necessário e legal.
Manipulação de erros
- Tratamento robusto de erros: implemente um tratamento abrangente de erros para gerenciar problemas como tempos limite, erros de servidor ou conteúdo que falha ao carregar.
Otimização do rastreador
- Escalabilidade: projete seu rastreador para lidar com um aumento de escala, tanto em termos de número de páginas rastreadas quanto de quantidade de dados processados.
- Eficiência: otimize seu código para eficiência. O código eficiente reduz a carga no sistema e no servidor de destino.
Documentação e Manutenção
- Mantenha a documentação: documente seu código e lógica de rastreamento para referência e manutenção futuras.
- Atualizações regulares: mantenha seu código de rastreamento atualizado, especialmente se a estrutura do site de destino mudar.
Uso Ético de Dados
- Utilização Ética: Utilize os dados coletados de maneira ética, respeitando a privacidade do usuário e as normas de uso de dados.
Para concluir
Ao encerrar nossa exploração da construção de um rastreador da Web em Python, percorremos as complexidades da coleta automatizada de dados e as considerações éticas que a acompanham. Este esforço não só melhora as nossas competências técnicas, mas também aprofunda a nossa compreensão do tratamento responsável de dados no vasto cenário digital.
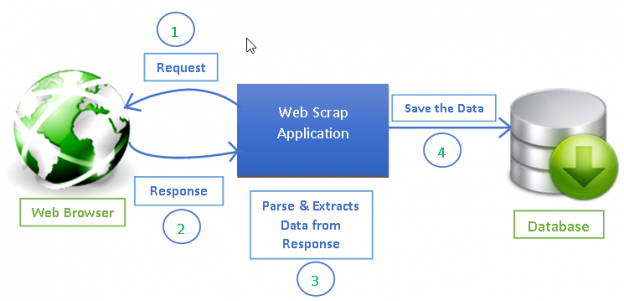
Fonte: https://www.datacamp.com/tutorial/making-web-crawlers-scrapy-python
No entanto, criar e manter um web crawler pode ser uma tarefa complexa e demorada, especialmente para empresas com necessidades específicas de dados em grande escala. É aqui que os serviços personalizados de web scraping do PromptCloud entram em ação. Se você procura uma solução personalizada, eficiente e ética para seus requisitos de dados da web, a PromptCloud oferece uma variedade de serviços para atender às suas necessidades exclusivas. Desde o gerenciamento de sites complexos até o fornecimento de dados limpos e estruturados, eles garantem que seus projetos de web scraping sejam descomplicados e alinhados aos seus objetivos de negócios.
Para empresas e indivíduos que podem não ter tempo ou conhecimento técnico para desenvolver e gerenciar seus próprios rastreadores da web, terceirizar essa tarefa para especialistas como a PromptCloud pode ser uma virada de jogo. Seus serviços não apenas economizam tempo e recursos, mas também garantem que você obtenha os dados mais precisos e relevantes, ao mesmo tempo que adere aos padrões legais e éticos.
Interessado em aprender mais sobre como o PromptCloud pode atender às suas necessidades específicas de dados? Entre em contato com eles em sales@promptcloud.com para obter mais informações e discutir como suas soluções personalizadas de web scraping podem ajudar a impulsionar seus negócios.
No mundo dinâmico dos dados da web, ter um parceiro confiável como a PromptCloud pode capacitar seus negócios, proporcionando vantagem na tomada de decisões baseada em dados. Lembre-se, no âmbito da coleta e análise de dados, o parceiro certo faz toda a diferença.
Boa caça aos dados!