
Selecionando e configurando mecanismos de inferência para LLMs
Publicados: 2024-04-02Introdução aos motores de inferência
Existem muitas técnicas de otimização desenvolvidas para mitigar as ineficiências que ocorrem nas diferentes etapas do processo de inferência. É difícil dimensionar a inferência em escala com técnicas/transformadores vanilla. Os mecanismos de inferência reúnem as otimizações em um pacote e nos facilitam o processo de inferência.
Para um conjunto muito pequeno de testes ad hoc ou referência rápida, podemos usar o código do transformador vanilla para fazer a inferência.
O cenário dos mecanismos de inferência está evoluindo rapidamente. Como temos diversas opções, é importante testar e listar o melhor dos melhores para casos de uso específicos. Abaixo estão alguns experimentos de motores de inferência que fizemos e os motivos pelos quais descobrimos porque funcionaram em nosso caso.
Para o nosso modelo Vicuna-7B ajustado, tentamos
- TGI
- vLLM
- Afrodite
- Optimum-Nvidia
- PowerInfer
- LAMACPP
- Ctranslate2
Examinamos a página do github e seu guia de início rápido para configurar esses mecanismos, PowerInfer, LlaamaCPP, Ctranslate2 não são muito flexíveis e não suportam muitas técnicas de otimização, como lote contínuo, atenção paginada e desempenho abaixo da média quando comparado a outros mecanismos mencionados .
Para obter maior rendimento, o mecanismo/servidor de inferência deve maximizar a memória e os recursos de computação e tanto o cliente quanto o servidor devem trabalhar de forma paralela/assíncrona para atender solicitações para manter o servidor sempre em funcionamento. Conforme mencionado anteriormente, sem a ajuda de técnicas de otimização como PagedAttention, Flash Attention, Continuous batching, isso sempre levará a um desempenho abaixo do ideal.
TGI, vLLM e Afrodite são candidatos mais adequados nesse aspecto e, ao fazer vários experimentos indicados abaixo, encontramos a configuração ideal para extrair o desempenho máximo da inferência. Técnicas como lote contínuo e atenção paginada são habilitadas por padrão, a decodificação especulativa precisa ser habilitada manualmente no mecanismo de inferência para os testes abaixo.
Análise Comparativa de Motores de Inferência
TGI
Para usar o TGI, podemos passar pela seção 'Introdução' da página do github, aqui o docker é a maneira mais simples de configurar e usar o mecanismo TGI.
Argumentos do iniciador de geração de texto -> esta lista as diferentes configurações que podemos usar no lado do servidor. Poucos importantes,
- –max-input-length : determina o comprimento máximo da entrada do modelo, isso requer alterações na maioria dos casos, pois o padrão é 1024.
- –max-total-tokens: máx. total de tokens, ou seja, comprimento do token de entrada + saída.
- –speculate, –quantiz, –max-concurrent-requests -> o padrão é apenas 128, o que é obviamente menor.
Para iniciar um modelo local ajustado,
docker run –gpus device=1 –shm-size 1g -p 9091:80 -v /path/to/fine_tuned_v1:/model ghcr.io/huggingface/text-generation-inference:1.4.4 –model-id /model – dtype float16 –num-shard 1 –max-input-length 3600 –max-total-tokens 4000 –especular 2
Para iniciar um modelo do hub,
modelo=”lmsys/vicuna-7b-v1.5″; volume=$PWD/dados; token=”<hf_token>”; docker run –gpus all –shm-size 1g -e HUGGING_FACE_HUB_TOKEN=$token -p 9091:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:1.4.4 –model-id $model – dtype float16 –num-shard 1 –max-input-length 3600 –max-total-tokens 4000 –especular 2
Você pode pedir ao chatGPT para explicar o comando acima para uma compreensão mais detalhada. Aqui estamos iniciando o servidor de inferência na porta 9091. E podemos usar um cliente de qualquer idioma para enviar uma solicitação ao servidor. API de inferência de geração de texto -> menciona todos os endpoints e parâmetros de carga útil para solicitação.
Por exemplo
carga útil=”<solicite aqui>”
curl -XPOST “0.0.0.0:9091/generate” -H “Tipo de conteúdo: aplicação/json” -d “{“inputs”: $payload, “parâmetros”: {“max_new_tokens”: 400,”do_sample”:false ,”best_of”: null,”repetition_penalty”: 1,”return_full_text”: false,”seed”: null,”stop_sequences”: null,”temperatura”: 0,1,”top_k”: 100,”top_p”: 0,3,” truncar”: nulo,”típico_p”: nulo,”marca d'água”: falso,”decodificador_input_details”: falso}}”
Poucas observações,
- A latência aumenta com max-token-tokens, o que é óbvio: se estivermos processando texto longo, o tempo geral aumentará.
- Especular ajuda, mas depende do caso de uso e da distribuição de entrada-saída.
- A quantização Eetq ajuda ao máximo a aumentar o rendimento.
- Se você tiver uma multi GPU, executar 1 API em cada GPU e ter essas APIs multi GPU atrás de um balanceador de carga resulta em uma taxa de transferência mais alta do que a fragmentação pelo próprio TGI.
vLLM
Para iniciar um servidor vLLM, podemos usar um servidor/docker REST API compatível com OpenAI. Para começar é muito simples, siga Deploying with Docker — vLLM, se for usar um modelo local, anexe o volume e use o caminho como nome do modelo,
docker run –runtime nvidia –gpus device=1 –shm-size 1g -v /path/to/fine_tuned_v1:/model -v ~/.cache/ -p 8000:8000 –ipc=host vllm/vllm-openai:latest – modelo/modelo
Acima irá iniciar um servidor vLLM na porta 8000 mencionada, como sempre você pode brincar com argumentos.
Faça solicitação de postagem com,
“`concha
carga útil=”<solicite aqui>”
curl -XPOST -m 1200 “0.0.0.0:8000/v1/completions” -H “Tipo de conteúdo: aplicativo/json” -d “{“prompt”: $payload,”model”:”/model” ,”max_tokens ”: 400,”top_p”: 0,3, “top_k”: 100, “temperatura”: 0,1}”
“`
Afrodite
“`concha
pip instalar motor afrodite
python -m afrodite.endpoints.openai.api_server –model PygmalionAI/pygmalion-2-7b
“`
Ou
“`
docker run -v /caminho/para/fine_tuned_v1:/model -d -e MODEL_NAME=”/model” -p 2242:7860 –gpus device=1 –ipc host alpindale/aphrodite-engine

“`
Afrodite fornece instalação pip e docker conforme mencionado na seção de primeiros passos. O Docker geralmente é relativamente mais fácil de rodar e testar. Opções de uso, opções de servidor nos ajudam a fazer solicitações.
- Afrodite e vLLM usam cargas úteis baseadas em servidor openAI, para que você possa verificar sua documentação.
- Tentamos o deepspeed-mii, pois está em estado de transição (quando tentamos) do legado para a nova base de código, não parece confiável e fácil de usar.
- Optimum-NVIDIA não oferece suporte a outras otimizações importantes e resulta em desempenho abaixo do ideal, link de referência.
- Adicionada uma essência, o código que usamos para fazer as solicitações paralelas ad hoc.
Métricas e Medidas
Queremos experimentar e descobrir:
- Ótimo não. de threads para o servidor cliente/mecanismo de inferência.
- Como a taxa de transferência aumenta com o aumento da memória
- Como a taxa de transferência aumenta em relação aos núcleos do tensor.
- Efeito de threads versus solicitação paralela por cliente.
Uma maneira muito básica de observar a utilização é observá-la através dos utilitários linux nvidia-smi, nvtop, isso nos dirá a memória ocupada, utilização de computação, taxa de transferência de dados, etc.
Outra forma é traçar o perfil do processo usando GPU com nsys.
| S.Não | GPU | Memória vRAM | Motor de inferência | Tópicos | Tempo(s) | Especular |
| 1 | A6000 | 48/48GB | TGI | 24 | 664 | – |
| 2 | A6000 | 48/48GB | TGI | 64 | 561 | – |
| 3 | A6000 | 48/48GB | TGI | 128 | 554 | – |
| 4 | A6000 | 48/48GB | TGI | 256 | 568 | – |
Com base nos experimentos acima, o thread 128/256 é melhor do que o número de threads inferior e além de 256 a sobrecarga começa a contribuir para a redução do rendimento. Descobriu-se que isso depende da CPU e da GPU e precisa de um experimento próprio. | ||||||
| 5 | A6000 | 48/48GB | TGI | 128 | 596 | 2 |
| 6 | A6000 | 48/48GB | TGI | 128 | 945 | 8 |
Maior valor especulativo causando mais rejeições para nosso modelo ajustado e, assim, reduzindo o rendimento. 1/2 como valor especulado é bom, está sujeito ao modelo e não há garantia de que funcione da mesma forma em todos os casos de uso. Mas a conclusão é que a decodificação especulativa melhora o rendimento. | ||||||
| 7 | 3090 | 24/24 GB | TGI | 128 | 741 | 2 |
| 7 | 4090 | 24/24 GB | TGI | 128 | 481 | 2 |
Embora o 4090 tenha menos vRAM em comparação com o A6000, ele apresenta desempenho superior devido à maior contagem de núcleos tensores e velocidade de largura de banda da memória. | ||||||
| 8 | A6000 | 24/48 GB | TGI | 128 | 707 | 2 |
| 9 | A6000 | 2 x 24/48 GB | TGI | 128 | 1205 | 2 |
Configurando e configurando TGI para alto rendimento
Configure a solicitação assíncrona em uma linguagem de script de sua preferência, como python/ruby, e use o mesmo arquivo de configuração que encontramos:
- O tempo gasto aumenta em relação ao comprimento máximo de saída da geração de sequência.
- 128/256 threads no cliente e no servidor são melhores que 24, 64, 512. Ao usar threads inferiores, a computação está sendo subutilizada e além de um limite como 128, a sobrecarga se torna maior e, portanto, a taxa de transferência é reduzida.
- Há uma melhoria de 6% ao saltar de solicitações assíncronas para paralelas usando 'GNU paralelo' em vez de threading em linguagens como Go, Python/Ruby.
- O 4090 tem rendimento 12% maior que o A6000. Embora o 4090 tenha menos vRAM em comparação com o A6000, ele apresenta desempenho superior devido à maior contagem de núcleos tensores e velocidade de largura de banda da memória.
- Como o A6000 possui 48GB de vRAM, para concluir se a RAM extra ajuda a melhorar o rendimento ou não, tentamos usar frações de memória da GPU no experimento 8 da tabela, vemos que a RAM extra ajuda na melhoria, mas não linearmente. Além disso, quando tentamos dividir, ou seja, hospedar 2 APIs na mesma GPU usando metade da memória para cada API, ele se comporta como 2 APIs sequenciais em execução, em vez de aceitar solicitações paralelamente.
Observações e Métricas
Abaixo estão os gráficos de alguns experimentos e o tempo necessário para concluir um conjunto de entradas fixas. Quanto menor o tempo necessário, melhor.
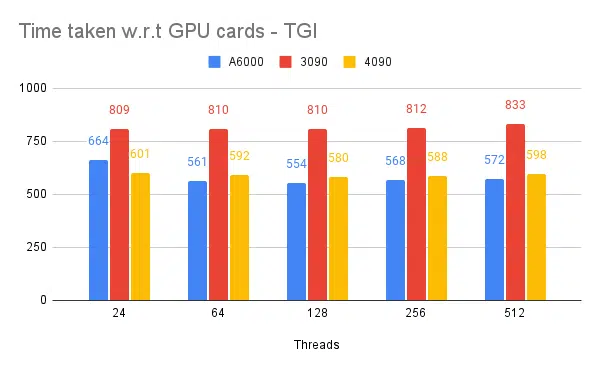
- Mencionados são os threads do lado do cliente. Lado do servidor que precisamos mencionar ao iniciar o mecanismo de inferência.
Especular testes:

Teste de vários mecanismos de inferência:
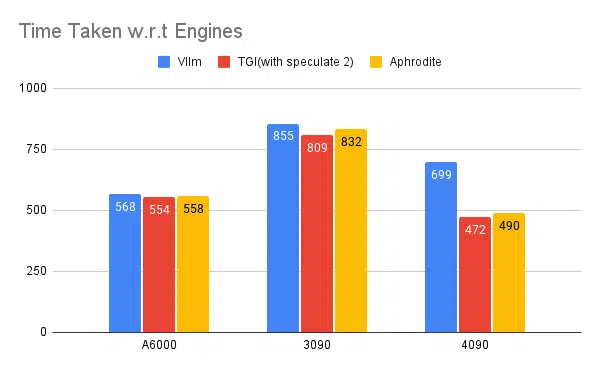
Mesmo tipo de experimentos feitos com outros mecanismos como vLLM e Afrodite, observamos resultados semelhantes, no momento em que escrevemos este artigo, vLLM e Afrodite ainda não suportam decodificação especulativa, o que nos deixa escolher TGI, pois oferece maior rendimento do que o restante devido à decodificação especulativa.
Além disso, você pode configurar criadores de perfil de GPU para melhorar a observabilidade, auxiliando na identificação de áreas com uso excessivo de recursos e otimizando o desempenho. Leia mais: Ferramentas de desenvolvedor Nvidia Nsight - Max Katz
Conclusão
Vemos que o cenário da geração de inferência está em constante evolução e melhorar o rendimento no LLM requer um bom entendimento da GPU, métricas de desempenho, técnicas de otimização e desafios associados às tarefas de geração de texto. Isso ajuda na escolha das ferramentas certas para o trabalho. Ao compreender os componentes internos da GPU e como eles correspondem à inferência LLM, como aproveitar núcleos tensores e maximizar a largura de banda da memória, os desenvolvedores podem escolher a GPU econômica e otimizar o desempenho de forma eficaz.
Diferentes placas GPU oferecem recursos variados, e compreender as diferenças é crucial para selecionar o hardware mais adequado para tarefas específicas. Técnicas como lote contínuo, atenção paginada, fusão de kernel e atenção flash oferecem soluções promissoras para superar os desafios emergentes e melhorar a eficiência. TGI parece a melhor escolha para nosso caso de uso com base nos experimentos e resultados que obtemos.
Leia outros artigos relacionados ao modelo de linguagem grande:
Compreendendo a arquitetura de GPU para otimização de inferência LLM
Técnicas avançadas para melhorar o rendimento do LLM