
Guia passo a passo para construir um rastreador da Web
Publicados: 2023-12-05Na intricada tapeçaria da Internet, onde a informação está espalhada por inúmeros websites, os web crawlers surgem como heróis desconhecidos, trabalhando diligentemente para organizar, indexar e tornar acessível esta riqueza de dados. Este artigo inicia uma exploração de web crawlers, esclarecendo seu funcionamento fundamental, distinguindo entre web crawling e web scraping e fornecendo insights práticos, como um guia passo a passo para criar um web crawler simples baseado em Python. À medida que nos aprofundamos, descobriremos os recursos de ferramentas avançadas como o Scrapy e descobriremos como o PromptCloud eleva o rastreamento da web a uma escala industrial.
O que é um rastreador da Web
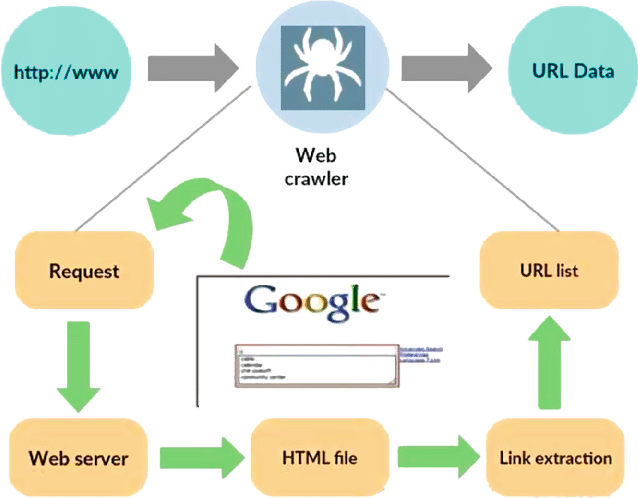
Fonte: https://www.researchgate.net/figure/Working-model-of-web-crawler_fig1_316089973
Um web crawler, também conhecido como spider ou bot, é um programa especializado projetado para navegar de forma sistemática e autônoma pela vasta extensão da World Wide Web. Sua função principal é percorrer sites, coletar dados e indexar informações para diversos fins, como otimização de mecanismos de pesquisa, indexação de conteúdo ou extração de dados.
Basicamente, um rastreador da web imita as ações de um usuário humano, mas em um ritmo muito mais rápido e eficiente. Ele inicia sua jornada a partir de um ponto de partida designado, geralmente chamado de URL inicial, e depois segue hiperlinks de uma página da web para outra. Esse processo de seguir links é recursivo, permitindo ao rastreador explorar uma parte significativa da internet.
À medida que o rastreador visita páginas da web, ele extrai e armazena sistematicamente dados relevantes, que podem incluir texto, imagens, metadados e muito mais. Os dados extraídos são então organizados e indexados, facilitando aos motores de busca a recuperação e apresentação de informações relevantes aos usuários quando consultados.
Os rastreadores da Web desempenham um papel fundamental na funcionalidade de mecanismos de pesquisa como Google, Bing e Yahoo. Ao rastrear contínua e sistematicamente a web, eles garantem que os índices dos mecanismos de pesquisa estejam atualizados, fornecendo aos usuários resultados de pesquisa precisos e relevantes. Além disso, os rastreadores da web são utilizados em vários outros aplicativos, incluindo agregação de conteúdo, monitoramento de sites e mineração de dados.
A eficácia de um rastreador da web depende de sua capacidade de navegar em diversas estruturas de sites, lidar com conteúdo dinâmico e respeitar as regras definidas pelos sites por meio do arquivo robots.txt, que descreve quais partes de um site podem ser rastreadas. Compreender como funcionam os rastreadores da web é fundamental para avaliar sua importância em tornar a vasta rede de informações acessível e organizada.
Como funcionam os rastreadores da Web
Os rastreadores da Web, também conhecidos como spiders ou bots, operam por meio de um processo sistemático de navegação na World Wide Web para coletar informações de sites. Aqui está uma visão geral de como funcionam os rastreadores da web:
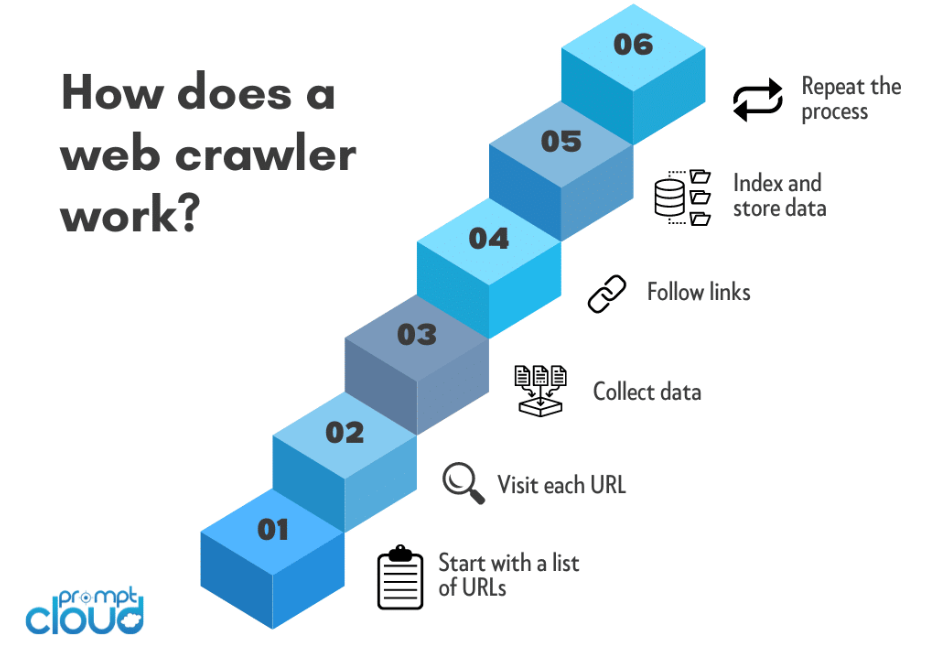
Seleção de URL inicial:
O processo de rastreamento da web normalmente começa com um URL inicial. Esta é a página da web ou site inicial a partir da qual o rastreador inicia sua jornada.
Solicitação HTTP:
O rastreador envia uma solicitação HTTP ao URL inicial para recuperar o conteúdo HTML da página da web. Esta solicitação é semelhante às solicitações feitas pelos navegadores da web ao acessar um site.
Análise de HTML:
Depois que o conteúdo HTML é obtido, o rastreador o analisa para extrair informações relevantes. Isso envolve dividir o código HTML em um formato estruturado que o rastreador possa navegar e analisar.
Extração de URL:
O rastreador identifica e extrai hiperlinks (URLs) presentes no conteúdo HTML. Esses URLs representam links para outras páginas que o rastreador visitará posteriormente.
Fila e Agendador:
Os URLs extraídos são adicionados a uma fila ou agendador. A fila garante que o rastreador visite os URLs em uma ordem específica, geralmente priorizando primeiro os URLs novos ou não visitados.
Recursão:
O rastreador segue os links da fila, repetindo o processo de envio de solicitações HTTP, análise de conteúdo HTML e extração de novos URLs. Este processo recursivo permite que o rastreador navegue por múltiplas camadas de páginas da web.
Extração de dados:
À medida que o rastreador percorre a web, ele extrai dados relevantes de cada página visitada. O tipo de dados extraídos depende da finalidade do rastreador e pode incluir texto, imagens, metadados ou outro conteúdo específico.
Indexação de conteúdo:
Os dados coletados são organizados e indexados. A indexação envolve a criação de um banco de dados estruturado que facilita a pesquisa, recuperação e apresentação de informações quando os usuários enviam consultas.
Respeitando Robots.txt:
Os rastreadores da Web geralmente seguem as regras especificadas no arquivo robots.txt de um site. Este arquivo fornece diretrizes sobre quais áreas do site podem ser rastreadas e quais devem ser excluídas.
Atrasos no rastreamento e educação:
Para evitar sobrecarregar os servidores e causar interrupções, os rastreadores geralmente incorporam mecanismos para atrasos e educação no rastreamento. Estas medidas garantem que o rastreador interage com os sites de maneira respeitosa e sem causar interrupções.
Os rastreadores da Web navegam sistematicamente na Web, seguindo links, extraindo dados e construindo um índice organizado. Esse processo permite que os mecanismos de pesquisa forneçam resultados precisos e relevantes aos usuários com base em suas consultas, tornando os rastreadores da web um componente fundamental do ecossistema moderno da Internet.

Rastreamento da Web vs. Web Scraping

Fonte: https://research.aimultiple.com/web-crawling-vs-web-scraping/
Embora o rastreamento e o web scraping sejam frequentemente usados de forma intercambiável, eles servem a propósitos distintos. O rastreamento da web envolve a navegação sistemática na web para indexar e coletar informações, enquanto o web scraping se concentra na extração de dados específicos de páginas da web. Em essência, o web crawling trata de explorar e mapear a web, enquanto o web scraping trata de coletar informações direcionadas.
Construindo um rastreador da Web
Construir um rastreador da web simples em Python envolve várias etapas, desde a configuração do ambiente de desenvolvimento até a codificação da lógica do rastreador. Abaixo está um guia detalhado para ajudá-lo a criar um rastreador da web básico usando Python, utilizando a biblioteca de solicitações para fazer solicitações HTTP e BeautifulSoup para análise de HTML.
Etapa 1: configurar o ambiente
Certifique-se de ter o Python instalado em seu sistema. Você pode baixá-lo em python.org. Além disso, você precisará instalar as bibliotecas necessárias:
pip install requests beautifulsoup4
Etapa 2: importar bibliotecas
Crie um novo arquivo Python (por exemplo, simple_crawler.py) e importe as bibliotecas necessárias:
import requests from bs4 import BeautifulSoup
Etapa 3: definir a função do rastreador
Crie uma função que receba uma URL como entrada, envie uma solicitação HTTP e extraia informações relevantes do conteúdo HTML:
def simple_crawler(url):
# Send HTTP request to the URL
response = requests.get(url)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Parse HTML content with BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Extract and print relevant information (modify as needed)
title = soup.title.text
print(f'Title: {title}')
# Additional data extraction and processing can be added here
else:
print(f'Error: Failed to fetch {url}')
Etapa 4: teste o rastreador
Forneça um URL de amostra e chame a função simple_crawler para testar o rastreador:
if __name__ == "__main__": sample_url = 'https://example.com' simple_crawler(sample_url)
Etapa 5: execute o rastreador
Execute o script Python em seu terminal ou prompt de comando:
python simple_crawler.py
O rastreador irá buscar o conteúdo HTML do URL fornecido, analisá-lo e imprimir o título. Você pode expandir o rastreador adicionando mais funcionalidades para extrair diferentes tipos de dados.
Rastreamento da Web com Scrapy
O rastreamento da Web com Scrapy abre a porta para uma estrutura poderosa e flexível projetada especificamente para web scraping eficiente e escalonável. Scrapy simplifica as complexidades da construção de rastreadores da web, oferecendo um ambiente estruturado para a criação de spiders que podem navegar em sites, extrair dados e armazená-los de maneira sistemática. Aqui está uma visão mais detalhada do rastreamento da web com Scrapy:
Instalação:
Antes de começar, certifique-se de ter o Scrapy instalado. Você pode instalá-lo usando:
pip install scrapy
Criando um projeto Scrapy:
Inicie um projeto Scrapy:
Abra um terminal e navegue até o diretório onde deseja criar seu projeto Scrapy. Execute o seguinte comando:
scrapy startproject your_project_name
Isso cria uma estrutura básica de projeto com os arquivos necessários.
Defina a aranha:
Dentro do diretório do projeto, navegue até a pasta spiders e crie um arquivo Python para o seu spider. Defina uma classe spider subclassificando scrapy.Spider e fornecendo detalhes essenciais como nome, domínios permitidos e URLs iniciais.
import scrapy
class YourSpider(scrapy.Spider):
name = 'your_spider'
allowed_domains = ['example.com']
start_urls = ['http://example.com']
def parse(self, response):
# Define parsing logic here
pass
Extraindo Dados:
Usando seletores:
Scrapy utiliza seletores poderosos para extrair dados de HTML. Você pode definir seletores no método de análise do spider para capturar elementos específicos.
def parse(self, response):
title = response.css('title::text').get()
yield {'title': title}
Este exemplo extrai o conteúdo de texto da tag <title>.
Seguintes Links:
Scrapy simplifica o processo de seguir links. Use o método follow para navegar para outras páginas.
def parse(self, response):
for next_page in response.css('a::attr(href)').getall():
yield response.follow(next_page, self.parse)
Executando a Aranha:
Execute seu spider usando o seguinte comando no diretório do projeto:
scrapy crawl your_spider
Scrapy iniciará o spider, seguirá os links e executará a lógica de análise definida no método de análise.
O rastreamento da Web com Scrapy oferece uma estrutura robusta e extensível para lidar com tarefas complexas de raspagem. Sua arquitetura modular e recursos integrados tornam-no a escolha preferida para desenvolvedores envolvidos em projetos sofisticados de extração de dados da web.
Rastreamento da Web em escala
O rastreamento da Web em grande escala apresenta desafios únicos, especialmente quando se trata de uma grande quantidade de dados espalhados por vários sites. PromptCloud é uma plataforma especializada projetada para agilizar e otimizar o processo de rastreamento da web em grande escala. Veja como o PromptCloud pode ajudar no gerenciamento de iniciativas de rastreamento da web em grande escala:
- Escalabilidade
- Extração e enriquecimento de dados
- Qualidade e precisão dos dados
- Gestão de Infraestrutura
- Fácil de usar
- Conformidade e Ética
- Monitoramento e relatórios em tempo real
- Suporte e Manutenção
PromptCloud é uma solução robusta para organizações e indivíduos que buscam realizar rastreamento da web em grande escala. Ao abordar os principais desafios associados à extração de dados em grande escala, a plataforma aumenta a eficiência, a confiabilidade e a capacidade de gerenciamento das iniciativas de rastreamento da web.
Resumindo
Os rastreadores da Web são heróis anônimos no vasto cenário digital, navegando diligentemente na Web para indexar, coletar e organizar informações. À medida que a escala dos projetos de rastreamento da web se expande, o PromptCloud surge como uma solução, oferecendo escalabilidade, enriquecimento de dados e conformidade ética para agilizar iniciativas de grande escala. Entre em contato conosco em sales@promptcloud.com