
Como fazer upload de dados para o BigQuery com R e Python
Publicados: 2023-06-06O mundo da análise da web continua a se aproximar da fatídica data de 1º de julho, quando o Universal Analytics para de processar dados e é substituído pelo Google Analytics 4 (GA4). Uma das principais mudanças é que no GA4 você só pode reter dados na plataforma por no máximo 14 meses. Essa é uma grande mudança em relação ao UA, mas, em troca, você pode enviar dados do GA4 para o BigQuery gratuitamente, até um limite.
O BigQuery é um recurso extremamente útil para armazenamento de dados além do GA4. Com ele se tornando mais importante do que nunca em alguns meses, é um bom momento para começar a usá-lo para todas as suas necessidades de armazenamento de dados. Frequentemente, será preferível manipular os dados de alguma forma antes do upload. Para isso, recomendamos o uso de um script escrito em R ou Python, principalmente se esse tipo de manipulação precisar ser feito repetidamente. Você também pode fazer upload de dados para o BigQuery diretamente desses scripts, e é exatamente sobre isso que este blog vai guiá-lo.
Fazendo upload para o BigQuery a partir do R
R é uma linguagem extremamente poderosa para ciência de dados e a mais fácil de trabalhar para fazer upload de dados para o BigQuery. O primeiro passo é importar todas as bibliotecas necessárias. Para este tutorial, precisaremos das seguintes bibliotecas:
library(googleAuthR)
library(bigQueryR)
Se você nunca usou essas bibliotecas antes, execute install.packages(<PACKAGE NAME>) no console para instalá-las.
Em seguida, devemos abordar o que costuma ser a parte mais complicada e consistentemente mais frustrante do trabalho com APIs – a autorização. Felizmente, com R, isso é relativamente simples. Você precisará de um arquivo JSON contendo credenciais de autorização. Isso pode ser encontrado no Google Cloud Console, o mesmo local onde o BigQuery está localizado. Primeiro, navegue até o Google Cloud Console e clique em 'APIs e serviços'.
Em seguida, clique em 'Credenciais' na barra lateral.
Na página Credenciais, você pode visualizar suas chaves de API existentes, IDs de cliente OAuth 2.0 e contas de serviço. Você vai querer um ID do cliente OAuth 2.0 para isso, então clique no botão de download no final da linha relevante para o seu ID ou crie um novo ID clicando em 'Criar credenciais' na parte superior da página. Certifique-se de que seu ID tenha permissão para visualizar e editar o projeto relevante do BigQuery. Para fazer isso, abra a barra lateral, passe o mouse sobre 'IAM and Admin' e clique em 'IAM'. Nesta página, você pode conceder à sua conta de serviço acesso ao projeto relevante usando o botão 'Conceder acesso' na parte superior da página.
Com o arquivo JSON obtido e salvo, você pode passar o caminho para ele com a função gar_set_client() para definir suas credenciais. O código completo para autorização está abaixo:
googleAuthR::gar_cache_empty()
googleAuthR::gar_set_client("C:\\Users\\Tom Brown\\Documents\\R\\APIs\\credentials.json")
bqr_auth(email = "<your email here>")
Obviamente, você desejará substituir o caminho na função gar_set_client() pelo caminho para seu próprio arquivo JSON e inserir o endereço de e-mail que você usa para acessar o BigQuery na função bqr_auth().
Depois que a autorização estiver toda configurada, precisamos de alguns dados para carregar no BigQuery. Precisamos colocar esses dados em um dataframe. Para os fins deste artigo, criarei alguns dados fictícios com vários locais e contagens de vendas, mas provavelmente você lerá dados reais de um arquivo .csv ou planilha. Para ler dados de um arquivo .csv, basta usar a função read.csv(), passando como argumento o caminho para o arquivo:
data <- read.csv("C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv")
Alternativamente, se você tiver seus dados armazenados em uma planilha, seu método irá variar dependendo de onde esta planilha está localizada. Se sua planilha estiver armazenada no Planilhas Google, você poderá ler seus dados em R usando a biblioteca googlesheets4:
library(googlesheets4)
data <- read_sheet(ss=”<spreadsheet URL>”, sheet=”<name of tab>”)
Como antes, se você não usou este pacote antes, você terá que executar install.packages(“googlesheets4”) no console antes de executar seu código.
Se a sua planilha for no Excel, você precisará usar a biblioteca readxl, que faz parte da biblioteca dirteverse – algo que eu recomendo usar. Ele contém um grande número de funções que tornam a manipulação de dados em R muito mais fácil:
library(tidyverse)
data <- read_excel(“C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx”)
E mais uma vez, certifique-se de executar install.package(“tidyverse”) se você ainda não o fez!
A etapa final é fazer upload dos dados para o BigQuery. Para isso, você precisará de um local no BigQuery para carregá-lo. Sua tabela estará localizada em um conjunto de dados, que estará localizado em um projeto, e você precisará dos nomes de todos os três no seguinte formato:
bqr_upload_data(“<your project>”, “<your dataset>”, “<your table>”, <your dataframe>)
No meu caso, isso significa que meu código lê:
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data)
Se sua tabela ainda não existe, não se preocupe, o código irá criá-la para você. Não se esqueça de inserir os nomes do seu projeto, conjunto de dados e tabela no código acima (entre aspas) e verifique se você está carregando o dataframe correto! Feito isso, você deverá visualizar seus dados no BigQuery, conforme abaixo:

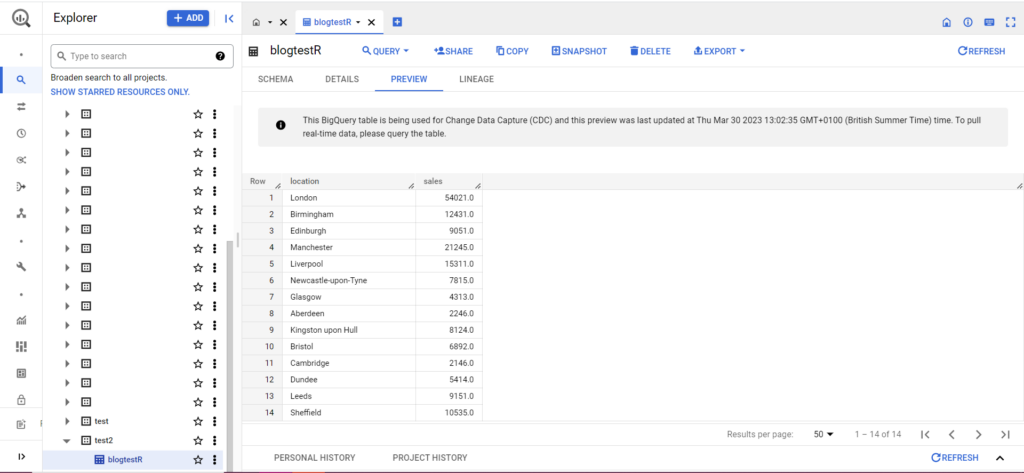
Como etapa final, digamos que você tenha dados adicionais que gostaria de adicionar ao BigQuery. Por exemplo, nos meus dados acima, digamos que esqueci de incluir alguns locais do continente e quero fazer upload para o BigQuery, mas não quero substituir os dados existentes. Para isso, bqr_upload_data possui um parâmetro chamado writeDisposition. writeDisposition tem duas configurações, “WRITE_TRUNCATE” e “WRITE_APPEND”. O primeiro diz a bqr_upload_data() para sobrescrever os dados existentes na tabela, enquanto o segundo diz para anexar os novos dados. Assim, para carregar esses novos dados, escreverei:
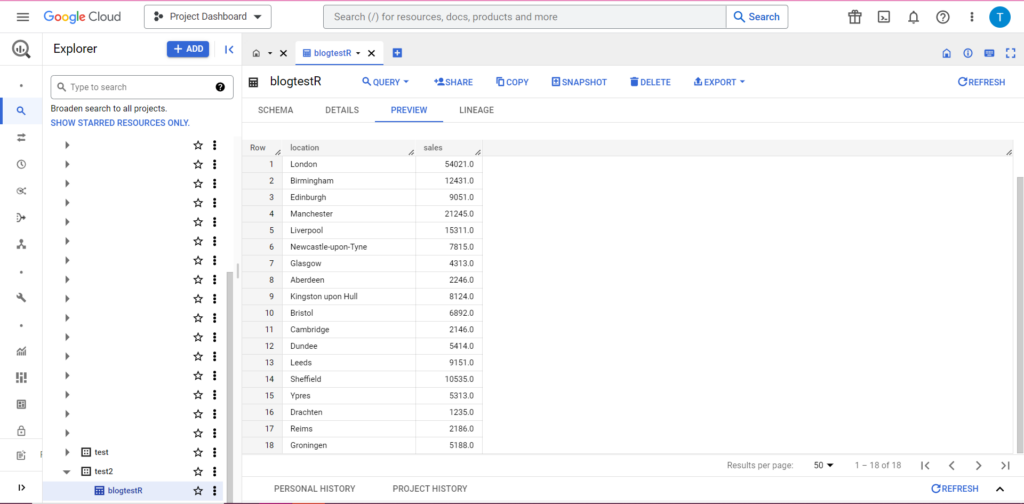
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data2, writeDisposition = “WRITE_APPEND”))
E com certeza, no BigQuery, podemos ver que nossos dados têm alguns novos colegas de quarto:
Fazendo upload para o BigQuery a partir do Python
Em Python, as coisas são um pouco diferentes. Mais uma vez, precisaremos importar alguns pacotes, então vamos começar com estes:
import pandas as pd
from google.cloud import bigquery
from google.oauth2 import service_account
A autorização é complicada. Mais uma vez, precisaremos de um arquivo JSON contendo credenciais. Como acima, navegaremos até o Console do Google Cloud e clicaremos em 'APIs e serviços' e, em seguida, clicaremos em 'Credenciais' na barra lateral. Desta vez, na parte inferior da página, haverá uma seção chamada 'Contas de serviço'.
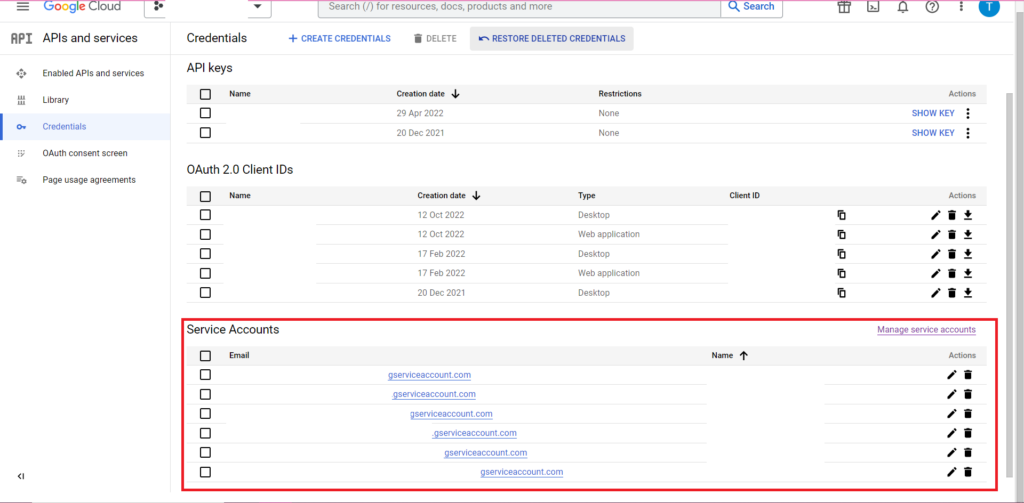
Lá você pode baixar a chave para sua conta de serviço ou, clicando em 'Gerenciar conta de serviço', você pode criar uma nova chave ou uma nova conta de serviço para a qual você pode baixar as credenciais.
Em seguida, você deseja garantir que sua conta de serviço tenha permissão para acessar e editar seu projeto do BigQuery. Mais uma vez, navegue até a página IAM em 'IAM & Admin' na barra lateral e lá você pode conceder à sua conta de serviço acesso ao projeto relevante usando o botão 'Conceder acesso' na parte superior da página.
Assim que resolver isso, você pode escrever o código de autorização:
bqcreds = service_account.Credentials.from_service_account_file('myjson.json', scopes = ['https://www.googleapis.com/auth/cloud-platform'])
client = bigquery.Client(credentials=bqcreds, project=bqcreds.project_id,)
Em seguida, você terá que colocar seus dados em um dataframe. Os dataframes pertencem ao pacote pandas e são muito simples de criar. Para ler a partir de um CSV, siga este exemplo:
data = pd.read_csv('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv')
Obviamente, você precisará substituir o caminho acima pelo do seu próprio arquivo CSV. Para ler a partir de um arquivo do Excel, siga este exemplo:
data = pd.read_excel('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx', sheet_name='mytab'>
A leitura do Planilhas Google é complicada e requer outra rodada de autorização. Precisamos importar alguns novos pacotes e usar o arquivo de credenciais JSON que recuperamos durante o tutorial do R acima. Você pode seguir este código para autorizar e ler seus dados:
import gspread
from oauth2client.service_account import ServiceAccountCredentials
credentials = ServiceAccountCredentials.from_json_keyfile_name('myjson.json', scopes = ['https://spreadsheets.google.com/feeds'])
gc = gspead.authorize(credentials)
ss = gc.open_by_key('<spreadsheet key>')
sheet = ss.worksheet('<name of tab>')
data = pd.DataFrame(sheet.get_all_records())
Depois de ter seus dados em seu dataframe, é hora de fazer o upload para o BigQuery novamente! Você pode fazer isso seguindo este modelo:
table_id = “<your project>.<your dataset>.<your table>”
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
Por exemplo, aqui está o código que acabei de escrever para carregar os dados que criei anteriormente:
table_
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
Feito isso, os dados devem aparecer imediatamente no BigQuery!
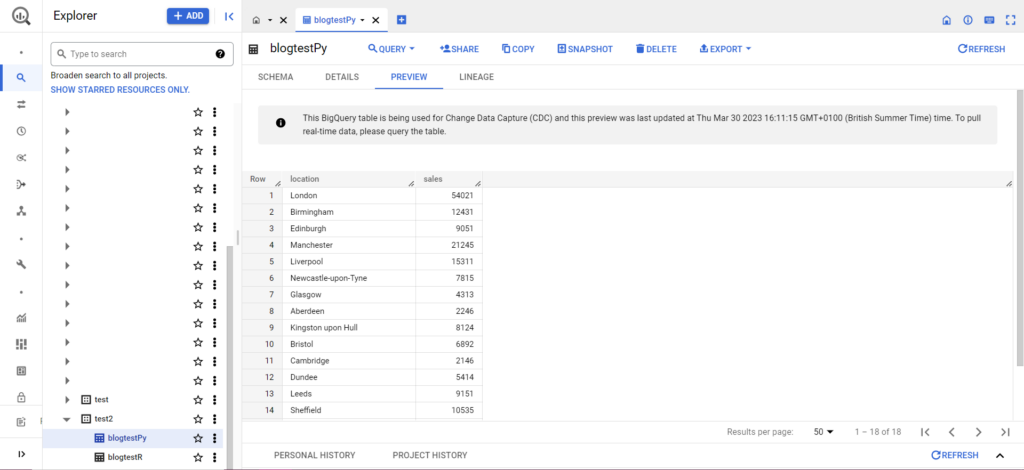
Há muito mais que você pode fazer com essas funções depois de pegar o jeito delas. Se você deseja ter maior controle sobre sua configuração de análise, a Semetrical está aqui para ajudar! Confira nosso blog para obter mais informações sobre como aproveitar ao máximo seus dados. Ou, para obter mais suporte em todas as análises, acesse Web Analytics para descobrir como podemos ajudá-lo.