
Rastreadores da Web – um guia completo
Publicados: 2023-12-12Rastreamento da Web
O rastreamento da Web, um processo fundamental no campo da indexação da Web e da tecnologia de mecanismos de pesquisa, refere-se à navegação automatizada na World Wide Web por um programa de software conhecido como rastreador da Web. Esses rastreadores, às vezes chamados de spiders ou bots, navegam sistematicamente na web para coletar informações de sites. Este processo permite a recolha e indexação de dados, o que é crucial para que os motores de busca forneçam resultados de pesquisa atualizados e relevantes.
Principais funções do rastreamento da Web:
- Indexação de conteúdo : os rastreadores da Web examinam páginas da Web e indexam seu conteúdo, tornando-o pesquisável. Esse processo de indexação envolve a análise de texto, imagens e outros conteúdos de uma página para compreender seu assunto.
- Análise de link : os rastreadores seguem links de uma página da web para outra. Isso não apenas ajuda a descobrir novas páginas da web, mas também a compreender os relacionamentos e a hierarquia entre as diferentes páginas da web.
- Detecção de atualização de conteúdo : ao revisitar regularmente as páginas da web, os rastreadores podem detectar atualizações e alterações, garantindo que o conteúdo indexado permaneça atualizado.
Nosso guia passo a passo para construir um rastreador da web ajudará você a entender mais sobre o processo de rastreamento da web.
O que é um rastreador da Web
Um rastreador da web, também conhecido como spider ou bot, é um programa de software automatizado que navega sistematicamente na World Wide Web com a finalidade de indexação da web. Sua função principal é digitalizar e indexar o conteúdo de páginas da web, que inclui texto, imagens e outras mídias. Os rastreadores da Web partem de um conjunto conhecido de páginas da Web e seguem os links dessas páginas para descobrir novas páginas, agindo como uma pessoa navegando na Web. Este processo permite que os mecanismos de pesquisa reúnam e atualizem seus dados, garantindo que os usuários recebam resultados de pesquisa atuais e abrangentes. O funcionamento eficiente dos web crawlers é essencial para manter o vasto e crescente repositório de informações online acessível e pesquisável.
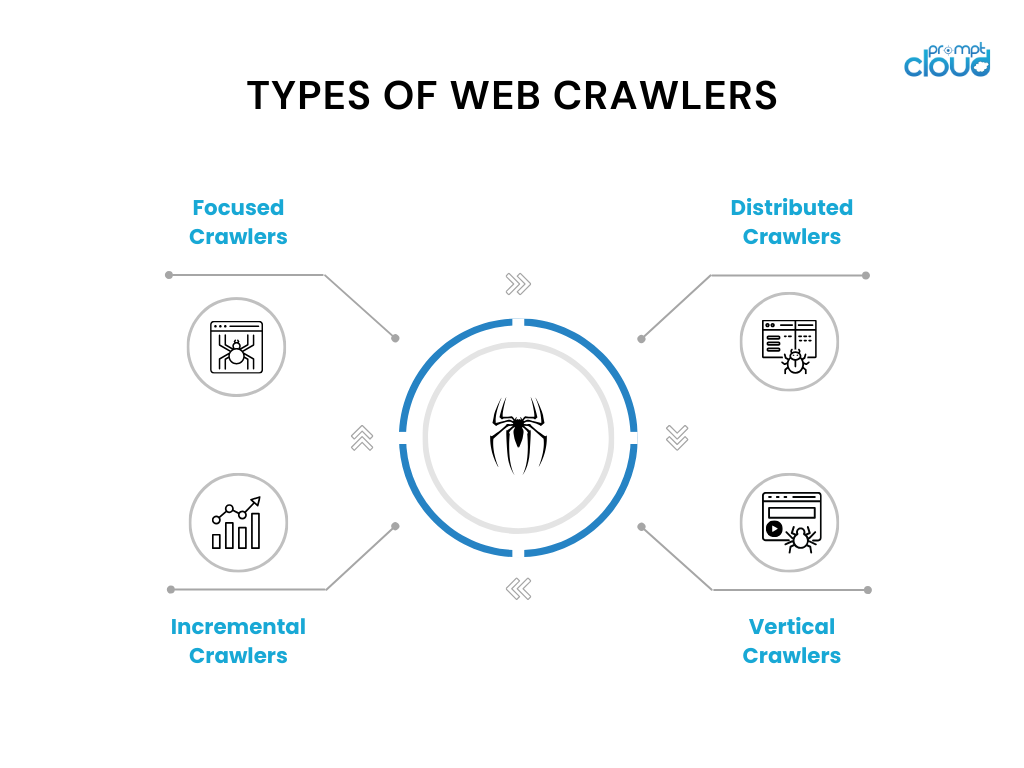
Como funciona um rastreador da Web
Os rastreadores da Web funcionam navegando sistematicamente na Internet para coletar e indexar o conteúdo do site, um processo crucial para os mecanismos de pesquisa. Eles partem de um conjunto de URLs conhecidos e acessam essas páginas da web para recuperar conteúdo. Ao analisar as páginas, eles identificam todos os hiperlinks e os adicionam à lista de URLs a serem visitados em seguida, mapeando efetivamente a estrutura da web. Cada página visitada é processada para extrair informações relevantes, como textos, imagens e metadados, que são então armazenados em um banco de dados. Esses dados tornam-se a base do índice de um mecanismo de pesquisa, permitindo fornecer resultados de pesquisa rápidos e relevantes.
Os rastreadores da Web devem operar dentro de certas restrições, como seguir regras definidas nos arquivos robots.txt pelos proprietários dos sites e evitar sobrecarregar os servidores, garantindo um processo de rastreamento ético e eficiente. À medida que navegam por milhares de milhões de páginas web, estes crawlers enfrentam desafios como lidar com conteúdos dinâmicos, gerir páginas duplicadas e manter-se atualizados com as mais recentes tecnologias web, tornando o seu papel no ecossistema digital complexo e indispensável. Aqui está um artigo detalhado sobre como funcionam os rastreadores da web.
Rastreador da Web Python
Python, conhecido por sua simplicidade e legibilidade, é uma linguagem de programação ideal para construir rastreadores da web. Seu rico ecossistema de bibliotecas e estruturas simplifica o processo de escrita de scripts que navegam, analisam e extraem dados da web. Aqui estão os principais aspectos que tornam o Python uma escolha ideal para rastreamento da web:
Principais bibliotecas Python para rastreamento da Web:
- Solicitações : esta biblioteca é usada para fazer solicitações HTTP para páginas da web. É simples de usar e pode lidar com diversos tipos de solicitações, essenciais para acessar o conteúdo de uma página web.
- Beautiful Soup : Especializado na análise de documentos HTML e XML, o Beautiful Soup permite fácil extração de dados de páginas web, simplificando a navegação pela estrutura de tags do documento.
- Scrapy : uma estrutura de rastreamento da web de código aberto, o Scrapy fornece um pacote completo para escrever rastreadores da web. Ele lida com solicitações, análise de respostas e extração de dados perfeitamente.
Vantagens de usar Python para rastreamento da Web:
- Facilidade de uso : a sintaxe direta do Python o torna acessível até mesmo para quem é iniciante em programação.
- Suporte robusto à comunidade : uma grande comunidade e uma grande quantidade de documentação ajudam na solução de problemas e na melhoria da funcionalidade do rastreador.
- Flexibilidade e escalabilidade : os rastreadores Python podem ser tão simples ou complexos quanto necessário, podendo ser dimensionados de projetos pequenos a grandes.
Exemplo de um rastreador da Web Python básico:
solicitações de importação

da importação bs4 BeautifulSoup
# Defina a URL para rastrear
url = “http://exemplo.com”
#Envia uma solicitação HTTP para a URL
resposta = solicitações.get(url)
# Analise o conteúdo HTML da página
sopa = BeautifulSoup(response.text, 'html.parser')
# Extraia e imprima todos os hiperlinks
para link em sopa.find_all('a'):
imprimir(link.get('href'))
Este script simples demonstra a operação básica de um rastreador da web Python. Ele busca o conteúdo HTML de uma página da web usando solicitações, analisa-o com Beautiful Soup e extrai todos os hiperlinks.
Os web crawlers Python se destacam pela facilidade de desenvolvimento e eficiência na extração de dados.
Seja para análise de SEO, mineração de dados ou marketing digital, o Python fornece uma base robusta e flexível para tarefas de rastreamento da web, tornando-o uma excelente escolha tanto para programadores quanto para cientistas de dados.
Casos de uso de rastreamento da Web
O rastreamento da Web tem uma ampla gama de aplicações em diferentes setores, refletindo sua versatilidade e importância na era digital. Aqui estão alguns dos principais casos de uso:
Indexação de mecanismos de pesquisa
O uso mais conhecido de rastreadores da web é feito por mecanismos de pesquisa como Google, Bing e Yahoo para criar um índice pesquisável da web. Os rastreadores examinam páginas da web, indexam seu conteúdo e as classificam com base em vários algoritmos, tornando-as pesquisáveis pelos usuários.
Mineração e análise de dados
As empresas usam rastreadores da web para coletar dados sobre tendências de mercado, preferências do consumidor e concorrência. Os pesquisadores empregam rastreadores para agregar dados de múltiplas fontes para estudos acadêmicos.
Monitoramento de SEO
Os webmasters usam rastreadores para entender como os mecanismos de pesquisa visualizam seus sites, ajudando a otimizar a estrutura, o conteúdo e o desempenho do site. Eles também são usados para analisar sites de concorrentes para entender suas estratégias de SEO.
Agregação de conteúdo
Os crawlers são usados por plataformas de agregação de notícias e conteúdo para coletar artigos e informações de diversas fontes. Agregar conteúdo de plataformas de mídia social para rastrear tendências, tópicos populares ou menções específicas.
Comércio eletrônico e comparação de preços
Os rastreadores ajudam a rastrear os preços dos produtos em diferentes plataformas de comércio eletrônico, auxiliando em estratégias de preços competitivas. Eles também são usados para catalogar produtos de vários sites de comércio eletrônico em uma única plataforma.
Listagens de imóveis
Os rastreadores reúnem listagens de imóveis de diversos sites imobiliários para oferecer aos usuários uma visão consolidada do mercado.
Listas de empregos e recrutamento
Agregar listas de empregos de vários sites para fornecer uma plataforma abrangente de busca de empregos. Alguns recrutadores usam rastreadores para vasculhar a web em busca de candidatos potenciais com qualificações específicas.
Aprendizado de máquina e treinamento de IA
Os rastreadores podem coletar grandes quantidades de dados da web, que podem ser usados para treinar modelos de aprendizado de máquina em diversas aplicações.
Web Scraping vs Rastreamento da Web
Web scraping e web crawling são duas técnicas comumente usadas na coleta de dados de sites, mas servem a propósitos diferentes e funcionam de maneiras distintas. Compreender as diferenças é fundamental para qualquer pessoa envolvida na extração de dados ou análise da web.
Raspagem da web
- Definição : Web scraping é o processo de extração de dados específicos de páginas da web. Seu foco é transformar dados não estruturados da web (geralmente formato HTML) em dados estruturados que podem ser armazenados e analisados.
- Extração de dados direcionada : a raspagem é frequentemente usada para coletar informações específicas de sites, como preços de produtos, dados de estoque, artigos de notícias, informações de contato, etc.
- Ferramentas e Técnicas : Envolve o uso de ferramentas ou programação (geralmente Python, PHP, JavaScript) para solicitar uma página web, analisar o conteúdo HTML e extrair as informações desejadas.
- Casos de uso : pesquisa de mercado, monitoramento de preços, geração de leads, dados para modelos de aprendizado de máquina, etc.
Rastreamento da Web
- Definição : o rastreamento da Web, por outro lado, é o processo de navegar sistematicamente na Web para baixar e indexar conteúdo da Web. Está principalmente associado aos motores de busca.
- Indexação e acompanhamento de links : rastreadores, ou spiders, são usados para visitar uma ampla variedade de páginas para entender a estrutura e os links do site. Eles normalmente indexam todo o conteúdo de uma página.
- Automação e escala : o rastreamento da Web é um processo mais automatizado, capaz de lidar com a extração de dados em grande escala em muitas páginas da Web ou em sites inteiros.
- Considerações : Os rastreadores devem respeitar as regras definidas pelos sites, como as dos arquivos robots.txt, e são projetados para navegar sem sobrecarregar os servidores web.
Ferramentas de rastreamento da web
As ferramentas de rastreamento da Web são instrumentos essenciais na caixa de ferramentas digitais de empresas, pesquisadores e desenvolvedores, oferecendo uma maneira de automatizar a coleta de dados de vários sites na Internet. Essas ferramentas são projetadas para navegar sistematicamente em páginas da web, extrair informações úteis e armazená-las para uso posterior. Aqui está uma visão geral das ferramentas de rastreamento da web e seu significado:
Funcionalidade : As ferramentas de rastreamento da Web são programadas para navegar em sites, identificar informações relevantes e recuperá-las. Eles imitam o comportamento de navegação humano, mas fazem isso em escala e velocidade muito maiores.
Extração e indexação de dados : essas ferramentas analisam os dados em páginas da web, que podem incluir texto, imagens, links e outras mídias, e depois os organizam em um formato estruturado. Isto é particularmente útil para criar bases de dados de informações que podem ser facilmente pesquisadas e analisadas.
Personalização e flexibilidade : muitas ferramentas de rastreamento da web oferecem opções de personalização, permitindo que os usuários especifiquem quais sites rastrear, a profundidade da arquitetura do site e que tipo de dados extrair.
Casos de uso : são usados para diversos fins, como otimização de mecanismos de pesquisa (SEO), pesquisa de mercado, agregação de conteúdo, análise competitiva e coleta de dados para projetos de aprendizado de máquina.
Nosso artigo recente fornece uma visão geral detalhada das principais ferramentas de rastreamento da web em 2024. Confira o artigo para saber mais. Entre em contato conosco em [email protected] para soluções personalizadas de rastreamento da web.