
Raspagem de dados da Web na era do Big Data: oportunidades e dilemas éticos
Publicados: 2024-05-29Raspagem de dados da Web e análise de Big Data
A coleta de dados da Web emergiu como um mecanismo fundamental para a coleta de dados online. Este processo envolve a recuperação automatizada de informações de sites, transformando a web não estruturada em uma riqueza de dados estruturados prontos para análise.
Fonte da imagem: https://www.sas.com/
Ao mesmo tempo, a análise de big data conquistou um nicho no discernimento de padrões, tendências e insights a partir dos enormes conjuntos de dados acumulados, muitas vezes por meio da coleta de dados da web. À medida que grandes volumes de dados (aproximadamente 2,5 quintilhões de bytes de dados gerados a cada dia) se tornam mais acessíveis, a síntese da coleta de dados da Web com a análise de big data abre uma infinidade de possibilidades para empresas, pesquisadores e formuladores de políticas.
Ao combinar habilmente estas capacidades tecnológicas, posicionam-se para capitalizar a tomada de decisões orientada por dados, estimular inovações de serviços e moldar empreendimentos estratégicos adaptados aos seus objectivos. No entanto, é essencial reconhecer o surgimento de dilemas éticos resultantes da relação sinérgica entre estas ferramentas avançadas.
Uma linha tênue deve ser cuidadosamente traçada em relação ao equilíbrio crucial entre a maximização do valor dos dados e a preservação dos direitos de privacidade dos indivíduos, garantindo que nenhum aspecto ofusque o outro.
Benefícios da raspagem de dados da Web para projetos de Big Data
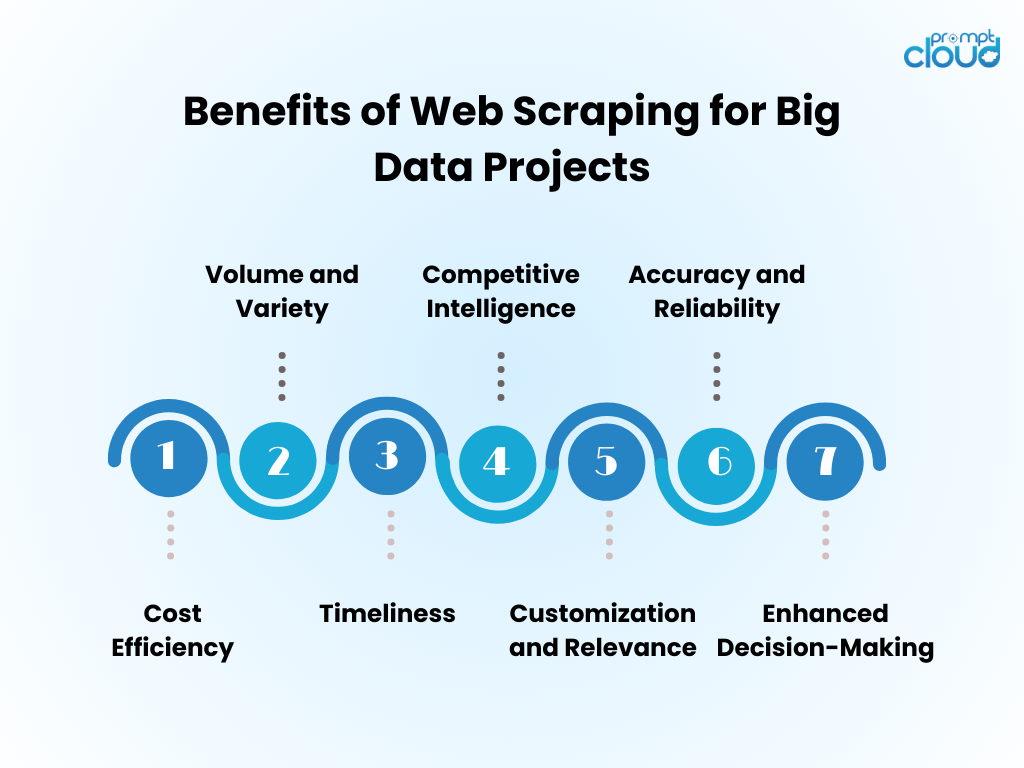
- Eficiência de custos : automatizar a coleta de dados por meio de web scraping reduz significativamente os custos de mão de obra humana e acelera o tempo de obtenção de insights.
- Volume e variedade : permite a captura de grandes quantidades de dados de diversas fontes, essenciais para alimentar análises de big data.
- Oportunidade : Web scraping fornece dados em tempo real ou quase em tempo real, permitindo respostas mais ágeis às tendências do mercado.
- Inteligência Competitiva : capacita as organizações com a capacidade de monitorar de perto os concorrentes e as mudanças do setor.
- Personalização e Relevância : Os dados podem ser adaptados às necessidades específicas, garantindo que a análise seja relevante e focada.
- Precisão e confiabilidade : a raspagem automatizada minimiza o erro humano, levando a conjuntos de dados mais precisos.
- Tomada de decisões melhorada : O acesso a dados oportunos e relevantes apoia a tomada de decisões informadas e o planeamento estratégico.
Técnicas de Web Scraping: do básico ao avançado

Fonte da imagem: loginworks
A raspagem de dados da Web evoluiu com a tecnologia, começando com técnicas básicas que avançam à medida que a complexidade dos dados aumenta.
- Técnicas Básicas : Inicialmente, os scrapers recuperam dados usando solicitações HTTP simples para obter páginas HTML, analisando o conteúdo por meio de bibliotecas como Beautiful Soup em Python. Essas ferramentas podem lidar adequadamente com sites descomplicados.
- Técnicas intermediárias : para conteúdo dinâmico, as técnicas evoluem para incluir ferramentas de automação como o Selenium, que pode interagir com JavaScript e imitar o comportamento do navegador.
- Técnicas avançadas : avançando em direção à raspagem avançada, os métodos incorporam navegadores sem cabeça e servidores proxy para navegar pelas medidas anti-raspagem. A extração de dados torna-se sofisticada com algoritmos de aprendizado de máquina, processando linguagem natural e imagens para recuperar informações.
- Considerações Éticas : Independentemente da complexidade da técnica, persistem dilemas éticos, necessitando de um equilíbrio entre o acesso aos dados e o respeito pela privacidade e propriedade.
Incorporando dados extraídos da Web em análises de Big Data
Os dados coletados na Web, quando integrados à análise de big data, podem revelar insights abrangentes de mercado e tendências de consumo. Os analistas combinam informações coletadas na web com conjuntos de dados existentes, aumentando a profundidade e a amplitude dos resultados analíticos. Esse amálgama gera modelos preditivos aprimorados, estratégias de marketing personalizadas e perfis de consumidor refinados.

- Limpeza de dados: os dados extraídos requerem uma limpeza meticulosa para garantir a precisão das análises.
- Integração de dados: A combinação de dados extraídos com outras fontes requer técnicas avançadas de integração de dados.
- Aprimoramento da análise: com dados adicionais, os algoritmos de aprendizado de máquina podem revelar padrões mais sutis.
- Consideração Ética: Os analistas devem garantir que o uso de dados da web esteja em conformidade com os padrões legais e éticos.
O conjunto aumentado de dados impulsiona a inovação, mas exige metodologia rigorosa e supervisão ética.
Melhores práticas para web scraping eficiente
- Respeite os protocolos robots.txt; não raspe sites que não permitem isso por meio de seu arquivo robots.
- Programe atividades de scraping fora dos horários de pico para minimizar o impacto no desempenho do servidor de destino.
- Utilize o cache para evitar a nova raspagem do mesmo conteúdo, respeitando os dados do site e economizando largura de banda.
- Implemente o tratamento de erros apropriado para evitar que seu scraper trave e para evitar o envio de muitas solicitações em caso de erros.
- Alterne agentes de usuário e endereços IP para evitar bloqueios, simulando um comportamento de navegação mais natural.
- Mantenha-se informado sobre as práticas legais e éticas de web scraping, garantindo que suas atividades de scraping não violem direitos autorais ou leis de privacidade.
- Otimize o código para ser eficiente e reduzir a carga no sistema de scraping e nos sites de destino.
- Atualize regularmente o código de scraping para se adaptar a quaisquer mudanças no layout ou tecnologia do site, mantendo a eficácia e a precisão da recuperação de dados.
- Armazene os dados coletados com segurança e gerencie-os em conformidade com todas as regulamentações relevantes de proteção de dados.
O futuro do Web Scraping na era do Big Data
À medida que o Big Data continua a se expandir, a coleta de dados da Web está prestes a se tornar ainda mais parte integrante da análise de dados e da inteligência de negócios. O futuro provavelmente verá:
- Modelos aprimorados de aprendizado de máquina treinados com vastos conjuntos de dados obtidos por meio de scraping, melhorando a precisão e os insights.
- Aumento da demanda por coleta de dados em tempo real, permitindo que as empresas tomem decisões mais rápidas e baseadas em dados.
- Desenvolvimento de ferramentas de raspagem mais sofisticadas para navegar em tecnologias anti-raspagem e manter práticas éticas de coleta de dados.
- Regulamentações e leis de privacidade mais rígidas moldam metodologias de coleta de dados da web, garantindo que os dados sejam coletados de forma responsável e com consentimento.
- O surgimento de plataformas de scraping como serviço, oferecendo extração de dados personalizada para empresas de todos os tamanhos.
Com esses avanços, o web scraping continuará a ser uma ferramenta crítica no kit de ferramentas de Big Data.
Caso a web scraping manual pareça assustadora ou se for necessária assistência para resolver desafios intrincados relacionados à obtenção de dados valiosos, tenha certeza de que o PromptCloud está pronto para ajudar!
Somos especializados em fornecer soluções abrangentes de web scraping projetadas explicitamente para iniciativas de big data, garantindo extração de dados confiável e em grande escala.
Confie em nós para lidar com os aspectos exigentes, permitindo que você se concentre na geração de escolhas bem informadas utilizando conjuntos de dados robustos e significativos. Entre em contato conosco em sales@promptcloud.com para descobrir como nossa experiência pode impulsionar seu plano de jogo de big data!