
O que é rotulagem de dados no aprendizado de máquina e como ela funciona?
Publicados: 2022-04-29Os dados são a nova riqueza para as empresas de hoje. Com tecnologias como a inteligência artificial assumindo progressivamente a maior parte do nosso dia a dia, o uso correto de qualquer dado vem influenciando positivamente a sociedade. Ao segregar e rotular os dados com eficiência, os algoritmos de ML podem descobrir os problemas e fornecer soluções práticas e relevantes.
Com a ajuda da rotulagem de dados, ensinamos várias técnicas à máquina e inserimos as informações em vários formatos para que se comportem de forma “inteligente”. A ciência por trás da rotulagem de dados envolve muito trabalho de casa na forma de anotar ou rotular os conjuntos de dados com múltiplas variações das mesmas informações. Embora o resultado final surpreenda e facilite o nosso dia-a-dia, o trabalho por trás do mesmo é imenso e a dedicação louvável.
O que é rotulagem de dados?
No aprendizado de máquina, a qualidade e o tipo de dados de entrada determinam a qualidade e o tipo de saída. A qualidade dos dados usados para treinar a máquina aumenta a precisão do seu modelo de IA.
Em outras palavras, rotulagem de dados é um processo para treinar uma máquina para encontrar as diferenças e semelhanças entre os conjuntos de dados estruturados ou não estruturados, rotulando-os ou anotando-os.
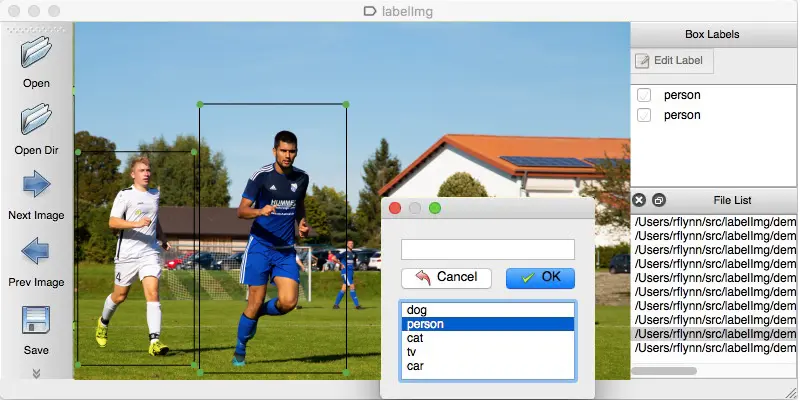
Vamos entender isso com um exemplo. Para treinar a máquina que a luz vermelha é o sinal para parar, você deve marcar todas as luzes vermelhas em várias fotos para que a máquina entenda o sinal. Com base nisso, a IA cria um algoritmo que lerá a luz vermelha como um sinal de parada em todos os cenários. Outro exemplo é que os gêneros musicais podem ser segregados com vários conjuntos de dados sob os rótulos jazz, pop, rock, clássico e muito mais.
Desafios na rotulagem de dados
Quaisquer novas mudanças/avanços em tecnologia ou estrutura trazem seus benefícios e desafios. Não é diferente para rotulagem de dados. Embora a rotulagem de dados possa diminuir drasticamente o tempo de dimensionamento de um negócio , ela tem um custo. Vamos nos debruçar sobre alguns dos desafios que a rotulagem de dados traz.
Custo em termos de tempo e esforço
É uma tarefa desafiadora por si só obter os dados específicos do nicho em grandes quantidades. A adição manual de tags para cada item apenas aumenta a tarefa já demorada. Se o projeto for tratado internamente, a maior parte do tempo do projeto será gasto em tarefas relacionadas a dados, como coleta, preparação e rotulagem de dados.
Para gerenciar essas tarefas de forma eficaz, para que você faça o trabalho certo logo de cara, você precisará de rotuladoras especializadas com esse conhecimento específico. Este é também um empreendimento caro, o que o torna caro, não apenas em termos de tempo, mas também em dinheiro.
Inconsistência
Anotadores com experiência diferente podem ter critérios de rotulagem diferentes. Consequentemente, há uma grande possibilidade de marcação inconsistente. Dito isto, quando várias pessoas rotulam o mesmo conjunto de dados, as taxas de precisão dos dados serão muito maiores.
Conhecimento de domínio
Para setores específicos, você sentirá a necessidade de contratar rotuladores com experiência em domínio específico. Por exemplo, para criar um aplicativo de ML para o setor de saúde , os anotadores sem experiência relevante no domínio acharão muito desafiador marcar os elementos corretamente.
Imperfeições
Qualquer trabalho repetitivo feito por humanos é propenso a erros. Qualquer que seja o nível de experiência que o rotulador humano possa ter, a marcação manual sempre terá o escopo da imperfeição. Garantir zero erros é quase impossível, pois os anotadores precisam lidar com grandes conjuntos de dados brutos para rotulagem.
Abordagens para rotulagem de dados
Como mencionado acima, a rotulagem de dados é uma tarefa demorada que requer atenção aos detalhes. Com base na declaração do problema, na quantidade de dados a serem marcados, na complexidade dos dados e no estilo, a estratégia aplicada para anotar os dados varia.
Vamos rever várias abordagens que sua empresa pode optar com base nos recursos financeiros e tempo disponível.
Rotulagem de dados interna
Com base no tipo de setor, tempo disponível para concluir o projeto de IA fornecido e a disponibilidade dos recursos necessários, o processo de etiqueta de dados pode ser realizado internamente pelas organizações.
Prós:
- Alta precisão
- Alta qualidade
- Acompanhamento simplificado
Contras:
- Demorado/lento
- Exigir recursos extensivos
Crowdsourcing
Os conjuntos de dados de sourcing rotulados por freelancers estão disponíveis em várias plataformas de crowdsourcing. Este método pode ser usado para anotar dados generalizados como imagens.
O exemplo mais famoso de rotulagem de dados por meio de crowdsourcing é o Recaptcha. O usuário é solicitado a identificar tipos específicos de imagens para provar que são humanos. Estes são verificados com base nas entradas fornecidas por outros usuários. Isso funciona como um banco de dados de rótulos para uma matriz de imagens.
Prós:
- Rápido e fácil
- Custo-beneficio
Contras:
- Não pode ser usado para dados que exigem experiência no domínio
- A qualidade não é garantida
Terceirização
A terceirização pode atuar como um meio-termo entre a rotulagem de dados interna e o crowdsourcing. A contratação de organizações terceirizadas ou indivíduos com experiência no domínio pode ajudar as organizações em todos os projetos – de longo e curto prazo.
Prós:
- Ideal para projetos temporários de alto nível
- Empresas terceirizadas de terceirização fornecem pessoal qualificado
- Fornece ferramentas de rotulagem de dados pré-criadas e personalizadas de acordo com suas necessidades de negócios
- Pode obter a opção de especialistas em rotulagem de dados específicos de nicho
Contras:
- Gerenciar o terceiro pode ser demorado
Baseado em máquina
Uma das formas mais recentes de rotulagem e anotação de dados amplamente utilizada e aceita pelas indústrias é a anotação baseada em máquina. Automatizar o processo de rotulagem de dados com a ajuda do software de rotulagem de dados reduz a intervenção humana e aumenta a velocidade com que a rotulagem pode ser feita. Com a técnica chamada de aprendizado ativo, os dados podem ser marcados com base nos quais as tags podem ser adicionadas aos conjuntos de dados de treinamento automaticamente.
Prós:
- Processamento e rotulagem de dados mais rápidos
- Envolve menor intervenção humana
Contras:
- Embora de melhor qualidade, mas não a par da marcação humana
- Em caso de erros, a intervenção humana ainda é necessária

Como funciona a rotulagem de dados?
Com base em suas necessidades de negócios, você pode escolher a abordagem que melhor se adapta às suas necessidades. No entanto, o processo de rotulagem de dados funciona na seguinte ordem cronológica.
Coleção de dados
A base de qualquer projeto de aprendizado de máquina são os dados. A coleta da quantidade certa de dados brutos em vários formatos compreende a primeira etapa da rotulagem de dados. A coleta de dados pode ser de duas formas – uma que a empresa vem coletando internamente e outra, que é coletada de fontes externas que estão disponíveis publicamente.
Estando na forma bruta, esses dados requerem limpeza e processamento antes de criar os rótulos para os conjuntos de dados. Esses dados limpos e pré-processados são então alimentados ao modelo para treinamento. Quanto maiores e mais diversificados forem os dados, mais precisos serão os resultados.
Anotação de dados
Depois que os dados são limpos, os especialistas do domínio analisam os dados e adicionam rótulos seguindo várias abordagens de rotulagem de dados. O contexto significativo é anexado ao modelo que pode ser usado como verdade básica . Essas são as variáveis de destino, como imagens que você deseja que o modelo preveja.

Garantia da Qualidade
O sucesso do treinamento do modelo de ML depende muito da qualidade dos dados que devem ser confiáveis, precisos e consistentes. Para garantir esses rótulos de dados precisos e precisos, deve haver verificações regulares de controle de qualidade. Com o uso de algoritmos de QA como o Consensus e o teste alfa de Cronbach, a precisão dessas anotações pode ser determinada. Verificações regulares de controle de qualidade contribuem muito para a precisão dos resultados.
Treinamento e teste de modelos
A execução de todas as etapas acima só faz sentido se os dados forem testados quanto à precisão. A entrada do conjunto de dados não estruturado para ver se ele entrega os resultados esperados testará o processo.
Casos de uso do setor para rotulagem de dados
Agora que estamos familiarizados com o que é rotulagem de dados e como ela funciona, vamos revisar os casos de uso mais importantes.
Visão Computacional (CV)
Este é um subconjunto de IA que permite que as máquinas obtenham uma interpretação significativa das entradas fornecidas na forma de visuais e vídeos (imagens estáticas extraídas para marcação).
A anotação de visão computacional pode ser usada em vários setores para implementar os benefícios práticos da IA.
- Na indústria automotiva, rotular imagens e vídeos para segmentar estradas, edifícios, pedestres e outros objetos ajudará os veículos autônomos a distinguir entre essas entidades para evitar o contato na vida real.
- No setor de saúde, os sintomas da doença podem ser segmentados em um raio-X, ressonância magnética e tomografia computadorizada. Com a ajuda de imagens microscópicas, as doenças mais críticas podem ser diagnosticadas em um estágio inicial.
- Códigos QR, códigos de barras de etiquetas, etc. podem ser usados como etiquetas no setor de transporte e logística para rastrear mercadorias.
Processamento de linguagem natural (PLN)
Este é um subconjunto que permite que as máquinas de IA interpretem a linguagem e as estatísticas humanas. Derivando o significado do texto e da fala, o algoritmo pode analisar vários aspectos linguísticos.
A PNL é cada vez mais usada em muitas soluções corporativas .
- É comumente usado em todos os setores como assistente de e-mail, recurso de preenchimento automático, corretor ortográfico, segregando e-mails de spam e não spam e muito mais.
- Na forma de chatbots , as consultas básicas levantadas pelos clientes são interpretadas e respondidas sem intervenção humana em tempo real. Prevê-se que 70% das interações com os clientes serão gerenciadas por chatbots e aplicativos de mensagens móveis até o ano de 2023.
- Entender a polaridade negativa e positiva do texto para captar o sentimento do cliente está sendo feito pela rotulagem de dados no e-commerce.
A Appinventiv construiu com sucesso um aplicativo de mídia social para Vyrb que permite aos usuários enviar e receber mensagens de áudio otimizadas para wearables Bluetooth.

Visão geral do mercado de rotulagem de dados de IA
A rotulagem de dados é uma indústria florescente que nasce da tecnologia de IA . Como a rotulagem de dados depende em grande parte de dados precisos sendo fornecidos ao aprendizado de máquina, ela deve crescer nos próximos anos.
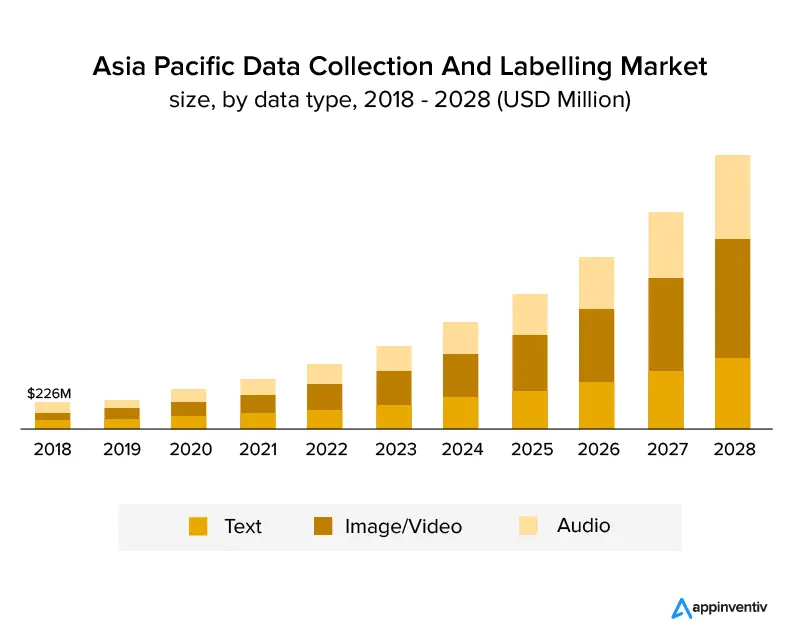
O gráfico abaixo mostra claramente que o setor cresceu e continuará crescendo nos próximos anos. Espera-se que cresça a um crescimento anual composto de 25,6% e alcance um tamanho de mercado de US$ 8,22 bilhões até 2028. O gráfico abaixo mostra o crescimento por tipo de dados.
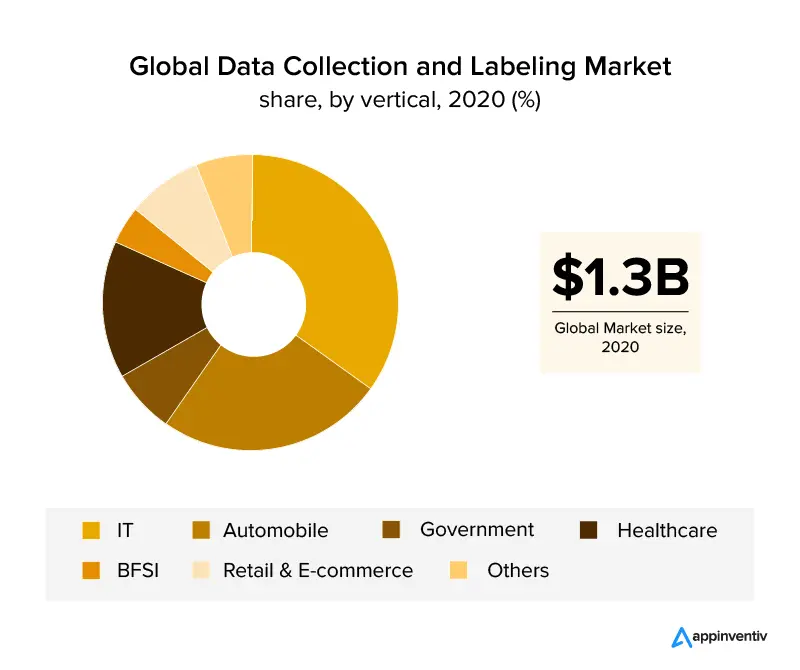
Uma visão geral das verticais de negócios que exploraram a rotulagem de dados são os setores de TI e automotivo, que cobrem mais de 30% da receita global. Com o crescimento do setor de saúde , espera-se que a rotulagem de dados cresça devido aos requisitos de dados precisos para aplicativos eficientes baseados em IA no setor. Com a ajuda da rotulagem de imagens, os setores de varejo e comércio eletrônico também garantiram uma participação de mercado significativa no setor de rotulagem de dados.
Rotulando dados com Appinventiv
Estrategicamente, as empresas terceirizam serviços de coleta e rotulagem de dados para construir modelos de aprendizado de máquina fortes.
A Appinventiv é uma empresa de desenvolvimento de IA e ML que ajuda organizações a desbloquear oportunidades com soluções orientadas por IA há muitos anos . Com quase uma década de experiência na transformação de negócios, entregamos muitos projetos complexos de IA para diferentes setores com sucesso.
Por exemplo, a Appinventiv automatizou com sucesso o processo bancário de um banco líder na Europa. O processo de automação ajudou o banco a melhorar a precisão em 50% e os níveis de serviço de ATM em 92%.
Outro exemplo em que a Appinventiv ajudou a YouCOMM a construir uma solução revolucionária para transformar a comunicação do paciente no hospital , fornecendo acesso em tempo real à ajuda médica. Com um sistema de mensagens de paciente personalizável, os pacientes podem notificar facilmente a equipe sobre suas necessidades por meio de comandos de voz e o uso de gestos de cabeça.
Com nossa experiência e equipe focada no cliente, fornecemos os serviços de rotulagem de dados que ajudarão você a superar os desafios, fornecendo serviços holísticos de rotulagem de dados com base em suas necessidades e requisitos específicos.
Ao aproveitar a vasta gama de ferramentas necessárias para marcação e anotação de dados, a Appinventiv pode aprimorar seus processos de treinamento de dados para simplificar modelos complexos. Isso nos permite superar em termos de precisão de segmentação, classificação e, posteriormente, rotulagem de dados que será rápida e fácil.
Empacotando!
“O poder da inteligência artificial é tão incrível que mudará a sociedade de maneiras muito profundas.” – Bill Gates
A inteligência artificial tem o potencial de facilitar a vida humana, fazendo assim o bem à sociedade. Sua capacidade de classificar grandes quantidades de dados em instruções significativas com a ajuda da rotulagem de dados ajudou as indústrias a avançar e crescer rapidamente.
Perguntas frequentes
P. Quais são as melhores práticas para aperfeiçoar a rotulagem de dados?
R. Com base na abordagem adotada para rotulagem de dados, há algumas práticas recomendadas que você pode seguir:
- Certifique-se de que os dados coletados sejam adequados, devidamente limpos e processados.
- Com base no setor, atribua o trabalho apenas a rotuladores de dados especializados de domínio.
- Garantir que uma abordagem uniforme seja seguida pela equipe, fornecendo-lhes os critérios de técnicas de anotação a serem seguidos.
- Siga um processo maker-checker atribuindo vários anotadores para rotulagem cruzada.
P. Quais são os benefícios da rotulagem de dados?
R. A rotulagem de dados ajuda a fornecer melhor clareza no contexto, qualidade e usabilidade para fazer uma previsão precisa dos dados. Isso, por sua vez, ajuda a melhorar a usabilidade dos dados das variáveis no modelo.
P. Quais são os vários elementos a serem considerados ao selecionar empresas de rotulagem de dados?
R. Há cinco parâmetros a serem considerados ao escolher os serviços de rótulo de dados para aprendizado de máquina.
- Escalabilidade do processo de rotulagem de dados
- Custo do serviço de rotulagem de dados
- Segurança de dados
- Plataforma de rotulagem de dados