
O que é Robots.txt em SEO: como criá-lo e otimizá-lo
Publicados: 2022-04-22O tópico de hoje não está diretamente relacionado à monetização do tráfego. Mas o robots.txt pode afetar o SEO do seu site e, eventualmente, a quantidade de tráfego que ele recebe. Muitos administradores da web arruinaram os rankings de seus sites devido a entradas incorretas do robots.txt. Este guia irá ajudá-lo a evitar todas essas armadilhas. Não deixe de ler até o final!
- O que é um arquivo robots.txt?
- Qual é a aparência de um arquivo robots.txt?
- Como encontrar seu arquivo robots.txt
- Como funciona um arquivo Robots.txt?
- Sintaxe de robots.txt
- Diretivas compatíveis
- Agente de usuário*
- Permitir
- Não permitir
- Mapa do site
- Diretivas sem suporte
- Atraso de rastreamento
- Sem índice
- Não siga
- Você precisa de um arquivo robots.txt?
- Criando um arquivo robots.txt
- Arquivo Robots.txt: práticas recomendadas de SEO
- Use uma nova linha para cada diretiva
- Use curingas para simplificar as instruções
- Use o cifrão “$” para especificar o final de um URL
- Use cada user agent apenas uma vez
- Use instruções específicas para evitar erros não intencionais
- Insira comentários no arquivo robots.txt com um hash
- Use arquivos robots.txt diferentes para cada subdomínio
- Não bloqueie um bom conteúdo
- Não abuse do atraso de rastreamento
- Preste atenção à diferenciação de maiúsculas e minúsculas
- Outras práticas recomendadas:
- Como usar o robots.txt para impedir a indexação de conteúdo
- Usando robots.txt para proteger conteúdo privado
- Usando robots.txt para ocultar conteúdo duplicado malicioso
- Acesso total para todos os bots
- Sem acesso para todos os bots
- Bloqueie um subdiretório para todos os bots
- Bloqueie um subdiretório para todos os bots (com um arquivo dentro do permitido)
- Bloqueie um arquivo para todos os bots
- Bloqueie um tipo de arquivo (PDF) para todos os bots
- Bloqueie todos os URLs parametrizados apenas para o Googlebot
- Como testar seu arquivo robots.txt quanto a erros
- URL enviado bloqueado por robots.txt
- Bloqueado por robots.txt
- Indexado, embora bloqueado por robots.txt
- Robots.txt vs meta robots vs x-robots
- Leitura adicional
- Empacotando
O que é um arquivo robots.txt?
O robots.txt, ou protocolo de exclusão de robôs, é um conjunto de padrões da web que controla como os robôs dos mecanismos de pesquisa rastreiam cada página da web, até as marcações de esquema nessa página. É um arquivo de texto padrão que pode até impedir que os rastreadores da Web obtenham acesso a todo o site ou a partes dele.
Ao ajustar o SEO e resolver problemas técnicos, você pode começar a obter receita passiva de anúncios. Uma única linha de código em seu site retorna pagamentos regulares!
Para o Conteúdo ↑Qual é a aparência de um arquivo robots.txt?
A sintaxe é simples: você fornece regras aos bots especificando seu agente de usuário e diretivas. O arquivo tem o seguinte formato básico:
Mapa do site: [local do URL do mapa do site]
User-agent: [identificador do bot]
[diretiva 1]
[diretiva 2]
[diretiva...]
User-agent: [outro identificador de bot]
[diretiva 1]
[diretiva 2]
[diretiva...]
Como encontrar seu arquivo robots.txt
Se o seu site já possui um arquivo robot.txt, você pode encontrá-lo acessando este URL: https://yourdomainname.com/robots.txt em seu navegador. Por exemplo, aqui está nosso arquivo
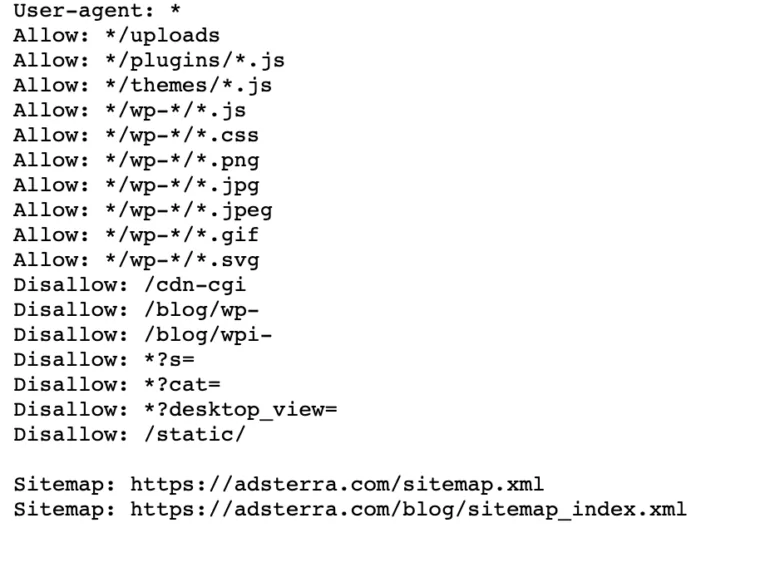
Como funciona um arquivo Robots.txt?
Um arquivo robots.txt é um arquivo de texto simples que não contém nenhum código de marcação HTML (daí a extensão .txt). Este arquivo, como todos os outros arquivos do site, é armazenado no servidor web. É improvável que os usuários visitem esta página porque ela não está vinculada a nenhuma de suas páginas, mas a maioria dos bots de rastreador da Web a pesquisa antes de rastrear todo o site.
Um arquivo robots.txt pode fornecer instruções aos bots, mas não pode impor essas instruções. Um bom bot, como um rastreador da web ou um bot de feed de notícias, verificará o arquivo e seguirá as instruções antes de visitar qualquer página de domínio. Mas os bots maliciosos irão ignorar ou processar o arquivo para encontrar páginas da web proibidas.
Em uma situação em que um arquivo robots.txt contém comandos conflitantes, o bot usará o conjunto de instruções mais específico.
Para o Conteúdo ↑Sintaxe de robots.txt
Um arquivo robots.txt consiste em várias seções de 'diretivas', cada uma começando com um agente do usuário. O user-agent especifica o bot de rastreamento com o qual o código se comunica. Você pode abordar todos os mecanismos de pesquisa de uma só vez ou gerenciar mecanismos de pesquisa individuais.
Sempre que um bot rastreia um site, ele age nas partes do site que o estão chamando.
Agente de usuário: *
Não permitir: /
Agente do usuário: Googlebot
Não permitir:
Agente do usuário: Bingbot
Não permitir: /não-para-bing/
Diretivas compatíveis
As diretivas são diretrizes que você deseja que os agentes do usuário que você declara sigam. Atualmente, o Google oferece suporte às diretivas a seguir.
Agente de usuário*
Quando um programa se conecta a um servidor web (um robô ou um navegador comum), ele envia um cabeçalho HTTP chamado “user-agent” contendo informações básicas sobre sua identidade. Todo mecanismo de pesquisa tem um agente do usuário. Os robôs do Google são conhecidos como Googlebot, os do Yahoo - como Slurp e os do Bing - como BingBot. O agente do usuário inicia uma sequência de diretivas, que podem ser aplicadas a agentes de usuário específicos ou a todos os agentes de usuário.
Permitir
A diretiva allow instrui os mecanismos de pesquisa a rastrear uma página ou subdiretório, mesmo um diretório restrito. Por exemplo, se você deseja que os mecanismos de pesquisa não consigam acessar todas as postagens do seu blog, exceto uma, seu arquivo robots.txt pode ter esta aparência:
Agente de usuário: *
Não permitir: /blog
Permitir: /blog/post-permitido
No entanto, os mecanismos de pesquisa podem acessar /blog/allowed-post, mas não conseguem obter acesso a:
/blog/outro-post
/blog/ainda-outro-post
/blog/download-me.pd
Não permitir
A diretiva disallow (que é adicionada ao arquivo robots.txt de um site) informa aos mecanismos de pesquisa para não rastrear uma página específica. Na maioria dos casos, isso também impedirá que uma página apareça nos resultados da pesquisa.
Você pode usar essa diretiva para instruir os mecanismos de pesquisa a não rastrear arquivos e páginas em uma pasta específica que você está ocultando do público em geral. Por exemplo, conteúdo em que você ainda está trabalhando, mas publicado por engano. Seu arquivo robots.txt pode ter esta aparência se você quiser impedir que todos os mecanismos de pesquisa acessem seu blog:
Agente de usuário: *
Não permitir: /blog
Isso significa que todos os subdiretórios do diretório /blog também não seriam rastreados. Isso também impediria o Google de acessar URLs contendo /blog.
Para o Conteúdo ↑Mapa do site
Os Sitemaps são uma lista de páginas que você deseja que os mecanismos de pesquisa rastreiem e indexem. Se você usar a diretiva sitemap, os mecanismos de pesquisa saberão a localização do seu sitemap XML. A melhor opção é submetê-los às ferramentas para webmasters dos mecanismos de pesquisa, pois cada uma pode fornecer informações valiosas sobre seu site para os visitantes.
É importante observar que a repetição da diretiva de mapa do site para cada agente de usuário é desnecessária e não se aplica a um agente de pesquisa. Adicione suas diretivas de sitemap no início ou no final do arquivo robots.txt.
Um exemplo de uma diretiva de sitemap no arquivo:
Mapa do site: https://www.domain.com/sitemap.xml
Agente do usuário: Googlebot
Não permitir: /blog/
Permitir: /blog/post-title/
Agente do usuário: Bingbot
Não permitir: /serviços/
Para o Conteúdo ↑Diretivas sem suporte
A seguir estão as diretivas que o Google não suporta mais – algumas das quais tecnicamente nunca foram endossadas.
Atraso de rastreamento
Yahoo, Bing e Yandex respondem rapidamente à indexação de sites e reagem à diretiva de atraso de rastreamento, que os mantém sob controle por um tempo.
Aplique esta linha ao seu bloco:
Agente do usuário: Bingbot
Atraso de rastreamento: 10
Isso significa que os mecanismos de pesquisa podem esperar dez segundos antes de rastrear o site ou dez segundos antes de acessar novamente o site após o rastreamento, que é a mesma coisa, mas um pouco diferente, dependendo do agente do usuário em uso.
Sem índice
A metatag noindex é uma ótima maneira de impedir que os mecanismos de pesquisa indexem uma de suas páginas. A tag permite que os bots acessem as páginas da web, mas também informa aos robôs para não indexá-las.
- Cabeçalho de resposta HTTP com tag noindex. Você pode implementar essa tag de duas maneiras: um cabeçalho de resposta HTTP com uma X-Robots-Tag ou uma tag <meta> colocada na seção <head>. É assim que sua tag <meta> deve ficar:
<meta name=”robots” content=”noindex”>
- Código de status HTTP 404 e 410. Os códigos de status 404 e 410 indicam que uma página não está mais disponível. Depois de rastrear e processar páginas 404/410, eles as removem automaticamente do índice do Google. Para reduzir o risco de páginas de erro 404 e 410, rastreie seu site regularmente e use redirecionamentos 301 para direcionar o tráfego para uma página existente quando necessário.
Não siga
O Nofollow orienta os mecanismos de pesquisa a não seguir links em páginas e arquivos em um caminho específico. Desde 1º de março de 2020, o Google não considera mais os atributos nofollow como diretivas. Em vez disso, eles serão dicas, bem como tags canônicas. Se você quiser um atributo “nofollow” para todos os links em uma página, use a metatag do robô, o cabeçalho x-robots ou o atributo de link rel= “nofollow” .
Anteriormente, você podia usar a seguinte diretiva para impedir que o Google seguisse todos os links do seu blog:
Agente do usuário: Googlebot
Não siga: /blog/
Você precisa de um arquivo robots.txt?
Muitos sites menos complexos não precisam de um. Embora o Google geralmente não indexe páginas da web bloqueadas pelo robots.txt, não há como garantir que essas páginas não apareçam nos resultados de pesquisa. Ter esse arquivo oferece mais controle e segurança do conteúdo do seu site em relação aos mecanismos de pesquisa.
Os arquivos de robôs também ajudam você a realizar o seguinte:
- Evite que o conteúdo duplicado seja rastreado.
- Mantenha a privacidade para diferentes seções do site.
- Restrinja o rastreamento interno de resultados de pesquisa.
- Evite a sobrecarga do servidor.
- Prevenir o desperdício do “rastreamento do orçamento”.
- Mantenha imagens, vídeos e arquivos de recursos fora dos resultados de pesquisa do Google.
Essas medidas acabam afetando suas táticas de SEO. Por exemplo, conteúdo duplicado confunde os mecanismos de pesquisa e os força a escolher qual das duas páginas deve ser classificada em primeiro lugar. Independentemente de quem criou o conteúdo, o Google não pode selecionar a página original para os principais resultados de pesquisa.

Nos casos em que o Google detecta conteúdo duplicado com o objetivo de enganar os usuários ou manipular as classificações, ele ajusta a indexação e a classificação do seu site. Como resultado, a classificação do seu site pode sofrer ou ser totalmente removida do índice do Google, desaparecendo dos resultados de pesquisa.
Manter a privacidade para diferentes seções do site também melhora a segurança do seu site e o protege contra hackers. A longo prazo, essas medidas tornarão seu site mais seguro, confiável e lucrativo.
Você é proprietário de um site que deseja lucrar com o tráfego? Com Adsterra, você obterá renda passiva de qualquer site!
Para o Conteúdo ↑Criando um arquivo robots.txt
Você precisará de um editor de texto como o Bloco de Notas.
- Crie uma nova planilha, salve a página em branco como 'robots.txt' e comece a digitar as diretivas no documento .txt em branco.
- Faça login no seu cPanel, navegue até o diretório raiz do site, procure a pasta public_html .
- Arraste seu arquivo para esta pasta e verifique novamente se a permissão do arquivo está definida corretamente.
Você pode escrever, ler e editar o arquivo como proprietário, mas terceiros não são permitidos. Um código de permissão “0644” deve aparecer no arquivo. Caso contrário, clique com o botão direito do mouse no arquivo e escolha “permissão de arquivo”.
Arquivo Robots.txt: práticas recomendadas de SEO
Use uma nova linha para cada diretiva
Você precisa declarar cada diretiva em uma linha separada. Caso contrário, os mecanismos de pesquisa ficarão confusos.
Agente de usuário: *
Não permitir: /diretório/
Não permitir: /outro-diretório/
Use curingas para simplificar as instruções
Você pode usar curingas (*) para todos os agentes do usuário e corresponder aos padrões de URL ao declarar diretivas. O curinga funciona bem para URLs que têm um padrão uniforme. Por exemplo, você pode querer impedir que todas as páginas de filtro com um ponto de interrogação (?) em seus URLs sejam rastreadas.
Agente de usuário: *
Não permitir: /*?
Use o cifrão “$” para especificar o final de um URL
Os mecanismos de pesquisa não podem acessar URLs que terminam em extensões como .pdf. Isso significa que eles não poderão acessar /file.pdf, mas poderão acessar /file.pdf?id=68937586, que não termina em “.pdf”. Por exemplo, se você deseja impedir que os mecanismos de pesquisa acessem todos os arquivos PDF em seu site, seu arquivo robots.txt pode ter esta aparência:
Agente de usuário: *
Não permitir: /*.pdf$
Use cada user agent apenas uma vez
No Google, não importa se você usa o mesmo user agent mais de uma vez. Ele simplesmente compilará todas as regras das várias declarações em uma única diretiva e a seguirá. No entanto, declarar cada agente do usuário apenas uma vez faz sentido porque é menos confuso.
Manter suas diretrizes organizadas e simples reduz o risco de erros críticos. Por exemplo, se seu arquivo robots.txt contivesse os seguintes agentes de usuário e diretivas.
Agente do usuário: Googlebot
Não permitir: /a/
Agente do usuário: Googlebot
Não permitir: /b/
Use instruções específicas para evitar erros não intencionais
Ao definir diretivas, deixar de fornecer instruções específicas pode gerar erros que podem prejudicar seu SEO. Suponha que você tenha um site multilíngue e esteja trabalhando em uma versão em alemão para o subdiretório /de/.
Você não quer que os mecanismos de pesquisa possam acessá-lo porque ainda não está pronto. O seguinte arquivo robots.txt impedirá que os mecanismos de pesquisa indexem essa subpasta e seu conteúdo:
Agente de usuário: *
Não permitir: /de
No entanto, ele impedirá que os mecanismos de pesquisa rastreiem quaisquer páginas ou arquivos que comecem com /de. Nesse caso, adicionar uma barra à direita é a solução simples.
Agente de usuário: *
Não permitir: /de/
Para o Conteúdo ↑Insira comentários no arquivo robots.txt com um hash
Os comentários ajudam os desenvolvedores e possivelmente até você a entender seu arquivo robots.txt. Inicie a linha com um hash (#) para incluir um comentário. Crawlers ignoram linhas que começam com um hash.
# Isso instrui o bot do Bing a não rastrear nosso site.
Agente do usuário: Bingbot
Não permitir: /
Use arquivos robots.txt diferentes para cada subdomínio
Robots.txt afeta apenas o rastreamento em seu domínio de host. Você precisará de outro arquivo para restringir o rastreamento em um subdomínio diferente. Por exemplo, se você hospedar seu site principal em example.com e seu blog em blog.example.com, precisará de dois arquivos robots.txt. Coloque um no diretório raiz do domínio principal, enquanto o outro arquivo deve estar no diretório raiz do blog.
Não bloqueie um bom conteúdo
Não use um arquivo robots.txt ou uma tag noindex para bloquear qualquer conteúdo de qualidade que você queira tornar público para evitar efeitos negativos nos resultados de SEO. Verifique cuidadosamente as tags noindex e não permita regras em suas páginas.
Não abuse do atraso de rastreamento
Explicamos o atraso do rastreamento, mas você não deve usá-lo com frequência porque ele limita os bots de rastrear todas as páginas. Pode funcionar para alguns sites, mas você pode estar prejudicando seus rankings e tráfego se tiver um site grande.
Preste atenção à diferenciação de maiúsculas e minúsculas
O arquivo Robots.txt diferencia maiúsculas de minúsculas, portanto, você precisa garantir a criação de um arquivo robots no formato correto. O arquivo robots deve ser nomeado 'robots.txt' com todas as letras minúsculas. Caso contrário, não vai funcionar.
Outras práticas recomendadas:
- Certifique-se de não bloquear o rastreamento do conteúdo ou das seções do seu site.
- Não use robots.txt para manter dados confidenciais (informações privadas do usuário) fora dos resultados da SERP. Use um método diferente, como criptografia de dados ou a metadiretiva noindex , para restringir o acesso se outras páginas vincularem diretamente à página privada.
- Alguns motores de busca têm mais de um agente de usuário. O Google, por exemplo, usa o Googlebot para pesquisas orgânicas e o Googlebot-Image para imagens. A especificação de diretivas para os vários rastreadores de cada mecanismo de pesquisa não é necessária porque a maioria dos agentes de usuário do mesmo mecanismo de pesquisa seguem as mesmas regras.
- Um mecanismo de pesquisa armazena em cache o conteúdo do robots.txt, mas os atualiza diariamente. Se você alterar o arquivo e quiser atualizá-lo mais rapidamente, envie o URL do arquivo para o Google.
Como usar o robots.txt para impedir a indexação de conteúdo
Desativar uma página é a maneira mais eficaz de impedir que os bots a rastreiem diretamente. No entanto, não funcionará nas seguintes situações:
- Se outra fonte tiver links para a página, os bots ainda a rastrearão e indexarão.
- Os bots ilegítimos continuarão a rastrear e indexar o conteúdo.
Usando robots.txt para proteger conteúdo privado
Alguns conteúdos privados, como PDFs ou páginas de agradecimento, ainda podem ser indexáveis mesmo se você bloquear os bots. Colocar todas as suas páginas exclusivas atrás de um login é uma das melhores maneiras de fortalecer a diretiva de proibição. Seu conteúdo permanecerá disponível, mas seus visitantes darão um passo a mais para acessá-lo.
Usando robots.txt para ocultar conteúdo duplicado malicioso
O conteúdo duplicado é idêntico ou muito semelhante a outro conteúdo no mesmo idioma. O Google tenta indexar e mostrar páginas com conteúdo exclusivo. Por exemplo, se o seu site tiver versões “regular” e “impressora” de cada artigo e uma tag noindex não bloquear nenhum deles, eles listarão um deles.
Exemplos de arquivos robots.txt
Veja a seguir alguns arquivos robots.txt de amostra. Estes são principalmente para ideias, mas se um deles atender às suas necessidades, copie e cole em um documento de texto, salve-o como “robots.txt” e faça o upload para o diretório apropriado.
Acesso total para todos os bots
Existem várias maneiras de informar aos mecanismos de pesquisa para acessar todos os arquivos, incluindo um arquivo robots.txt vazio ou nenhum.
Agente de usuário: *
Não permitir:
Sem acesso para todos os bots
O seguinte arquivo robots.txt instrui todos os mecanismos de pesquisa a evitar o acesso ao site inteiro:
Agente de usuário: *
Não permitir: /
Bloqueie um subdiretório para todos os bots
Agente de usuário: *
Não permitir: /pasta/
Bloqueie um subdiretório para todos os bots (com um arquivo dentro do permitido)
Agente de usuário: *
Não permitir: /pasta/
Permitir: /folder/page.html
Bloqueie um arquivo para todos os bots
Agente de usuário: *
Não permitir: /este-é-um-arquivo.pdf
Bloqueie um tipo de arquivo (PDF) para todos os bots
Agente de usuário: *
Não permitir: /*.pdf$
Bloqueie todos os URLs parametrizados apenas para o Googlebot
Agente do usuário: Googlebot
Não permitir: /*?
Como testar seu arquivo robots.txt quanto a erros
Erros no Robots.txt podem ser graves, por isso é importante monitorá-los. Verifique regularmente o relatório "Cobertura" no Search Console para problemas relacionados ao robot.txt. Alguns dos erros que você pode encontrar, o que eles significam e como corrigi-los estão listados abaixo.
URL enviado bloqueado por robots.txt
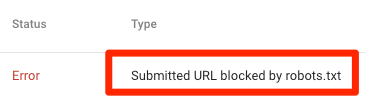
Indica que o robots.txt bloqueou pelo menos um dos URLs nos seus sitemaps. Se o seu sitemap estiver correto e não incluir páginas canonizadas, não indexadas ou redirecionadas, o robots.txt não deverá bloquear nenhuma página que você enviar. Se estiverem, identifique as páginas afetadas e remova o bloco do arquivo robots.txt.
Você pode usar o testador robots.txt do Google para identificar a diretiva de bloqueio. Tenha cuidado ao editar seu arquivo robots.txt, pois um erro pode afetar outras páginas ou arquivos.
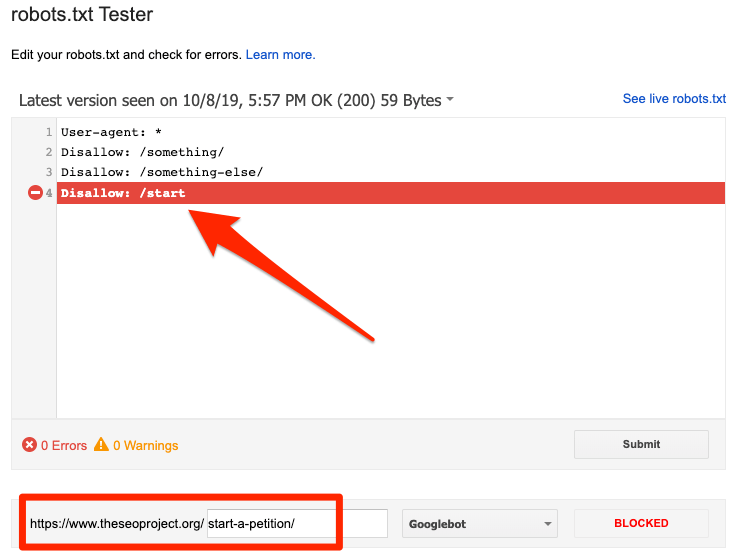
Bloqueado por robots.txt
Este erro indica que o robots.txt bloqueou conteúdo que o Google não pode indexar. Remova o bloco de rastreamento no robots.txt se esse conteúdo for crucial e precisar ser indexado. (Além disso, verifique se o conteúdo não é indexado.)
Se você quiser excluir conteúdo do índice do Google, use a metatag de um robô ou o cabeçalho x-robots e remova o bloco de rastreamento. Essa é a única maneira de manter o conteúdo fora do índice do Google.
Indexado, embora bloqueado por robots.txt
Isso significa que o Google ainda indexa parte do conteúdo bloqueado pelo robots.txt. Robots.txt não é a solução para impedir que seu conteúdo seja exibido nos resultados de pesquisa do Google.
Para evitar a indexação, remova o bloco de rastreamento e substitua-o por uma meta tag robots ou um cabeçalho HTTP x-robots-tag. Se você bloqueou acidentalmente este conteúdo e deseja que o Google o indexe, remova o bloqueio de rastreamento no robots.txt. Pode ajudar a melhorar a visibilidade do conteúdo nas buscas do Google.
Robots.txt vs meta robots vs x-robots
O que diferencia esses três comandos do robô? Robots.txt é um arquivo de texto simples, enquanto meta e x-robots são meta diretivas. Além de seus papéis fundamentais, os três têm funções distintas. Robots.txt especifica o comportamento de rastreamento para todo o site ou diretório, enquanto meta e x-robots definem o comportamento de indexação para páginas individuais (ou elementos de página).
Leitura adicional
Recursos úteis
- Wikipedia: Protocolo de exclusão de robôs
- Documentação do Google sobre Robots.txt
- Documentação do Bing (e Yahoo) em Robots.txt
- Diretivas explicadas
- Documentação do Yandex em Robots.txt
Empacotando
Esperamos que você tenha entendido completamente a importância do arquivo robot.txt e suas contribuições para sua prática geral de SEO e lucratividade do site. Se você ainda está lutando para obter receita com seu site, não precisará de codificação para começar a ganhar com os anúncios do Adsterra. Coloque um código de anúncio em seu site HTML, WordPress ou Blogger e comece a lucrar hoje mesmo!