
Que tecnologia os mecanismos de pesquisa usam para rastrear sites?
Publicados: 2023-03-02
Se você já se perguntou qual tecnologia os mecanismos de pesquisa usam para rastrear sites, prepare-se para finalmente ter suas perguntas respondidas. Você saberá o que é um rastreador da Web, os vários tipos diferentes de rastreadores da Web usados pelos principais mecanismos de pesquisa e o que é o processo de indexação de pesquisa. Você também aprenderá como tudo isso afetará os resultados do mecanismo de pesquisa e como os proprietários de sites podem dizer aos rastreadores da Web do mecanismo de pesquisa para indexar o conteúdo de acordo com seus desejos. Vamos descobrir mais sobre essa tecnologia que os mecanismos de pesquisa usam para fornecer bilhões de resultados de pesquisa relevantes com precisão para pessoas que procuram informações na rede mundial de computadores.
O que são rastreadores da Web ou robôs de mecanismos de pesquisa?
Os robôs rastreadores da Web, também conhecidos como spiders, são programas automatizados que empresas como Google e Microsoft usam para ensinar a seus mecanismos de pesquisa o que está presente em todas as páginas da Web acessíveis de todos os sites que podem encontrar na Internet. É somente aprendendo quais informações estão incluídas em uma página da Web que esses mecanismos de pesquisa podem recuperar essas informações com precisão quando um de seus usuários digita uma consulta de pesquisa solicitando saber sobre um tópico específico.
Os tipos de robôs rastreadores da Web
Todo mecanismo de pesquisa tem seus rastreadores da web. Aqui estão alguns dos mais amplamente utilizados.
GoogleBot
O Google é o mecanismo de pesquisa mais popular do planeta e usa duas versões de rastreadores da Web para indexar centenas de bilhões de páginas da Web. O GoogleBot Desktop examinará páginas que imitam o comportamento de alguém usando um computador desktop para navegar na Internet, enquanto o GoogleBot Mobile fará o mesmo para usuários de smartphones.
O GoogleBot é um dos tipos mais eficazes de bots de pesquisa já feitos e pode rastrear e indexar páginas da web rapidamente. No entanto, ele tem alguns problemas para rastrear estruturas de sites muito complexas. Além disso, muitas vezes, o GoogleBot pode levar muitos dias ou semanas para rastrear uma página da Web recém-publicada, o que significa que ela não aparecerá nos resultados relevantes por um tempo.
BingbotName
O Bingbot é a resposta da Microsoft ao Google em seu próprio mecanismo de busca Bing. Isso funciona de maneira semelhante ao rastreador da Web do Google e inclui até uma ferramenta de busca que indica como o bot rastreará uma página, permitindo que você veja se há algum problema aqui.
Slurp Bot
O Slurp Bot é o rastreador da Web usado pelo Yahoo, embora eles também usem o Bingbot para fornecer os resultados do mecanismo de pesquisa. O proprietário do site deve permitir o acesso do Slurp Bot se desejar que o conteúdo da página da Web apareça nos resultados de pesquisa do Yahoo Mobile. Além disso, o Slurp Bot também pode acessar os sites parceiros do Yahoo para adicionar conteúdo aos sites Yahoo News, Yahoo Sports e Yahoo Finance.
DuckDuckBot
Este é o rastreador da web usado pelo DuckDuckGo, um mecanismo de pesquisa conhecido por fornecer um nível inigualável de privacidade para seus usuários, não rastreando suas atividades como muitos populares fazem. Eles fornecem resultados de pesquisa obtidos de seu DuckDuckBot, bem como sites de crowdsourcing como a Wikipedia e outros mecanismos de pesquisa.
Baiduspider e bot Yandex
Estes são os robôs rastreadores usados pelos mecanismos de busca Baidu da China e Yandex da Rússia, respectivamente. A Baidu tem mais de 80% de participação no mercado de mecanismos de busca na China continental.
Como funciona o rastreamento da Web, a indexação de pesquisa e a classificação do mecanismo de pesquisa
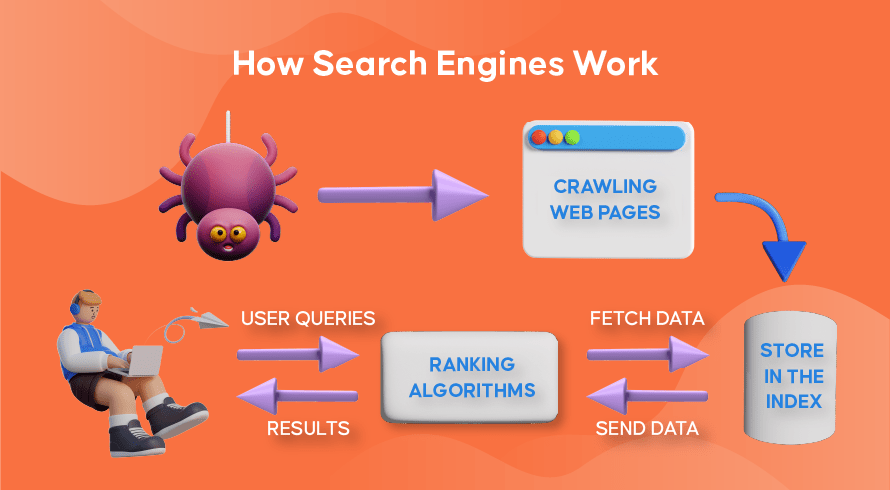
Agora vamos explorar como a maioria dos mecanismos de pesquisa usa rastreadores da Web para localizar, armazenar, organizar e recuperar informações contidas em sites.
Como funcionam os rastreadores da Web
O processo de encontrar conteúdo novo e atualizado em sites é chamado de 'rastreamento da web', daí o nome dos programas de software que executam essa função. Os bots primeiro começarão a rastrear algumas páginas da web, encontrarão seu conteúdo e, em seguida, seguirão os hiperlinks incluídos nessa página da web para descobrir novos URLs, levando a ainda mais conteúdo.
Como funciona a indexação do mecanismo de pesquisa
Depois que os bots descobrem conteúdo novo ou atualizado por meio do rastreamento da Web, tudo o que encontram é adicionado a um enorme banco de dados chamado 'índice do mecanismo de pesquisa'. É como uma biblioteca onde os livros são como páginas da web, organizados para fácil recuperação posterior. Contendo em cada livro a maior parte do texto contido em uma página da web que podemos ver (excluindo palavras como 'a', 'an' e 'the'), bem como os metadados que apenas os rastreadores veem. Os metadados são o que os mecanismos de pesquisa usam para entender o conteúdo de uma página da web. O meta título e a meta descrição são exemplos de metadados.
Como funciona a classificação de pesquisa
Sempre que um usuário digita uma consulta de pesquisa, o respectivo mecanismo de pesquisa verifica seu índice, encontra as informações mais relevantes que correspondem a essa solicitação, organiza a lista de links da Web que contêm o conteúdo relevante e apresenta isso ao usuário no mecanismo de pesquisa páginas de resultados (SERPs).
Essa organização das SERPs é chamada de 'ranking de pesquisa' e é realizada por um algoritmo de pesquisa que leva em consideração os dados coletados, incluindo metadados, a credibilidade do site (autoridade), além de palavras-chave e links. Sites que são considerados fontes muito confiáveis e contêm conteúdo altamente relevante que será útil para os usuários terão uma classificação alta, recebendo os melhores resultados nas SERPs. É por isso que todo proprietário de site tem estratégias para classificar seu site nas SERPs.
Como Search Engine Optimization (SEO) entra na imagem
Os proprietários de sites podem otimizar o conteúdo de suas páginas de forma que os mecanismos de pesquisa os reconheçam mais facilmente como relevantes e úteis para seus usuários. Isso levará essas páginas ao topo das SERPs, trazendo mais tráfego orgânico para o site. Incluir estrategicamente palavras-chave relevantes na cópia da página, criação de links e o uso de imagens e vídeos originais são algumas das maneiras pelas quais as técnicas de SEO podem ser utilizadas.

Além disso, os sites também podem usar várias ferramentas como o SEMrush para encontrar e corrigir vários problemas em suas páginas, como links quebrados, o que melhorará ainda mais sua classificação aos olhos dos mecanismos de pesquisa.
Dizendo aos mecanismos de pesquisa como rastrear seu site

Às vezes, você descobrirá que os rastreadores da Web não executaram adequadamente sua função, fazendo com que páginas importantes do seu site não apareçam no índice. Isso significa que consultas de pesquisa relevantes não serão apresentadas com seu conteúdo, dificultando que clientes em potencial encontrem o caminho para suas páginas. Felizmente, existem maneiras de se comunicar com os mecanismos de pesquisa, permitindo um pouco de controle sobre o que é indexado e o que é ignorado.
O arquivo robots.txt armazenado no diretório raiz do seu site é o que informa aos rastreadores da Web quais páginas você deseja rastrear, quais ignorar e como a arquitetura do seu site é organizada. Você pode querer impedir que páginas específicas sejam indexadas se estiverem sendo usadas para testes ou promoções especiais e URLs duplicados usados em comércio eletrônico.
O GoogleBot, por exemplo, continuará rastreando um site na íntegra se não houver nenhum arquivo robots.txt presente. Ao detectar seu arquivo robots.txt, o GoogleBot seguirá suas instruções durante o rastreamento. Se tiver problemas para detectar o arquivo ou encontrar um erro, pode não rastrear seu site. Você deve usar o arquivo robots.txt corretamente, organizar a arquitetura do seu site e usar as práticas recomendadas de SEO na página para evitar problemas de rastreamento. Você pode realizar uma auditoria de site para analisar e identificar quaisquer problemas que estejam afetando seu site.
Precisa de serviços de SEO para seu site?
Se você está procurando um provedor de serviços que entenda como os rastreadores da Web e a indexação de pesquisa funcionam para melhorar as classificações do seu site, a Inquivix é o parceiro de SEO que você está procurando. Fornecemos um conjunto abrangente de serviços de SEO na página, desde a criação de conteúdo até a otimização da arquitetura do site e análise de desempenho do site para continuar melhorando a qualidade da experiência do seu site. Para saber mais, visite Inquivix On-Page SEO Services hoje mesmo!
perguntas frequentes
Os mecanismos de pesquisa usam programas chamados 'web crawlers', também conhecidos como 'spiders' ou 'bots' para descobrir conteúdo novo e atualizado nas páginas de um site. Ele seguirá os links incluídos na página para encontrar mais páginas. O conteúdo encontrado em uma página é salvo em um índice que é usado para recuperar informações para resultados de pesquisa quando um usuário as solicita.
GoogleBot Desktop e GoogleBot Mobile são os rastreadores da web mais populares na maioria dos países, seguidos por Bingbot, Slurp Bot e DuckDuckBot. O Baiduspider é usado principalmente na China, enquanto o Yandex Bot é usado na Rússia.