
Tehnici avansate pentru îmbunătățirea randamentului LLM
Publicat: 2024-04-02În lumea rapidă a tehnologiei, modelele de limbaj mari (LLM) au devenit actori cheie în modul în care interacționăm cu informațiile digitale. Aceste instrumente puternice pot scrie articole, pot răspunde la întrebări și chiar pot ține conversații, dar nu sunt lipsite de provocări. Pe măsură ce cerem mai mult de la aceste modele, ne confruntăm cu obstacole, mai ales când vine vorba de a le face să funcționeze mai rapid și mai eficient. Acest blog este despre abordarea directă a acestor obstacole.
Ne aprofundăm în câteva strategii inteligente concepute pentru a crește viteza cu care funcționează aceste modele, fără a pierde calitatea producției lor. Imaginați-vă că încercați să îmbunătățiți viteza unei mașini de curse, asigurându-vă în același timp că poate naviga fără probleme în virajele strâmte - asta ne propunem cu modelele de limbaj mari. Vom analiza metode precum Continuous Batching, care ajută la procesarea informațiilor mai ușor, și abordări inovatoare, cum ar fi Paged și Flash Attention, care fac ca LLM să fie mai atenți și mai rapid în raționamentul lor digital.
Deci, dacă ești curios să depășești limitele a ceea ce pot face acești giganți AI, ești în locul potrivit. Să explorăm împreună modul în care aceste tehnici avansate modelează viitorul LLM-urilor, făcându-le mai rapide și mai bune decât oricând.
Provocări în atingerea unui randament mai mare pentru LLM
Obținerea unui randament mai mare în modelele lingvistice mari (LLM) se confruntă cu mai multe provocări semnificative, fiecare acționând ca un obstacol în calea vitezei și eficienței cu care pot funcționa aceste modele. Un obstacol principal este necesarul de memorie absolut necesar pentru a procesa și stoca cantitățile mari de date cu care lucrează aceste modele. Pe măsură ce LLM-urile cresc în complexitate și dimensiune, cererea de resurse de calcul se intensifică, ceea ce face dificilă menținerea, ca să nu mai vorbim de îmbunătățirea vitezei de procesare.
O altă provocare majoră este natura auto-regresivă a LLM-urilor, în special în modelele utilizate pentru generarea de text. Aceasta înseamnă că rezultatul la fiecare pas este dependent de cele anterioare, creând o cerință de procesare secvențială care limitează în mod inerent cât de repede pot fi executate sarcinile. Această dependență secvențială duce adesea la un blocaj, deoarece fiecare pas trebuie să aștepte finalizarea predecesorului său înainte de a putea continua, împiedicând eforturile de a obține un debit mai mare.
În plus, echilibrul dintre precizie și viteză este unul delicat. Îmbunătățirea debitului fără a compromite calitatea rezultatelor este un mers pe frânghie, care necesită soluții inovatoare care pot naviga pe peisajul complex al eficienței computaționale și al eficacității modelului.
Aceste provocări formează fundalul pe care se realizează progresele în optimizarea LLM, împingând limitele a ceea ce este posibil în domeniul procesării limbajului natural și nu numai.
Cerința de memorie
Faza de decodificare generează un singur jeton la fiecare pas de timp, dar fiecare jeton depinde de tensorii cheie și de valoare ai tuturor jetonelor anterioare (inclusiv tensorii KV ai jetonurilor de intrare calculați la pre-completare și orice tensori KV noi calculați până la pasul de timp curent) .
Prin urmare, pentru a minimiza calculele redundante de fiecare dată și pentru a evita recalcularea tuturor acestor tensori pentru toate tokenurile la fiecare pas de timp, este posibil să le memorați în memoria cache în memoria GPU. La fiecare iterație, atunci când sunt calculate elemente noi, acestea sunt pur și simplu adăugate în memoria cache care rulează pentru a fi utilizate în următoarea iterație. Acest lucru este în esență cunoscut sub numele de cache KV.
Acest lucru reduce în mare măsură calculul necesar, dar introduce o cerință de memorie împreună cu cerințe de memorie deja mai mari pentru modelele de limbaj mari, ceea ce face dificilă rularea pe GPU-uri de bază. Odată cu creșterea dimensiunii parametrilor modelului (7B la 33B) și cu o precizie mai mare (fp16 la fp32), cerințele de memorie cresc, de asemenea. Să vedem un exemplu pentru capacitatea de memorie necesară,
După cum știm, cei doi ocupanți majori ai memoriei sunt
- Greutățile proprii ale modelului în memorie, aceasta vine cu nr. de parametri precum 7B și tipul de date al fiecărui parametru, de exemplu, 7B în fp16 (2 octeți) ~= 14 GB în memorie
- Cache KV: Cache-ul utilizat pentru valoarea cheie a etapei de auto-atenție pentru a evita calculul redundant.
Dimensiunea memoriei cache KV per token în octeți = 2 * (num_layers) * (hidden_size) * precizie_în_bytes
Primul factor 2 ține cont de matrice K și V. Aceste hidden_size și dim_head pot fi obținute de pe cardul modelului sau din fișierul de configurare.
Formula de mai sus este pe token, deci pentru o secvență de intrare, va fi seq_len * size_of_kv_per_token. Deci formula de mai sus se va transforma în,
Dimensiunea totală a memoriei cache KV în octeți = (sequence_length) * 2 * (num_layers) * (hidden_size) * precision_in_bytes
De exemplu, cu LLAMA 2 în fp16, dimensiunea va fi (4096) * 2 * (32) * (4096) * 2, adică ~2 GB.
Acest lucru de mai sus este pentru o singură intrare, cu intrări multiple, aceasta crește rapid, această alocare și gestionare a memoriei în timpul zborului devine astfel un pas crucial pentru a obține o performanță optimă, dacă nu duce la lipsă de memorie și probleme de fragmentare.
Uneori, necesarul de memorie este mai mult decât capacitatea GPU-ului nostru, în acele cazuri, trebuie să analizăm paralelismul modelului, paralelismul tensorului, care nu este acoperit aici, dar puteți explora în acea direcție.
Auto-regresivitatea și funcționarea legată de memorie
După cum putem vedea, partea de generare a rezultatelor a modelelor mari de limbaj este de natură auto-regresivă. Indică pentru generarea oricărui token nou, depinde de toate tokenurile anterioare și de stările sale intermediare. Deoarece în etapa de ieșire nu toate token-urile sunt disponibile pentru a face calcule suplimentare și are un singur vector (pentru următorul token) și blocul etapei anterioare, aceasta devine ca o operație matrice-vector care subutiliza capacitatea de calcul a GPU atunci când comparativ cu faza de pre-umplere. Viteza cu care datele (greutăți, chei, valori, activări) sunt transferate pe GPU din memorie domină latența, nu cât de repede au loc de fapt calculele. Cu alte cuvinte, aceasta este o operație legată de memorie .
Soluții inovatoare pentru a depăși provocările de debit
Dozare continuă
Pasul foarte simplu pentru a reduce natura legată de memorie a etapei de decodare este să grupați intrarea și să faceți calcule pentru mai multe intrări simultan. Dar o simplă grupare constantă a dus la o performanță slabă din cauza naturii lungimii secvenței variabile care sunt generate și aici latența unui lot depinde de cea mai lungă secvență care este generată într-un lot și, de asemenea, cu o cerință de memorie în creștere, deoarece intrările multiple sunt acum procesate deodată.
Prin urmare, dotarea statică simplă este ineficientă și vine dotarea continuă. Esența sa constă în agregarea dinamică a loturilor de solicitări primite, adaptarea la ratele de sosire fluctuante și exploatarea oportunităților de procesare paralelă ori de câte ori este fezabil. Acest lucru optimizează, de asemenea, utilizarea memoriei prin gruparea secvențelor de lungimi similare împreună în fiecare lot, ceea ce minimizează cantitatea de umplutură necesară pentru secvențe mai scurte și evită irosirea resurselor de calcul cu umplutură excesivă.

Acesta ajustează adaptativ dimensiunea lotului pe baza unor factori precum capacitatea curentă a memoriei, resursele de calcul și lungimile secvenței de intrare. Acest lucru asigură că modelul funcționează optim în condiții variate, fără a depăși constrângerile de memorie. Acest lucru în ajutor cu atenția paginată (explicat mai jos) ajută la reducerea latenței și la creșterea debitului.
Citiți în continuare: Cum lotizarea continuă permite un debit de 23x în inferența LLM, reducând în același timp latența p50
Atenție paginată
Pe măsură ce facem loturi pentru a îmbunătăți debitul, aceasta are și prețul creșterii cerințelor de memorie cache KV, deoarece acum procesăm mai multe intrări simultan. Aceste secvențe pot depăși capacitatea de memorie a resurselor de calcul disponibile, ceea ce face imposibilă procesarea lor în întregime.
Se observă, de asemenea, că alocarea naivă a memoriei cache-ului KV are ca rezultat o mulțime de fragmentare a memoriei, la fel ca în cazul în care observăm în sistemele informatice din cauza alocării inegale a memoriei. vLLM a introdus Paged Attention, care este o tehnică de gestionare a memoriei inspirată din conceptele sistemului de operare de paginare și memorie virtuală pentru a gestiona eficient cerința tot mai mare de cache KV.
Atenția paginată abordează constrângerile de memorie prin împărțirea mecanismului de atenție în pagini sau segmente mai mici, fiecare acoperind un subset al secvenței de intrare. În loc să calculeze scorurile de atenție pentru întreaga secvență de intrare simultan, modelul se concentrează pe o pagină odată, procesând-o secvenţial.
În timpul inferenței sau antrenamentului, modelul iterează prin fiecare pagină a secvenței de intrare, calculând scorurile de atenție și generând rezultate în consecință. Odată ce o pagină este procesată, rezultatele acesteia sunt stocate, iar modelul trece la pagina următoare.
Prin împărțirea mecanismului de atenție în pagini, Paged Attention permite modelului de limbă mare să gestioneze secvențe de intrare de lungime arbitrară fără a depăși constrângerile de memorie. Reduce efectiv amprenta de memorie necesară procesării secvențelor lungi, făcând posibilă lucrarea cu documente și loturi mari.
Citiți mai departe: Servire rapidă LLM cu vLLM și PagedAttention
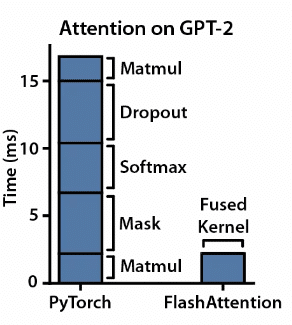
Atenție flash
Deoarece mecanismul de atenție este crucial pentru modelele de transformare pe care se bazează modelele mari de limbaj, ajută modelul să se concentreze asupra părților relevante ale textului de intrare atunci când face predicții. Cu toate acestea, pe măsură ce modelele bazate pe transformator devin mai mari și mai complexe, mecanismul de auto-atenție devine din ce în ce mai lent și consumator de memorie, ceea ce duce la o problemă de blocaj de memorie, așa cum am menționat mai devreme. Flash Attention este o altă tehnică de optimizare care urmărește să atenueze această problemă prin optimizarea operațiunilor de atenție, permițând antrenament și inferență mai rapid.
Caracteristici cheie ale atenției flash:
Kernel Fusion: Este important nu doar să maximizăm utilizarea de calcul a GPU-ului, ci și să o facem pe măsura posibilității operațiunilor eficiente. Flash Attention combină mai mulți pași de calcul într-o singură operație, reducând nevoia de transferuri repetitive de date. Această abordare simplificată simplifică procesul de implementare și îmbunătățește eficiența de calcul.
Tiling: Flash Attention împarte datele încărcate în blocuri mai mici, ajutând procesarea paralelă. Această strategie optimizează utilizarea memoriei, permițând soluții scalabile pentru modele cu dimensiuni de intrare mai mari.
(Nucleul CUDA fuzionat care ilustrează modul în care placarea și fuziunea reduce timpul necesar pentru calcul, Sursa imaginii: FlashAttention: Atenție exactă rapidă și eficientă în memorie cu IO-Awareness)
Optimizarea memoriei: Flash Attention încarcă parametrii doar pentru ultimele câteva jetoane, reutilizand activările de la jetoane calculate recent. Această abordare cu fereastră glisantă reduce numărul de solicitări IO pentru a încărca greutăți și maximizează debitul memoriei flash.
Transferuri reduse de date: Flash Attention minimizează transferurile de date dus-întors între tipurile de memorie, cum ar fi memoria cu lățime de bandă mare (HBM) și SRAM (memorie statică cu acces aleatoriu). Încărcând toate datele (interogări, chei și valori) doar o singură dată, se reduce costul general al transferurilor de date repetitive.
Studiu de caz – Optimizarea inferenței cu decodare speculativă
O altă metodă folosită pentru a accelera generarea de text în modelul de limbaj autoregresiv este decodificarea speculativă. Obiectivul principal al decodării speculative este acela de a accelera generarea de text, păstrând în același timp calitatea textului generat la un nivel comparabil cu cel al distribuției țintă.
Decodificarea speculativă introduce un model mic/schiță care prezice jetoanele ulterioare din secvență, care sunt apoi acceptate/respinse de modelul principal pe baza unor criterii predefinite. Integrarea unui model de schiță mai mic cu modelul țintă crește semnificativ viteza de generare a textului, acest lucru se datorează naturii cerinței de memorie. Deoarece proiectul de model este mic, necesită mai puțin nu. a greutăților neuronilor de încărcat și nr. de calcul este, de asemenea, mai mic acum în comparație cu modelul principal, acest lucru reduce latența și accelerează procesul de generare a ieșirii. Modelul principal evaluează apoi rezultatele care sunt generate și se asigură că se încadrează în distribuția țintă a următorului simbol probabil.
În esență, decodificarea speculativă simplifică procesul de generare a textului prin folosirea unui model de schiță mai mic și mai rapid pentru a prezice simbolurile ulterioare, accelerând astfel viteza generală de generare a textului, menținând în același timp calitatea conținutului generat aproape de distribuția țintă.
Este foarte important ca tokenurile generate de modelele mai mici să nu fie întotdeauna respinse în mod constant, acest caz duce la scăderea performanței în loc de îmbunătățire. Prin experimente și prin natura cazurilor de utilizare putem selecta un model mai mic/introduce decodificarea speculativă în procesul de inferență.
Concluzie
Călătoria prin tehnicile avansate de îmbunătățire a ratei modelului de limbă mare (LLM) luminează o cale înainte în domeniul procesării limbajului natural, prezentând nu doar provocările, ci și soluțiile inovatoare care le pot face față direct. Aceste tehnici, de la Continuous Batching la Paged and Flash Attention, și abordarea intrigantă a Speculative Decoding, sunt mai mult decât doar îmbunătățiri incrementale. Ele reprezintă progrese semnificative în capacitatea noastră de a face modele lingvistice mari mai rapide, mai eficiente și, în cele din urmă, mai accesibile pentru o gamă largă de aplicații.
Semnificația acestor progrese nu poate fi exagerată. În optimizarea debitului LLM și îmbunătățirea performanței, nu doar modificăm motoarele acestor modele puternice; redefinim ceea ce este posibil în ceea ce privește viteza și eficiența procesării. Acest lucru, la rândul său, deschide noi orizonturi pentru aplicarea modelului lingvistic mare, de la servicii de traducere a limbii în timp real, care pot funcționa cu viteza conversației, până la instrumente de analiză avansate capabile să proceseze seturi de date vaste cu o viteză fără precedent.
Mai mult, aceste tehnici subliniază importanța unei abordări echilibrate a optimizării modelelor de limbaj mari – una care ia în considerare cu atenție interacțiunea dintre viteză, acuratețe și resursele de calcul. Pe măsură ce depășim limitele capabilităților LLM, menținerea acestui echilibru va fi crucială pentru a ne asigura că aceste modele pot continua să servească drept instrumente versatile și de încredere într-o multitudine de industrii.
Tehnicile avansate pentru îmbunătățirea volumului mare de model de limbaj sunt mai mult decât realizări tehnice; sunt repere în evoluția continuă a inteligenței artificiale. Ei promit că vor face LLM-urile mai adaptabile, mai eficiente și mai puternice, deschizând calea pentru inovațiile viitoare care vor continua să transforme peisajul nostru digital.
Citiți mai multe despre Arhitectura GPU pentru optimizarea inferenței modelului de limbă mare în postarea noastră recentă pe blog