
Evaluarea instrumentelor Web Scraping: Ce trebuie să știe întreprinderile
Publicat: 2024-05-15Web scraping prin instrumente automate de web scraping este esențială pentru organizațiile care doresc să utilizeze big data. Permite eliminarea automată a informațiilor relevante din diverse surse web, ceea ce este esențial pentru analiza bazată pe date.
Extragând tendințele actuale ale pieței, preferințele consumatorilor și perspectivele competitive, companiile pot:
- Faceți alegeri strategice informate
- Adaptați produsele la nevoile clienților
- Optimizați prețurile pentru competitivitatea pe piață
- Creșteți eficiența operațională
În plus, atunci când sunt îmbinate cu instrumente de analiză, datele răzuite stau la baza modelelor predictive, îmbogățind procesele de luare a deciziilor. Această inteligență competitivă propulsează întreprinderile să anticipeze schimbările pieței și să acționeze proactiv, menținând un avantaj critic în sectoarele lor respective.
11 caracteristici cheie ale instrumentelor automate de scraping web pe care întreprinderile ar trebui să le caute
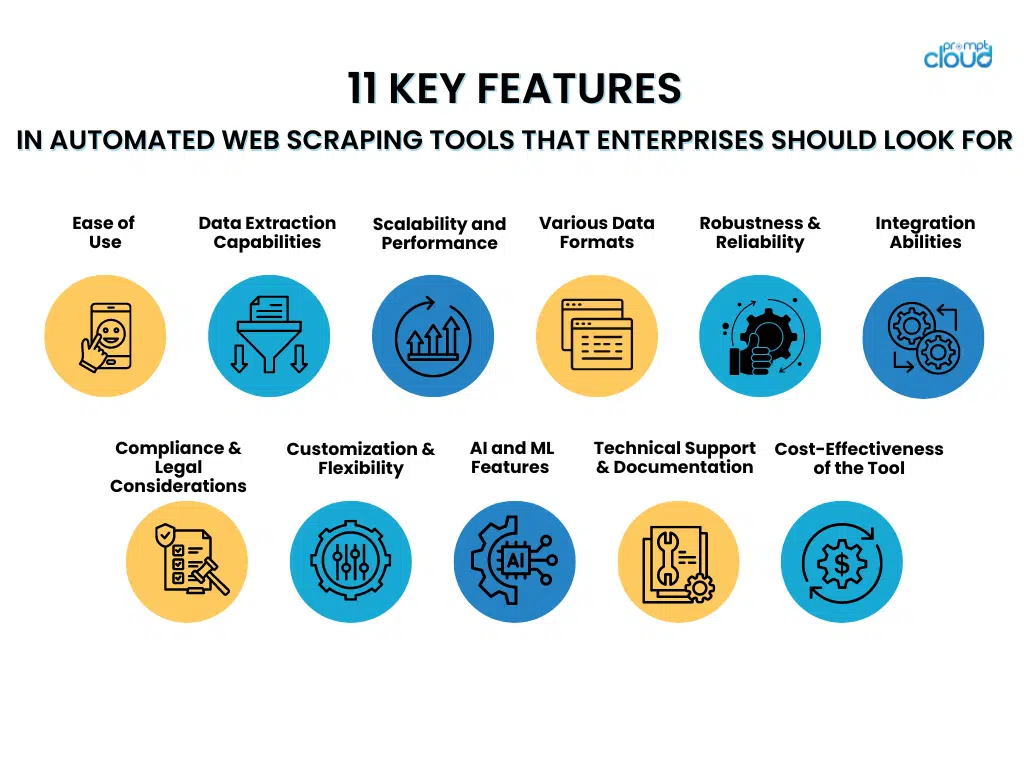
- Ușurință în utilizare
Atunci când aleg instrumente automate de scraping web, companiile ar trebui să acorde prioritate celor care au interfețe ușor de utilizat și pași de configurare fără efort. Instrumentele cu interfețe intuitive permit personalului să le folosească eficient, fără o pregătire extinsă, permițând mai multă concentrare pe recuperarea datelor în loc să stăpânească sisteme complexe.
Pe de altă parte, metodele de configurare necomplicate facilitează implementarea promptă a acestor instrumente, minimizând întârzierile și grăbind călătoria către informații valoroase. Caracteristicile care contribuie la ușurința în utilizare includ:
- Meniuri de navigare clare și directe
- Funcționalități de glisare și plasare pentru proiectarea fluxului de lucru
- Șabloane pre-construite pentru sarcini comune de răzuire
- Vrăjitorii pas cu pas care ghidează configurația inițială
- Documentație cuprinzătoare și tutoriale pentru ușurința învățării
Un instrument ușor de utilizat maximizează eficiența angajaților și ajută la menținerea unui nivel ridicat de productivitate.
- Capabilitati de extragere a datelor
Sursa imaginii: Ce este Extragerea datelor? Iată ce trebuie să știți
Atunci când evaluează instrumentele automate de scraping web, întreprinderile ar trebui să acorde prioritate funcțiilor avansate de analiză și transformare a datelor, cum ar fi:
- Analiza personalizată a datelor : abilitatea de a personaliza analizatorii pentru a interpreta cu exactitate structurile complexe de date, inclusiv conținutul imbricat și dinamic.
- Conversie tip de date : instrumente care convertesc automat datele extrase în formate utilizabile (de exemplu, date, numere, șiruri) pentru o procesare mai eficientă a datelor.
- Suport pentru expresii regulate : includerea capacităților regex pentru potrivirea sofisticată a modelelor, permițând extragerea precisă a datelor.
- Transformare condiționată : Abilitatea de a aplica logica condiționată datelor extrase, permițând transformarea pe baza unor criterii sau modele de date specifice.
- Curățarea datelor : Funcții care curăță și standardizează datele în faza post-extracție pentru a asigura calitatea și coerența datelor.
- Integrare API : Facilități pentru integrarea perfectă cu API-urile pentru a procesa și analiza în continuare datele extrase, îmbunătățind capacitățile de luare a deciziilor.
Fiecare caracteristică contribuie la un proces de extragere a datelor mai robust și mai precis, esențial pentru eforturile de web scraping la nivel de întreprindere.
- Scalabilitate și performanță
Atunci când evaluează instrumentele automate de scraping web, întreprinderile ar trebui să acorde prioritate scalabilității și atributelor de performanță care sprijină procesarea eficientă a seturi de date vaste.
Un instrument ideal poate gestiona cu pricepere o creștere semnificativă a volumului de muncă fără a compromite viteza sau precizia. Întreprinderile trebuie să caute caracteristici precum:
- Capacități multi-threading care permit procesarea concomitentă a datelor
- Gestionare eficientă a memoriei pentru a gestiona sarcini de scraping pe scară largă
- Alocarea dinamică a resurselor pe baza cerințelor în timp real
- Infrastructură robustă care se poate scala orizontal sau vertical
- Mecanisme avansate de stocare în cache pentru a accelera recuperarea datelor
Capacitatea instrumentului de a menține performanța sub sarcină asigură extragerea fiabilă a datelor, chiar și în perioadele de vârf sau la extinderea operațiunilor.
- Suport pentru diferite formate de date
Sursa imaginii: Ce este Data Scraping? Definiție și cum se utilizează
Un instrument automat de scraping web trebuie să gestioneze cu competență diverse formate de date. Întreprinderile lucrează adesea cu diferite tipuri de date, iar flexibilitatea în extracția datelor este esențială:
- JSON: Un format ușor de schimb de date, care este ușor de citit și scris de către oameni și ușor de analizat și generat de mașini.
- CSV: formatul de valori separate prin virgulă este un format de fișier simplu și comun, utilizat pentru datele tabelare. Majoritatea instrumentelor de răzuire ar trebui să ofere o opțiune de export CSV.
- XML: Extensible Markup Language, un format mai complex care include metadate și poate fi utilizat într-o gamă largă de industrii.
Abilitatea de a extrage și exporta date în aceste formate asigură compatibilitatea cu diferite instrumente și sisteme de analiză a datelor, oferind o soluție versatilă pentru cerințele întreprinderii.
- Robustitate și fiabilitate
Atunci când întreprinderile aleg instrumente automate de scraping web, ele trebuie să acorde prioritate robusteței și fiabilității. Caracteristicile cheie de luat în considerare includ:
- Gestionarea completă a erorilor : un instrument superior ar trebui să aibă capacitatea de a detecta și rectifica erorile automat. Ar trebui să înregistreze problemele și, atunci când este posibil, să reîncerce cererile eșuate fără intervenție manuală.
- Strategii de minimizare a timpului de nefuncționare : instrumentul ar trebui să includă mecanisme de failover, cum ar fi servere de rezervă sau surse alternative de date, pentru a menține operațiunile atunci când sursele primare eșuează.
- Sisteme de monitorizare continuă : monitorizarea în timp real asigură identificarea și soluționarea imediată a oricărei perioade de nefuncționare, minimizând lipsurile de date.
- Întreținere predictivă : Utilizarea învățării automate pentru a anticipa potențialele puncte de defecțiune poate preveni preventiv timpii de nefuncționare, făcând sistemul mai fiabil.
Investiția în instrumente care subliniază aceste aspecte de robustețe și fiabilitate poate reduce semnificativ riscurile operaționale asociate cu web scraping.

- Abilitati de integrare
Atunci când evaluează instrumentele automate de scraping web, întreprinderile trebuie să își garanteze capacitatea de a se integra fluid cu conductele de date actuale. Acest lucru este esențial pentru a menține continuitatea fluxului de date și pentru a optimiza procesul. Instrumentul ar trebui să:
- Oferiți API-uri sau conectori compatibile cu bazele de date și platformele de analiză existente.
- Suportă diferite formate de date pentru import/export fără întreruperi, asigurând întreruperi minime.
- Furnizați funcții de automatizare care pot fi declanșate de evenimente din conducta de date.
- Facilitați scalarea ușoară fără reconfigurare extinsă pe măsură ce nevoile de date evoluează.
- Conformitate și considerații legale
Atunci când integrați un instrument automat de scraping web în operațiunile întreprinderii, este esențial să vă asigurați că instrumentul respectă cadrele legale. Caracteristicile de luat în considerare includ:
- Respect pentru Robots.txt : instrumentul ar trebui să recunoască și să respecte automat fișierul robots.txt al site-ului web, care descrie permisiunile de scraping.
- Limitarea ratei : Pentru a evita o încărcare perturbatoare pe serverele gazdă, instrumentele trebuie să includă limitarea ratei ajustabile pentru a controla frecvența solicitărilor.
- Conformitatea confidențialității datelor : instrumentul ar trebui să fie construit în conformitate cu reglementările globale de protecție a datelor, cum ar fi GDPR sau CCPA, asigurându-se că datele cu caracter personal sunt gestionate în mod legal.
- Conștientizarea proprietății intelectuale : instrumentul ar trebui să aibă mecanisme pentru a evita încălcarea drepturilor de autor la eliminarea conținutului protejat prin drepturi de autor.
- Transparență agent utilizator : capacitatea instrumentului de scraping de a se identifica în mod precis și transparent pentru a viza site-urile web, reducând riscul practicilor înșelătoare.
Includerea acestor funcții poate ajuta la atenuarea riscurilor legale și la facilitarea unei strategii de scraping responsabilă care respectă atât conținutul proprietar, cât și confidențialitatea utilizatorilor.
- Personalizare și flexibilitate
Pentru a-și îndeplini în mod eficient cerințele unice de culegere a datelor, întreprinderile trebuie să ia în considerare capacitățile de personalizare și flexibilitatea unui instrument de scraping web automat ca factori cruciali în timpul evaluării. Un instrument superior ar trebui:
- Oferiți o interfață ușor de utilizat pentru utilizatorii non-tehnici pentru a personaliza parametrii de extracție a datelor.
- Oferiți opțiuni avansate pentru ca dezvoltatorii să scrie scripturi personalizate sau să utilizeze API-uri.
- Permite integrarea ușoară cu sistemele și fluxurile de lucru existente în cadrul întreprinderii.
- Activați programarea activităților de scraping pentru a rula în timpul orelor de vârf, reducând sarcina pe servere și evitând potențiala limitare a site-ului.
- Adaptați-vă la diferite structuri de site-uri web și tipuri de date, asigurându-vă că poate fi gestionată o gamă largă de cazuri de utilizare.
Personalizarea și flexibilitatea asigură că instrumentul poate evolua odată cu nevoile în schimbare ale întreprinderii, maximizând valoarea și eficacitatea eforturilor de web scraping.
- AI avansate și funcții de învățare automată
Atunci când selectează un instrument automat de scraping web, întreprinderile trebuie să ia în considerare integrarea AI avansată și a învățării automate pentru îmbunătățirea acurateței datelor. Aceste caracteristici includ:
- Înțelegerea contextuală : aplicarea procesării limbajului natural (NLP) permite instrumentului să discerne contextul, reducând erorile în conținutul răzuit.
- Recunoașterea modelelor : algoritmii de învățare automată identifică modelele de date, facilitând extragerea precisă a informațiilor.
- Învățare adaptivă : instrumentul învață din sarcinile anterioare de scraping pentru a optimiza procesele de colectare a datelor pentru sarcinile viitoare.
- Detectarea anomaliilor : sistemele AI pot detecta și corecta valori aberante sau anomalii ale datelor răzuite, asigurând fiabilitatea.
- Validarea datelor : utilizarea AI pentru verificarea încrucișată a datelor răzuite cu mai multe surse îmbunătățește validitatea informațiilor.
Prin valorificarea acestor capacități, întreprinderile pot diminua substanțial inexactitățile din seturile lor de date, ducând la luarea deciziilor mai informate.
- Suport tehnic și documentație
Este recomandabil ca companiile să acorde preferință instrumentelor automate de scraping web care vin cu asistență tehnică extinsă și documentație amănunțită. Acest lucru este crucial pentru:
- Minimizarea timpului de nefuncționare : Asistența rapidă și profesională asigură rezolvarea rapidă a oricăror probleme.
- Ușurință în utilizare : documentația bine organizată ajută la instruirea utilizatorilor și la stăpânirea instrumentelor.
- Depanare : ghidurile și resursele accesibile permit utilizatorilor să depaneze în mod independent problemele comune.
- Actualizări și actualizări : Asistența consecventă și documentația clară sunt vitale pentru a naviga în mod eficient prin actualizările de sistem și noile funcții.
Alegerea unui instrument cu asistență tehnică solidă și documentație clară este esențială pentru o funcționare fără întreruperi și pentru rezolvarea eficientă a problemelor.
- Evaluarea cost-eficienței instrumentului
Întreprinderile ar trebui să țină cont atât de cheltuielile inițiale, cât și de posibilul ROI atunci când evaluează software-ul de automatizare pentru web scraping. Factorii cheie de preț includ:
- Taxe de licență sau costuri de abonament
- Cheltuieli de întreținere și suport
- Economii potențiale de costuri din automatizare
- Scalabilitate și adaptabilitate la nevoile viitoare
O evaluare aprofundată a rentabilității investiției (ROI) pentru un instrument ar trebui să țină cont de potențialul acestuia de a reduce munca manuală, de a îmbunătăți precizia datelor și de a accelera procesul de obținere a informațiilor. În plus, întreprinderile ar trebui să evalueze avantaje durabile, cum ar fi competitivitatea îmbunătățită rezultată din alegerile bazate pe date. Compararea acestor măsurători cu cheltuielile instrumentului va oferi o imagine distinctă asupra eficienței costurilor acestuia.
Concluzie
Atunci când aleg un instrument automat de scraping web, companiile ar trebui să ia în considerare cu meticulozitate fiecare caracteristică în raport cu cerințele lor specifice. Sublinierea unor aspecte precum scalabilitatea, precizia datelor, viteza, legalitatea și eficiența costurilor este esențială. Instrumentul ideal va sprijini obiectivele companiei și se va integra fără probleme cu sistemele actuale. În cele din urmă, o alegere luminată rezultă dintr-o examinare amănunțită a caracteristicilor instrumentului și o înțelegere solidă a nevoilor viitoare de date ale companiei.