
Extragerea datelor de pe site-uri web dinamice: provocări și soluții
Publicat: 2023-11-23Internetul găzduiește un rezervor extins și în continuă expansiune de date, oferind o valoare extraordinară întreprinderilor, cercetătorilor și persoanelor care caută informații, luare a deciziilor în cunoștință de cauză sau soluții inovatoare. Cu toate acestea, o parte substanțială a acestor informații neprețuite se află în site-uri web dinamice.
Spre deosebire de site-urile web statice convenționale, site-urile web dinamice generează în mod dinamic conținut ca răspuns la interacțiunile utilizatorilor sau evenimente externe. Aceste site-uri folosesc tehnologii precum JavaScript pentru a manipula conținutul paginilor web, reprezentând o provocare formidabilă pentru tehnicile tradiționale de web scraping pentru a extrage în mod eficient datele.
În acest articol, ne vom aprofunda în domeniul scrapingului dinamic al paginilor web. Vom examina provocările tipice legate de acest proces și vom prezenta strategii eficiente și cele mai bune practici pentru depășirea acestor obstacole.
Înțelegerea site-urilor web dinamice
Înainte de a pătrunde în complexitățile scraping-ului dinamic al paginilor web, este esențial să stabilim o înțelegere clară a ceea ce caracterizează un site web dinamic. Spre deosebire de omologii statici care oferă conținut uniform la nivel universal, site-urile web dinamice generează în mod dinamic conținut pe baza diferiților parametri, cum ar fi preferințele utilizatorilor, interogări de căutare sau date în timp real.
Site-urile web dinamice folosesc adesea cadre JavaScript sofisticate pentru a modifica și actualiza în mod dinamic conținutul paginii web din partea clientului. Deși această abordare îmbunătățește semnificativ interactivitatea utilizatorului, introduce provocări atunci când se încearcă extragerea programatică a datelor.
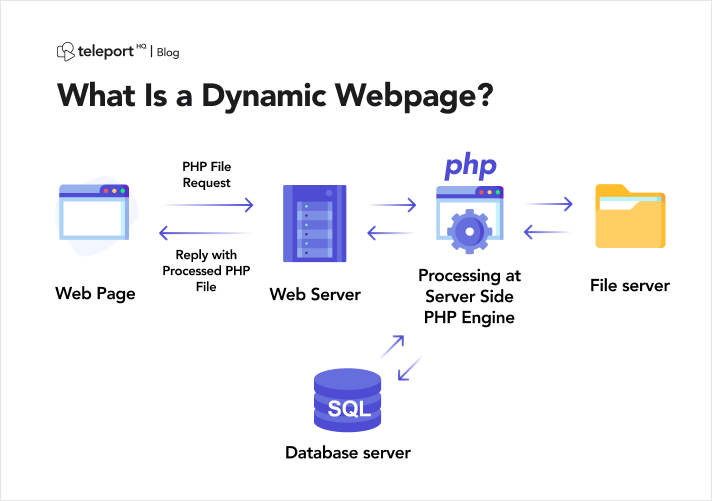
Sursa imagine: https://teleporthq.io/
Provocări comune în răzuirea dinamică a paginilor web
Scrapingul dinamic al paginilor web pune mai multe provocări din cauza naturii dinamice a conținutului. Unele dintre cele mai frecvente provocări includ:
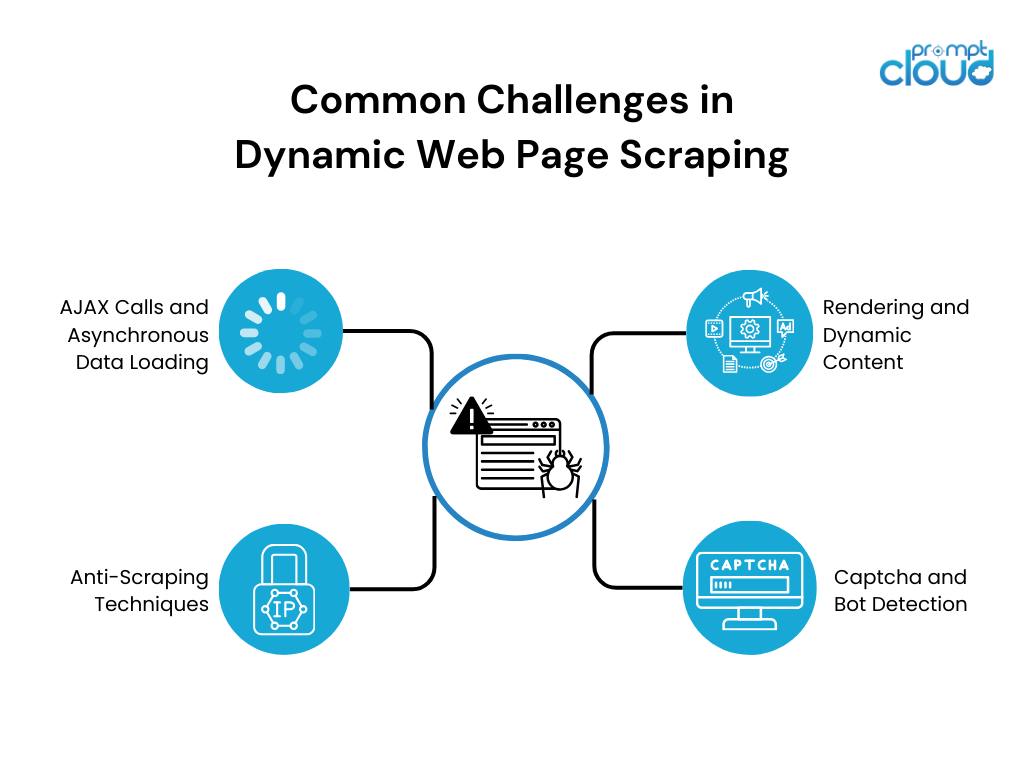
- Redare și conținut dinamic: site-urile web dinamice se bazează în mare măsură pe JavaScript pentru a reda conținutul în mod dinamic. Instrumentele tradiționale de web scraping se luptă să interacționeze cu conținutul bazat pe JavaScript, ceea ce duce la extragerea datelor incomplete sau incorecte.
- Apeluri AJAX și încărcare asincronă a datelor: multe site-uri web dinamice folosesc apeluri JavaScript și XML asincrone (AJAX) pentru a prelua date de pe serverele web fără a reîncărca întreaga pagină. Această încărcare asincronă a datelor poate face dificilă răzuirea setului de date complet, deoarece poate fi încărcat progresiv sau declanșat de interacțiunile utilizatorului.
- Captcha și detectarea botului: pentru a preveni scraping și protejarea datelor, site-urile web folosesc diferite contramăsuri, cum ar fi captcha și mecanisme de detectare a botului. Aceste măsuri de securitate împiedică eforturile de scraping și necesită strategii suplimentare de depășit.
- Tehnici anti-scraping: site-urile web folosesc diverse tehnici anti-scraping, cum ar fi blocarea IP, limitarea ratei sau structurile HTML ofucate pentru a descuraja scraper-ul. Aceste tehnici necesită strategii de scraping adaptive pentru a evita detectarea și a răzui datele dorite cu succes.
Strategii pentru răzuirea dinamică a paginilor web de succes
În ciuda provocărilor, există mai multe strategii și tehnici care pot fi folosite pentru a depăși obstacolele cu care se confruntă în timp ce răzuiesc pagini web dinamice. Aceste strategii includ:

- Utilizarea browserelor Headless: Browserele Headless precum Puppeteer sau Selenium permit execuția JavaScript și redarea conținutului dinamic, permițând extragerea cu acuratețe a datelor de pe site-uri web dinamice.
- Inspectarea traficului de rețea: analiza traficului de rețea poate oferi informații despre fluxul de date dintr-un site web dinamic. Aceste cunoștințe pot fi utilizate pentru a identifica apelurile AJAX, pentru a intercepta răspunsurile și pentru a extrage datele necesare.
- Analiza dinamică a conținutului: analizarea DOM-ului HTML după ce conținutul dinamic a fost redat de JavaScript poate ajuta la extragerea datelor dorite. Instrumente precum Beautiful Soup sau Cheerio pot fi utilizate pentru a analiza și extrage date din DOM-ul actualizat.
- Rotația IP și proxy-uri: Rotirea adreselor IP și utilizarea proxy-urilor pot ajuta la depășirea provocărilor de blocare IP și limitare a ratei. Permite răzuirea distribuită și împiedică site-urile web să identifice scraperul ca o singură sursă.
- Tratarea captcha-urilor și tehnicilor anti-răzuire: atunci când te confrunți cu Captcha-uri, folosirea serviciilor de rezolvare a captcha-urilor sau implementarea emulării umane poate ajuta la ocolirea acestor măsuri. În plus, structurile HTML ofucate pot fi proiectate invers folosind tehnici precum traversarea DOM sau recunoașterea modelelor.
Cele mai bune practici pentru Web Scraping dinamic
În timpul răzuirii paginilor web dinamice, este important să urmați anumite bune practici pentru a asigura un proces de scraping de succes și etic. Unele dintre cele mai bune practici includ:
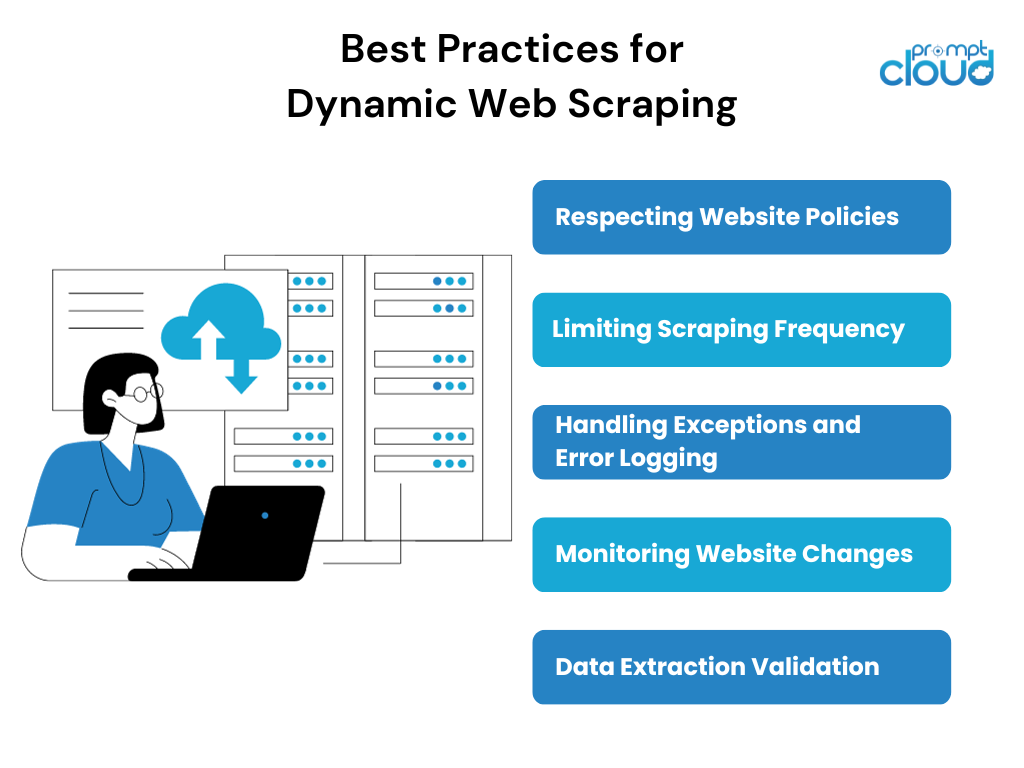
- Respectarea politicilor site-ului: înainte de a elimina orice site web, este esențial să revizuiți și să respectați termenii și condițiile site-ului web, fișierul robots.txt și orice instrucțiuni specifice de scraping menționate.
- Limitarea frecvenței de răzuire: răzuirea excesivă poate pune o presiune atât asupra resurselor scraper-ului, cât și a site-ului web care este răzuit. Implementarea limitelor rezonabile de frecvență de scraping și onorarea limitelor de rată stabilite de site-ul web poate ajuta la menținerea unui proces de scraping armonios.
- Gestionarea excepțiilor și a înregistrării erorilor: scraping web dinamic implică tratarea unor scenarii imprevizibile, cum ar fi erori de rețea, solicitări captcha sau modificări ale structurii site-ului web. Implementarea mecanismelor adecvate de gestionare a excepțiilor și de înregistrare a erorilor va ajuta la identificarea și rezolvarea acestor probleme.
- Monitorizarea modificărilor site-ului web: site-urile web dinamice suferă frecvent actualizări sau reproiectări, care pot rupe scripturile de scraping existente. Monitorizarea regulată a site-ului țintă pentru orice modificări și ajustarea promptă a strategiei de scraping poate asigura extragerea neîntreruptă a datelor.
- Validarea extragerii datelor: validarea și referința încrucișată a datelor extrase cu interfața de utilizator a site-ului web poate ajuta la asigurarea acurateței și completității informațiilor răzuite. Acest pas de validare este esențial în special atunci când răzuiți pagini web dinamice cu conținut în evoluție.
Concluzie
Puterea scrapingului dinamic al paginilor web deschide o lume de oportunități de a accesa date valoroase ascunse în site-urile web dinamice. Depășirea provocărilor asociate cu scraping site-uri web dinamice necesită o combinație de expertiză tehnică și aderarea la practicile etice de scraping.
Înțelegând complexitățile procesării dinamice a paginilor web și implementând strategiile și cele mai bune practici prezentate în acest articol, companiile și persoanele fizice pot debloca întregul potențial al datelor web și pot obține un avantaj competitiv în diferite domenii.
O altă provocare întâlnită în scrapingul dinamic al paginilor web este volumul de date care trebuie extrase. Paginile web dinamice conțin adesea o cantitate mare de informații, ceea ce face dificilă extragerea eficientă a datelor relevante.
Pentru a depăși acest obstacol, companiile pot profita de expertiza furnizorilor de servicii de web scraping. Infrastructura puternică de scraping a PromptCloud și tehnicile avansate de extracție a datelor permit companiilor să gestioneze cu ușurință proiectele de scraping la scară largă.
Cu ajutorul PromptCloud, organizațiile pot extrage informații valoroase din pagini web dinamice și le pot transforma în inteligență acționabilă. Experimentați puterea scrapingului dinamic al paginilor web prin parteneriatul cu PromptCloud astăzi. Contactați-ne la sales@promptcloud.com.