
Scraping dinamic de pagini web cu Python – Ghid de utilizare
Publicat: 2024-06-08Web scraping dinamic implică preluarea datelor de pe site-uri web care generează conținut în timp real prin JavaScript sau Python. Spre deosebire de paginile web statice, conținutul dinamic se încarcă asincron, ceea ce face tehnicile tradiționale de scraping ineficiente.
Scrapingul dinamic web utilizează:
- Site-uri web bazate pe AJAX
- Aplicații pe o singură pagină (SPA)
- Locuri cu elemente de încărcare întârziată
Instrumente și tehnologii cheie:
- Selenium – Automatizează interacțiunile browserului.
- BeautifulSoup – Analizează conținutul HTML.
- Solicitări – Preluează conținutul paginii web.
- lxml – Analizează XML și HTML.
Python dinamic web scraping necesită o înțelegere mai profundă a tehnologiilor web pentru a colecta în mod eficient date în timp real.
Sursa imagine: https://www.scrapehero.com/scrape-a-dynamic-website/
Configurarea mediului Python
Pentru a începe scraping web dinamic Python, este esențial să configurați corect mediul. Urmați acești pași:
- Instalați Python : Asigurați-vă că Python este instalat pe computer. Cea mai recentă versiune poate fi descărcată de pe site-ul oficial Python.
- Creați un mediu virtual :

Activați mediul virtual:

- Instalați bibliotecile necesare :

- Configurați un editor de cod : utilizați un IDE precum PyCharm, VSCode sau Jupyter Notebook pentru a scrie și rula scripturi.
- Familiarizați-vă cu HTML/CSS : înțelegerea structurii paginii web ajută la navigarea și extragerea eficientă a datelor.
Acești pași stabilesc o bază solidă pentru proiectele python de scraping web dinamic.
Înțelegerea elementelor de bază ale solicitărilor HTTP
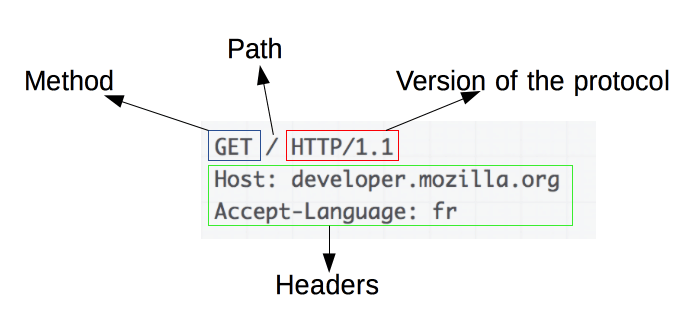
Sursa imaginii: https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview
Solicitările HTTP sunt fundamentul web scraping. Când un client, cum ar fi un browser web sau un web scraper, dorește să recupereze informații de pe un server, trimite o solicitare HTTP. Aceste cereri urmează o structură specifică:
- Metodă : Acțiunea care trebuie efectuată, cum ar fi GET sau POST.
- URL : adresa resursei de pe server.
- Anteturi : metadate despre solicitare, cum ar fi tipul de conținut și agentul utilizator.
- Corp : date opționale trimise împreună cu solicitarea, utilizate de obicei cu POST.
Înțelegerea modului de interpretare și construcție a acestor componente este esențială pentru un web scraping eficient. Bibliotecile Python precum cererile simplifică acest proces, permițând un control precis asupra cererilor.
Instalarea bibliotecilor Python
Sursa imagine: https://ajaytech.co/what-are-python-libraries/
Pentru scraping web dinamic cu Python, asigurați-vă că Python este instalat. Deschideți terminalul sau promptul de comandă și instalați bibliotecile necesare folosind pip:
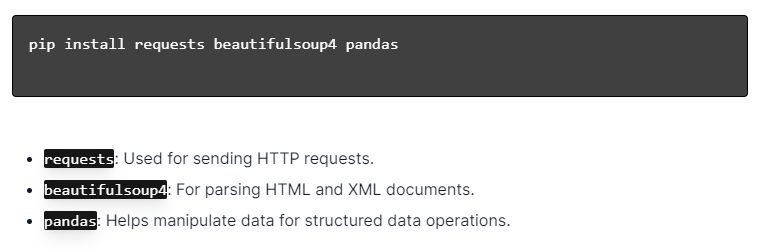
Apoi, importați aceste biblioteci în scriptul dvs.:

Procedând astfel, fiecare bibliotecă va fi disponibilă pentru sarcini de web scraping, cum ar fi trimiterea de solicitări, analizarea HTML și gestionarea eficientă a datelor.
Construirea unui script Web Scraping simplu
Pentru a construi un script de bază de scraping web dinamic în Python, trebuie mai întâi să instalați bibliotecile necesare. Biblioteca „cereri” se ocupă de solicitările HTTP, în timp ce „BeautifulSoup” analizează conținutul HTML.
Pași de urmat:
- Instalați dependențe:

- Importați biblioteci:

- Obțineți conținut HTML:
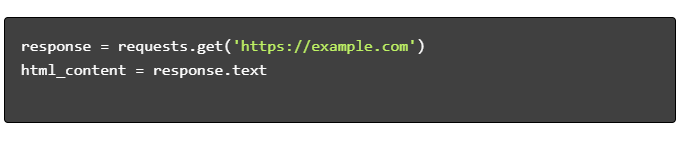
- Analizați HTML:

- Extrageți date:

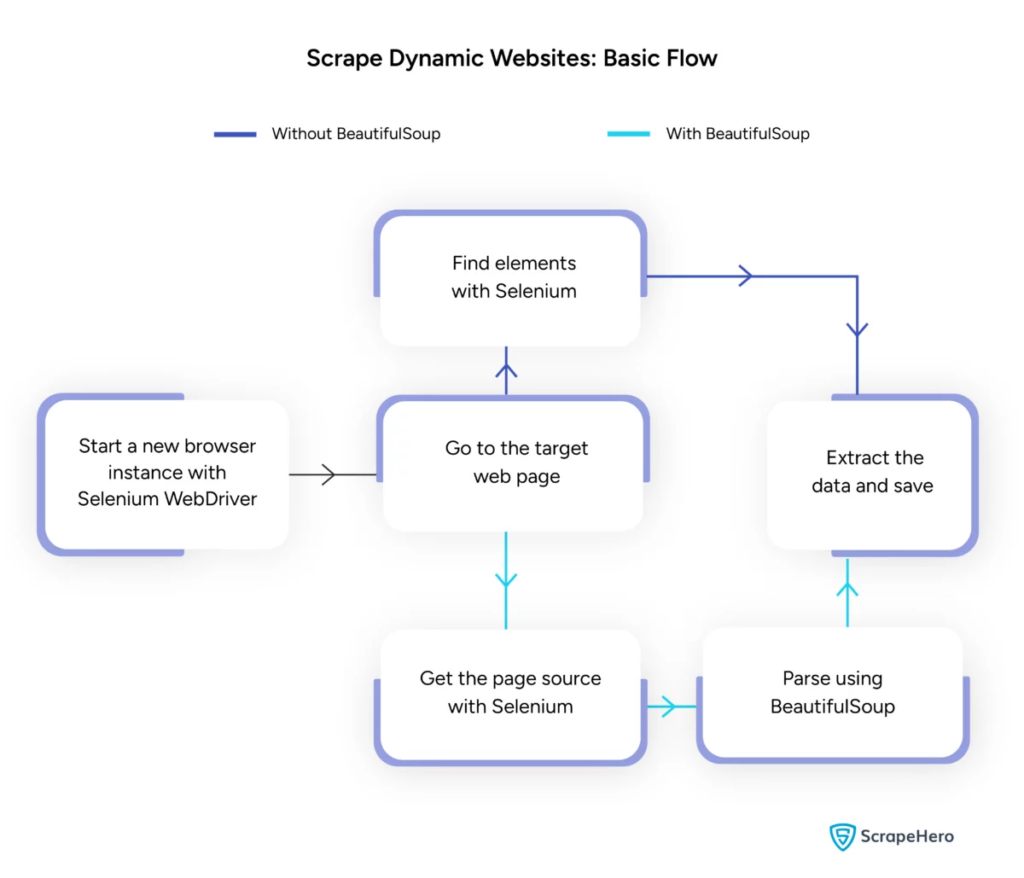
Gestionarea dinamicii Web Scraping cu Python
Site-urile web dinamice generează conținut din mers, necesitând adesea tehnici mai sofisticate.

Luați în considerare următorii pași:
- Identificați elementele țintă : inspectați pagina web pentru a localiza conținut dinamic.
- Alegeți un cadru Python : utilizați biblioteci precum Selenium sau Playwright.
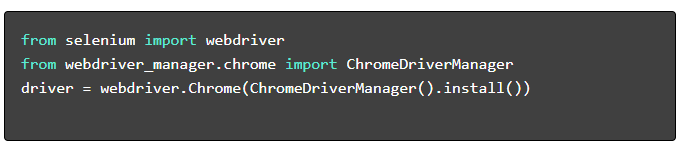
- Instalați pachetele necesare :
- Configurați WebDriver :

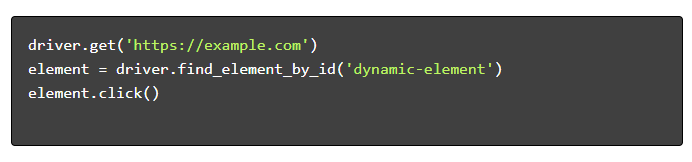
- Navigați și interacționați :
Cele mai bune practici pentru web scraping
Este recomandat să urmați cele mai bune practici de web scraping pentru a asigura eficiența și legalitatea. Mai jos sunt orientările cheie și strategiile de tratare a erorilor:
- Respectați Robots.txt : verificați întotdeauna fișierul robots.txt al site-ului țintă.
- Limitare : implementați întârzieri pentru a preveni supraîncărcarea serverului.
- User-Agent : utilizați un șir personalizat User-Agent pentru a evita potențialele blocări.
- Logica de reîncercare : Folosiți blocurile try-except și configurați logica de reîncercare pentru gestionarea timeout-urilor serverului.
- Înregistrare : Mențineți jurnalele complete pentru depanare.
- Gestionarea excepțiilor : identificați în mod specific erorile de rețea, erorile HTTP și erorile de analiză.
- Detectare Captcha : Încorporați strategii pentru detectarea și rezolvarea sau ocolirea CAPTCHA-urilor.
Provocări obișnuite de scraping web dinamic
Captchas
Multe site-uri web folosesc CAPTCHA pentru a preveni roboții automatizați. Pentru a ocoli acest lucru:
- Utilizați servicii de rezolvare a CAPTCHA, cum ar fi 2Captcha.
- Implementați intervenția umană pentru rezolvarea CAPTCHA.
- Utilizați proxy pentru a limita ratele de solicitare.
Blocarea IP
Site-urile pot bloca adresele IP care fac prea multe solicitări. Contracarați acest lucru prin:
- Folosind proxy rotativi.
- Implementarea limitării cererilor.
- Folosind strategii de rotație utilizator-agent.
Redare JavaScript
Unele site-uri încarcă conținut prin JavaScript. Rezolvați această provocare prin:
- Utilizarea Selenium sau Puppeteer pentru automatizarea browserului.
- Folosind Scrapy-splash pentru redarea conținutului dinamic.
- Explorarea browserelor fără cap pentru a interacționa cu JavaScript.
Probleme legale
Web scraping poate încălca uneori termenii și condițiile. Asigurarea conformității prin:
- Consultanta consultanta juridica.
- Eliminarea datelor accesibile publicului.
- Respectarea directivelor robots.txt.
Analiza datelor
Gestionarea structurilor de date inconsistente poate fi o provocare. Soluțiile includ:
- Folosind biblioteci precum BeautifulSoup pentru analiza HTML.
- Folosirea expresiilor regulate pentru extragerea textului.
- Folosind analizatoare JSON și XML pentru date structurate.
Stocarea și analiza datelor răzuite
Stocarea și analiza datelor scraped sunt pași cruciali în web scraping. Decizia unde să stocați datele depinde de volum și format. Opțiunile comune de stocare includ:
- Fișiere CSV : Ușor pentru seturi de date mici și analize simple.
- Baze de date : baze de date SQL pentru date structurate; NoSQL pentru nestructurat.
Odată stocate, analiza datelor poate fi efectuată folosind bibliotecile Python:
- Pandas : Ideal pentru manipularea și curățarea datelor.
- NumPy : Eficient pentru operații numerice.
- Matplotlib și Seaborn : Potrivit pentru vizualizarea datelor.
- Scikit-learn : oferă instrumente pentru învățarea automată.
Stocarea și analiza adecvată a datelor îmbunătățesc accesibilitatea datelor și informațiile.
Concluzie și pașii următori
După ce ați parcurs un Python dinamic de scraping web, este imperativ să îmbunătățiți înțelegerea instrumentelor și bibliotecilor evidențiate.
- Consultați codul : consultați scriptul final și modularizați-l acolo unde este posibil pentru a îmbunătăți reutilizarea.
- Biblioteci suplimentare : explorați biblioteci avansate precum Scrapy sau Splash pentru nevoi mai complexe.
- Stocarea datelor : luați în considerare opțiuni de stocare robuste - baze de date SQL sau stocare în cloud pentru gestionarea seturilor de date mari.
- Considerații legale și etice : fiți la curent cu liniile directoare legale despre web scraping pentru a evita potențialele încălcări.
- Următoarele proiecte : abordarea noilor proiecte web scraping cu diferite complexități va consolida aceste abilități și mai mult.
Doriți să integrați scrapingul web dinamic profesional cu Python în proiectul dvs.? Pentru acele echipe care necesită extragerea datelor la scară mare, fără complexitatea gestionării lor intern, PromptCloud oferă soluții personalizate. Explorați serviciile PromptCloud pentru o soluție robustă și fiabilă. Contactați-ne astăzi!