
Vocea Bazarului
Publicat: 2024-04-24Acest articol despre modernizarea sistemelor vechi este o piesă însoțitoare a unei discuții pe care am prezentat-o recent la AWS Data Summit for Software Companies despre generarea de valoare din date prin valorificarea celor mai bune practici pentru a asigura succesul în proiectele de învățare automată. Puteți sări chiar în jos aici pentru a-l urmări, dacă preferați.
Să recunoaștem: software-ul este mai ușor de scris decât de întreținut. Acesta este motivul pentru care noi, în calitate de ingineri software, preferăm să „scăpăm și să o luăm de la capăt” în loc să încercăm să înțelegem ce gândea un alt dezvoltator (sau sinele nostru din trecut). Se pare că am uitat în mod colectiv că „programele trebuie scrise pentru ca oamenii să le citească și doar întâmplător pentru ca mașini să le execute”.
Știi că este adevărat – cu toții a trebuit să urmăm cu minuțiozitate printr-o caserolă de cod de spaghete și abstracții subțiri, în stilul lumii vechi, săpând după carnea programului, doar pentru a găsi nimic altceva decât mizerie în fundul farfuriilor noastre.
Este ușor să strigi „WTF” și să dai vina pe dezvoltatorul anterior, dar adevărul este adesea mai complicat. Nu putem vedea viitorul, așa că este imposibil să înțelegem cum vor crește cerințele, tehnologia sau obiectivele de afaceri atunci când proiectăm un sistem net-nou. Ca rezultat, sistemele pot deveni ilizibile pe măsură ce sfera lor de aplicare crește odată cu dependența afacerii de ele. Acesta este un paradox: sistemele mai vechi, mai greu de întreținut oferă adesea cea mai mare valoare. Este greu de lucrat pentru că au crescut împreună cu compania și e înfricoșător pentru a lucra pentru că ruperea ar putea fi o catastrofă.
Iată unde vă chem: dacă vă plac problemele grele, pline de satisfacții... încercați. Luați cel mai vechi sistem pe care îl aveți și faceți-l întreținut. Îl știi pe cel despre care vorbesc — pe care nimeni nu îl va „deține”. De aceea depind celelalte departamente, dar inginerii îl urăsc. Cel pe care a trebuit să-l corectezi mai întâi pe Log4Shell. Fă-o. Te provoc.
Am avut recent o astfel de oportunitate de a actualiza un sistem de învățare automată vechi de un deceniu la Bazaarvoice. La suprafață, nu suna interesant : chestia asta nici măcar nu avea rețele neuronale! Cui îi pasă! Ei bine... conta. Acest sistem procesează aproape fiecare recenzie de produs generată de utilizatori primită de Bazaarvoice – aproape 9 milioane pe lună – și face acest lucru cu 90 de milioane de apeluri de inferență către modele de învățare automată. Da, 90 de milioane de concluzii! Este o scară uriașă și abia așteptam să mă scufund.
În această postare, voi împărtăși modul în care modernizarea acestui sistem moștenit printr-o re-arhitectură, în loc de o rescrire, ne-a permis să-l facem scalabil și rentabil, fără a fi nevoie să scoatem tot codul și să o luăm de la capăt. Sistemul rezultat este fără server, containerizat și poate fi întreținut, reducând în același timp costurile noastre de găzduire cu aproape 80%.
Ce este un sistem moștenit?
Un sistem moștenit se referă la un software de calcul și/sau hardware vechi care rămâne în funcțiune. Deși poate încă să-și îndeplinească scopul inițial, îi lipsește scalabilitatea pentru creșterea viitoare.
Vechi sisteme vechi
În primul rând, să aruncăm o privire la ceea ce avem de-a face aici. Sistemul moștenit echipa mea actualiza conținutul generat de utilizatori pentru tot Bazaarvoice. Mai exact, determină dacă fiecare parte de conținut este adecvată pentru site-urile web ale clienților noștri.

Acest lucru sună simplu - eliminați infracțiunile evidente, cum ar fi discursul instigator la ură, limbajul urât sau solicitările - dar, în practică, este mult mai nuanțat. Fiecare client are cerințe unice pentru ceea ce consideră potrivit. Brandurile de bere, de exemplu, s-ar aștepta la discuții despre alcool, dar un brand pentru copii s-ar putea să nu. Captăm aceste opțiuni specifice clientului atunci când îmbarcăm clienți noi, iar echipa noastră de servicii pentru clienți îi codifică într-o bază de date de management.
Pentru un plus de complexitate, eșantionăm și un subset al conținutului nostru pentru a fi moderat de moderatori umani. Acest lucru ne permite să măsurăm continuu performanța modelelor noastre și să descoperim oportunități de a construi mai multe modele.
Arhitectura completă a sistemului nostru moștenit este prezentată mai jos:
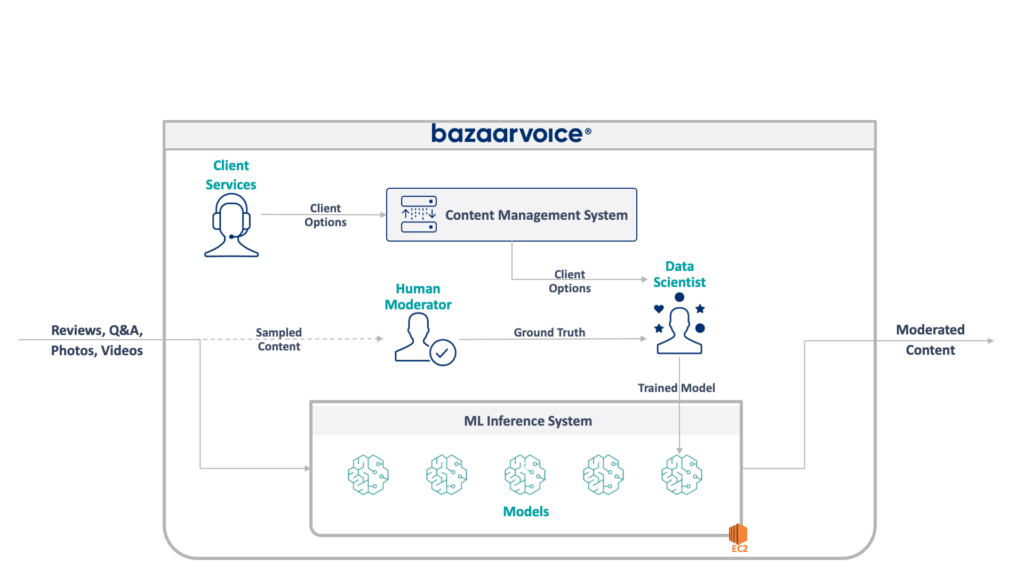
Acest sistem are unele dezavantaje serioase. Mai exact, toate modelele sunt găzduite pe o singură instanță EC2. Acest lucru nu s-a datorat unei inginerie proastă, ci doar a incapacității programatorilor inițiali de a prevedea amploarea dorită de companie. Nimeni nu s-a gândit că va crește la fel de mult.
În plus, sistemul a suferit din cauza respingerii dezvoltatorului: a fost scris în Scala, ceea ce puțini ingineri l-au înțeles. Astfel, a fost adesea trecută cu vederea pentru îmbunătățire, deoarece nimeni nu a vrut să-l atingă.
Ca urmare, sistemul a continuat să crească într-o manieră de a menține luminile aprinse. Odată ce ne-am apucat să-l re-arhitectem, rula pe o singură instanță x1e.8xlarge. Acest lucru avea aproape un terabyte de ram și costă aproximativ 5.000 USD/lună (fără rezervare) pentru a funcționa. Nu vă faceți griji, totuși, tocmai am lansat un al doilea pentru redundanță și al treilea pentru QA.
Acest sistem era costisitor de rulat și prezenta un risc ridicat de eșec (un singur model prost poate distruge întregul serviciu). În plus, baza de cod nu fusese dezvoltată în mod activ și, prin urmare, era semnificativ depășită cu pachetele moderne de știință a datelor și nu a urmat practicile noastre standard pentru serviciile scrise în Scala.
Un nou sistem
Când am reproiectat acest sistem, am avut un obiectiv clar: să-l facem scalabil. Reducerea costurilor de operare a fost un obiectiv secundar, la fel ca facilitarea managementului modelului și codului.
Noul design cu care am venit este ilustrat mai jos:

Abordarea noastră pentru a rezolva toate acestea a fost să punem fiecare model de învățare automată pe un punct final izolat SageMaker Serverless. La fel ca și funcțiile AWS Lambda, punctele finale fără server se opresc atunci când nu sunt utilizate - economisindu-ne costurile de rulare pentru modelele utilizate rar. De asemenea, se pot extinde rapid ca răspuns la creșterea traficului.

În plus, am expus opțiunile clientului unui singur microserviciu care direcționează conținutul către modelele adecvate. Aceasta a fost cea mai mare parte a noului cod pe care a trebuit să-l scriem: un API mic, care a fost ușor de întreținut și a permis oamenilor noștri de știință de date să actualizeze și să implementeze mai ușor modele noi.
Această abordare are următoarele beneficii:
- S-a redus timpul de valorificare de peste 6 ori. Mai exact, direcționarea traficului către modelele existente este instantanee, iar implementarea modelelor noi se poate face în mai puțin de 5 minute în loc de 30.
- Scalăm fără limită – avem în prezent 400 de modele, dar intenționăm să le creștem la mii pentru a continua să creștem cantitatea de conținut pe care o putem modera automat
- Am observat o reducere a costurilor cu 82% care a trecut de la EC2, deoarece funcțiile se dezactivează atunci când nu sunt utilizate și nu plătim pentru mașinile de top care sunt subutilizate
Cu toate acestea, simpla proiectare a unei arhitecturi ideale nu este partea dificilă cu adevărat interesantă a reconstrucției unui sistem moștenit - trebuie să migrați la acesta.
Prima noastră provocare în migrare a fost să ne dăm seama cum naiba să migrem un model Java WEKA pentru a rula pe SageMaker, să nu mai vorbim de SageMaker Serverless.
Din fericire, SageMaker implementează modele în containerele Docker, așa că cel puțin am putea îngheța versiunile Java și de dependență pentru a se potrivi cu vechiul nostru cod. Acest lucru ar ajuta să se asigure că modelele găzduite în noul sistem au returnat aceleași rezultate ca și cel vechi.

Pentru a face containerul compatibil cu SageMaker, tot ce trebuie să faceți este să implementați câteva puncte finale HTTP specifice:
-
POST /invocation— acceptă intrarea, efectuează inferențe și returnează rezultate. -
GET /ping— returnează 200 dacă serverul JVM este sănătos
(Am ales să ignorăm toate problemele din jurul containerelor multimodel BYO și setului de instrumente de inferență SageMaker.)
Câteva abstracții rapide în jurul com.sun.net.httpserver.HttpServer și eram gata să mergem.
Și știi ce? Acesta a fost de fapt destul de distractiv. A juca cu containerele Docker și a forța ceva vechi de 10 ani să intre în SageMaker Serverless a avut o atmosferă un pic de manieră. A fost destul de interesant când l-am pus să funcționeze – mai ales când am primit codul de sistem moștenit pentru al construi în noua noastră stivă sbt în loc de Maven.
Noua stivă sbt a făcut mai ușor de lucrat, iar containerizarea ne-a asigurat că putem obține un comportament adecvat în timp ce rulăm în mediul SageMaker.
Migrarea la un sistem nou
Deci avem modelele în containere și le putem implementa în SageMaker - aproape gata, nu? Nu chiar.
Lecția grea despre migrarea către o nouă arhitectură este că trebuie să construiți de trei ori sistemul real doar pentru a suporta migrarea. Pe lângă noul sistem, a trebuit să construim:
- O conductă de captare a datelor în sistemul vechi pentru a înregistra intrările și ieșirile din model. Le-am folosit pentru a confirma că noul sistem va returna aceleași rezultate
- O conductă de procesare a datelor în noul sistem pentru a calcula rezultatele și a le compara cu datele din vechiul sistem. Acest lucru a implicat o cantitate mare de măsurători cu Datadog și trebuia să ofere posibilitatea de a reda datele atunci când am găsit discrepanțe
- Un sistem complet de implementare a modelului pentru a evita impactul utilizatorilor vechiului sistem (care ar încărca pur și simplu modele pe S3). Știam că vrem să le mutăm într-un API în cele din urmă, dar pentru lansarea inițială, trebuia să facem acest lucru fără probleme.
Toate acestea erau un cod de aruncat pe care știam că îl putem arunca odată ce am terminat de migrat toți utilizatorii, dar tot trebuia să îl construim și să ne asigurăm că rezultatele noului sistem se potrivesc cu cele vechi.
Așteptați-vă la asta în avans.
Deși construirea instrumentelor și sistemelor de migrare a luat cu siguranță mai mult de 60% din timpul nostru de inginerie pentru acest proiect, a fost și o experiență distractivă. Testarea unitară a devenit mai mult ca experimentele de știință a datelor: am scris suite întregi pentru a ne asigura că rezultatele noastre se potrivesc exact . A fost un mod diferit de a gândi care a făcut ca munca să fie mult mai distractivă. Un pas în afara cutiilor noastre normale, dacă vrei.
Modernizarea sistemelor moștenite printr-o re-arhitectură
Data viitoare când veți fi tentat să reconstruiți un sistem de la cod în sus, aș dori să vă încurajez să încercați să migrați arhitectura în loc de cod. Veți găsi provocări tehnice interesante și pline de satisfacții și probabil vă veți bucura mult mai mult decât depanarea cazurilor marginale neașteptate ale noului cod.
Doriți să aflați mai multe? Urmărește mai jos discursul pe care l-am susținut la AWS Data Summit, care analizează partea MLOps a lucrurilor.