
Cum funcționează un crawler web
Publicat: 2023-12-05Crawlerele web au o funcție vitală în indexarea și structurarea informațiilor extinse prezente pe internet. Rolul lor implică parcurgerea paginilor web, culegerea de date și transformarea acestora în căutare. Acest articol analizează mecanica unui crawler web, oferind informații despre componentele, operațiunile și diversele categorii ale acestuia. Să pătrundem în lumea crawlerelor web!
Ce este un web crawler
Un crawler web, denumit spider sau bot, este un script sau un program automat conceput pentru a naviga metodic prin site-uri web. Începe cu un URL de bază și apoi urmează link-uri HTML pentru a vizita alte pagini web, formând o rețea de pagini interconectate care pot fi indexate și analizate.
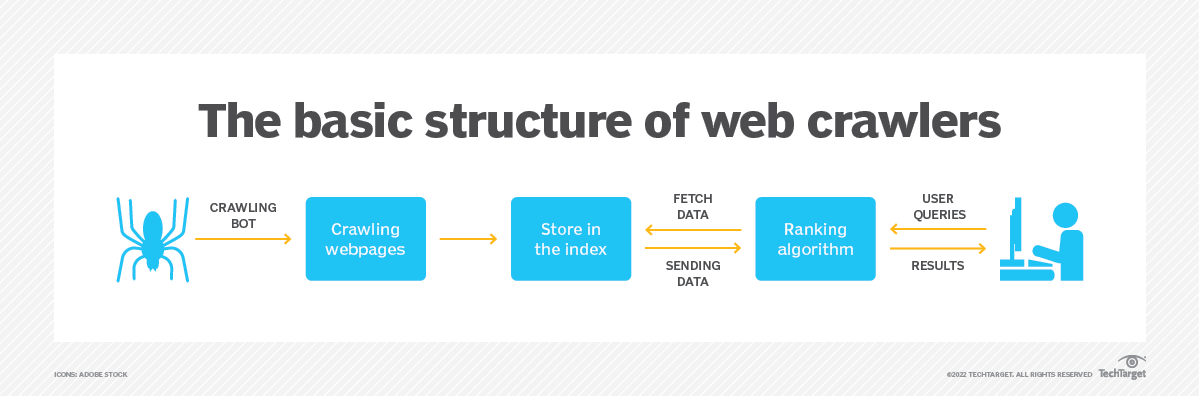
Sursa imagine: https://www.techtarget.com/
Scopul unui crawler web
Obiectivul principal al unui crawler web este de a culege informații din paginile web și de a genera un index care poate fi căutat pentru o recuperare eficientă. Motoarele de căutare majore precum Google, Bing și Yahoo se bazează în mare măsură pe crawlerele web pentru a-și construi bazele de date de căutare. Prin examinarea sistematică a conținutului web, motoarele de căutare pot oferi utilizatorilor rezultate de căutare pertinente și actuale.
Este important de reținut că aplicația crawlerelor web se extinde dincolo de motoarele de căutare. Ele sunt, de asemenea, utilizate de diverse organizații pentru sarcini precum extragerea datelor, agregarea de conținut, monitorizarea site-urilor web și chiar securitatea cibernetică.
Componentele unui crawler web
Un crawler web cuprinde mai multe componente care lucrează împreună pentru a-și atinge obiectivele. Iată componentele cheie ale unui crawler web:
- Frontieră URL: această componentă gestionează colecția de adrese URL care așteaptă să fie accesate cu crawlere. Prioritizează adresele URL pe baza unor factori precum relevanța, prospețimea sau importanța site-ului.
- Descărcător: programul de descărcare preia paginile web pe baza adreselor URL furnizate de frontiera URL. Trimite cereri HTTP către serverele web, primește răspunsuri și salvează conținutul web preluat pentru procesare ulterioară.
- Analizator: analizatorul procesează paginile web descărcate, extragând informații utile, cum ar fi linkuri, text, imagini și metadate. Acesta analizează structura paginii și extrage adresele URL ale paginilor legate pentru a fi adăugate la frontiera URL.
- Stocarea datelor: componenta de stocare a datelor stochează datele colectate, inclusiv paginile web, informațiile extrase și datele de indexare. Aceste date pot fi stocate în diferite formate, cum ar fi o bază de date sau un sistem de fișiere distribuit.
Cum funcționează un crawler web
După ce am obținut o perspectivă asupra elementelor implicate, să ne aprofundăm în procedura secvențială care elucidează funcționarea unui crawler web:
- Adresă URL inițială: crawler-ul începe cu o adresă URL inițială, care poate fi orice pagină web sau o listă de adrese URL. Această adresă URL este adăugată la frontiera URL pentru a iniția procesul de accesare cu crawlere.
- Preluare: crawler-ul selectează o adresă URL din frontiera URL și trimite o solicitare HTTP către serverul web corespunzător. Serverul răspunde cu conținutul paginii web, care este apoi preluat de componenta de descărcare.
- Analizare: analizatorul procesează pagina web preluată, extragând informații relevante, cum ar fi linkuri, text și metadate. De asemenea, identifică și adaugă adrese URL noi găsite pe pagină la frontiera URL.
- Analiza linkurilor: crawler-ul prioritizează și adaugă adresele URL extrase la frontiera URL pe baza anumitor criterii precum relevanța, prospețimea sau importanța. Acest lucru ajută la determinarea ordinii în care crawler-ul va vizita și accesa paginile.
- Repetă procesul: crawler-ul continuă procesul selectând adrese URL din frontiera URL, preluând conținutul lor web, analizând paginile și extragând mai multe adrese URL. Acest proces se repetă până când nu mai există adrese URL de accesat cu crawlere sau până când se atinge o limită predefinită.
- Stocarea datelor: Pe tot parcursul procesului de crawling, datele colectate sunt stocate în componenta de stocare a datelor. Aceste date pot fi utilizate ulterior pentru indexare, analiză sau alte scopuri.
Tipuri de crawler-uri web
Crawlerele web vin în diferite variante și au cazuri de utilizare specifice. Iată câteva tipuri frecvent utilizate de crawler-uri web:

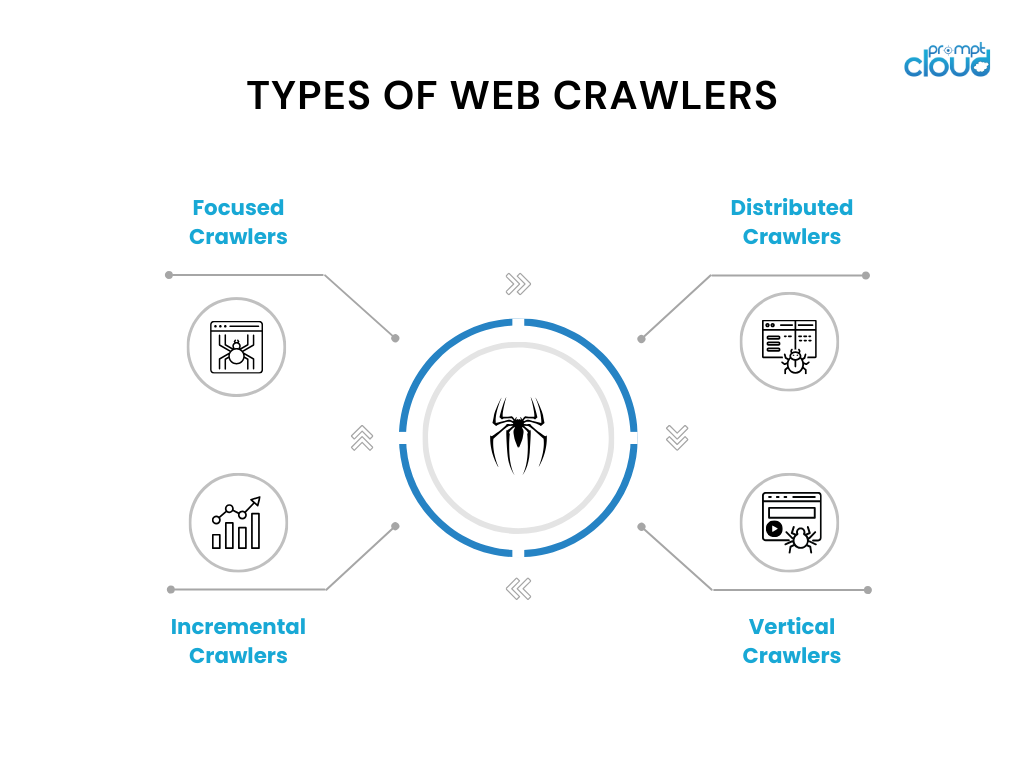
- Crawlerele focalizate: aceste crawler-uri operează într-un anumit domeniu sau subiect și accesează cu crawlere pagini relevante pentru acel domeniu. Exemplele includ crawlerele de actualitate utilizate pentru site-uri web de știri sau lucrări de cercetare.
- Crawlerele incrementale: crawlerele incrementale se concentrează pe accesarea cu crawlere a conținutului nou sau actualizat de la ultima accesare cu crawlere. Ei folosesc tehnici precum analiza de marcaj temporal sau algoritmi de detectare a modificărilor pentru a identifica și accesa cu crawlere paginile modificate.
- Crawlerele distribuite: în crawlerele distribuite, mai multe instanțe ale crawlerului rulează în paralel, împărțind sarcina de lucru a accesării cu crawlere a unui număr mare de pagini. Această abordare permite accesarea cu crawlere mai rapidă și scalabilitate îmbunătățită.
- Crawlerele verticale: crawlerele verticale vizează anumite tipuri de conținut sau date din paginile web, cum ar fi imagini, videoclipuri sau informații despre produse. Acestea sunt concepute pentru a extrage și indexa tipuri specifice de date pentru motoarele de căutare specializate.
Cât de des ar trebui să accesați cu crawlere paginile web?
Frecvența accesării cu crawlere a paginilor web depinde de mai mulți factori, printre care dimensiunea și frecvența de actualizare a site-ului web, importanța paginilor și resursele disponibile. Unele site-uri web pot necesita accesarea cu crawlere frecventă pentru a se asigura că cele mai recente informații sunt indexate, în timp ce altele pot fi accesate cu crawlere mai rar.
Pentru site-urile web cu trafic ridicat sau cele cu conținut în schimbare rapidă, accesarea cu crawlere mai frecventă este esențială pentru a menține informațiile actualizate. Pe de altă parte, site-urile web mai mici sau paginile cu actualizări rare pot fi accesate cu crawlere mai rar, reducând volumul de muncă și resursele necesare.
Web crawler intern versus instrumente de crawling web
Când se analizează crearea unui crawler web, este esențial să se evalueze complexitatea, scalabilitatea și resursele necesare. Construirea unui crawler de la zero poate fi un efort care necesită mult timp, cuprinzând activități precum gestionarea concurenței, supravegherea sistemelor distribuite și abordarea obstacolelor de infrastructură. Pe de altă parte, optarea pentru instrumente sau cadre de crawling web poate oferi o rezoluție mai rapidă și mai eficientă.
Ca alternativă, utilizarea instrumentelor de crawling web sau a cadrelor poate oferi o soluție mai rapidă și mai eficientă. Aceste instrumente oferă funcții precum reguli de accesare cu crawlere personalizabile, capabilități de extragere a datelor și opțiuni de stocare a datelor. Folosind instrumentele existente, dezvoltatorii se pot concentra pe cerințele lor specifice, cum ar fi analiza datelor sau integrarea cu alte sisteme.
Cu toate acestea, este esențial să luați în considerare limitările și costurile asociate cu utilizarea instrumentelor terțe, cum ar fi restricțiile privind personalizarea, proprietatea datelor și potențialele modele de prețuri.
Concluzie
Motoarele de căutare se bazează în mare măsură pe crawlerele web, care sunt esențiale în sarcina de a aranja și cataloga informațiile extinse prezente pe internet. Înțelegerea mecanicilor, componentelor și diverselor categorii de crawler-uri web permite o înțelegere mai profundă a tehnologiei complicate care stă la baza acestui proces fundamental.
Indiferent dacă alegeți să construiți un crawler web de la zero sau să utilizați instrumente preexistente pentru accesarea cu crawlere web, devine imperativ să adoptați o abordare aliniată nevoilor dvs. specifice. Aceasta implică luarea în considerare a unor factori precum scalabilitatea, complexitatea și resursele de care dispuneți. Luând în considerare aceste elemente, puteți utiliza în mod eficient accesarea cu crawlere pe web pentru a aduna și analiza date valoroase, propulsându-vă astfel afacerile sau eforturile de cercetare .
La PromptCloud, suntem specializați în extragerea datelor web, aprovizionarea de date din resurse online disponibile public. Luați legătura cu noi la sales@promptcloud.com