
Stăpânirea paginilor Web Scrapers: un ghid pentru începători pentru extragerea datelor online
Publicat: 2024-04-09Ce sunt Web Page Scrapers?
Web page scraper este un instrument conceput pentru a extrage date de pe site-uri web. Simulează navigarea umană pentru a aduna conținut specific. Începătorii folosesc adesea aceste scrapers pentru diverse sarcini, inclusiv cercetarea pieței, monitorizarea prețurilor și compilarea de date pentru proiecte de învățare automată.
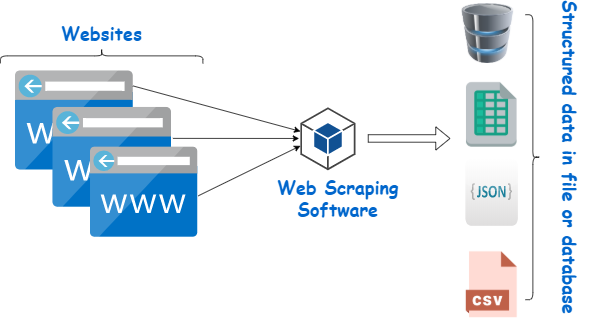
Sursa imaginii: https://www.webharvy.com/articles/what-is-web-scraping.html
- Ușurință în utilizare: sunt ușor de utilizat, permițând persoanelor cu abilități tehnice minime să capteze datele web în mod eficient.
- Eficiență: Scrapers pot aduna rapid cantități mari de date, depășind cu mult eforturile de colectare manuală a datelor.
- Acuratețe: răzuirea automată reduce riscul de eroare umană, îmbunătățind acuratețea datelor.
- Eficient din punct de vedere al costurilor: elimină necesitatea introducerii manuale, economisind costurile cu forța de muncă și timp.
Înțelegerea funcționalității scraperelor de pagini web este esențială pentru oricine dorește să valorifice puterea datelor web.
Crearea unui Scraper simplu de pagină web cu Python
Pentru a începe crearea unui scraper de pagină web în Python, trebuie să instalați anumite biblioteci, și anume solicitări de a face solicitări HTTP către o pagină web și BeautifulSoup de la bs4 pentru analizarea documentelor HTML și XML.
- Instrumente de adunare:
- Biblioteci: utilizați solicitările pentru a prelua pagini web și BeautifulSoup pentru a analiza conținutul HTML descărcat.
- Direcționarea paginii web:
- Definiți adresa URL a paginii web care conține datele pe care vrem să le răzuim.
- Descărcarea conținutului:
- Folosind solicitări, descărcați codul HTML al paginii web.
- Analizarea HTML-ului:
- BeautifulSoup va transforma codul HTML descărcat într-un format structurat pentru o navigare ușoară.
- Extragerea datelor:
- Identificați etichetele HTML specifice care conțin informațiile dorite (de exemplu, titlurile produselor din etichetele <div>).
- Folosind metodele BeautifulSoup, extrageți și procesați datele de care aveți nevoie.
Nu uitați să vizați anumite elemente HTML relevante pentru informațiile pe care doriți să le extrageți.
Proces pas cu pas pentru răzuirea unei pagini web
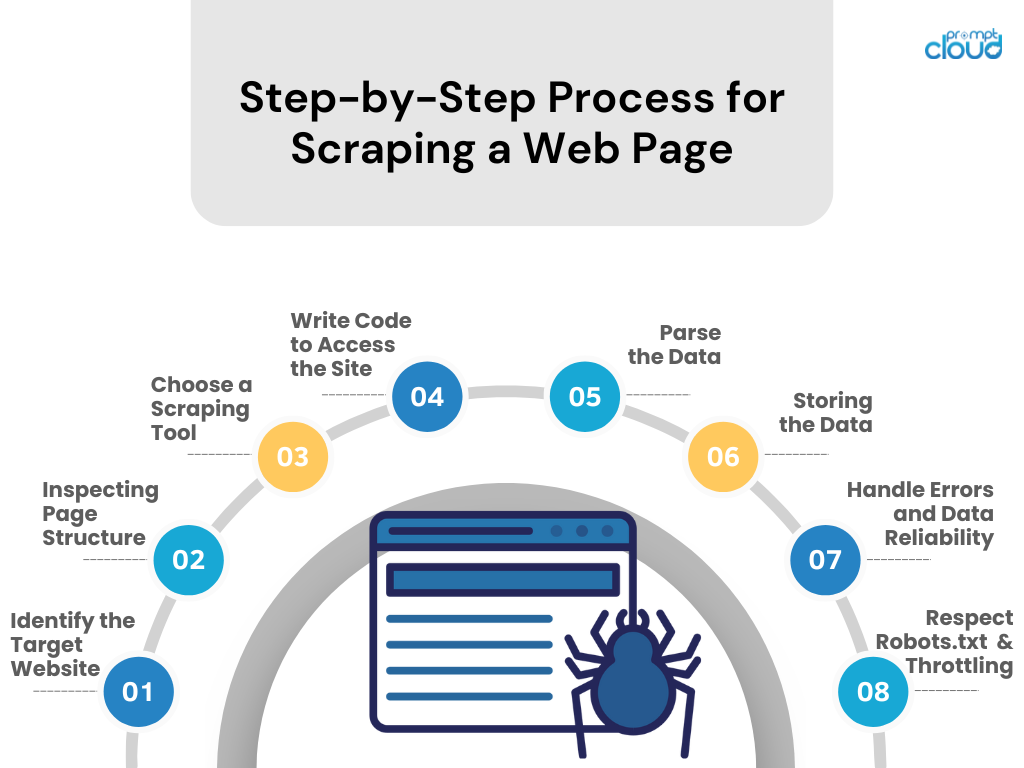
- Identificați site-ul țintă
Cercetați site-ul web pe care doriți să îl răzuiți. Asigurați-vă că este legal și etic să faceți acest lucru. - Inspectarea structurii paginii
Utilizați instrumentele de dezvoltare ale browserului pentru a examina structura HTML, selectoarele CSS și conținutul bazat pe JavaScript. - Alegeți un instrument de răzuire
Selectați un instrument sau o bibliotecă într-un limbaj de programare cu care vă simțiți confortabil (de exemplu, BeautifulSoup sau Scrapy de la Python). - Scrieți codul pentru a accesa site-ul
Creați un script care solicită date de pe site, folosind apeluri API dacă sunt disponibile sau solicitări HTTP. - Analizați datele
Extrageți datele relevante din pagina web prin analizarea HTML/CSS/JavaScript. - Stocarea Datelor
Salvați datele răzuite într-un format structurat, cum ar fi CSV, JSON sau direct într-o bază de date. - Gestionați erorile și fiabilitatea datelor
Implementați gestionarea erorilor pentru a gestiona eșecurile cererilor și pentru a menține integritatea datelor. - Respectați Robots.txt și Throttling
Respectați regulile de fișier robots.txt ale site-ului și evitați copleșirea serverului controlând rata de solicitare.
Selectarea instrumentelor de răzuire web ideale pentru nevoile dvs
Când răzuiți web, selectarea instrumentelor aliniate cu competența și obiectivele dvs. este crucială. Începătorii ar trebui să ia în considerare:
- Ușurință în utilizare: Optați pentru instrumente intuitive cu asistență vizuală și documentație clară.
- Cerințe de date: Evaluați structura și complexitatea datelor țintă pentru a determina dacă este necesară o extensie simplă sau un software robust.
- Buget: cântăriți costul față de caracteristici; multe răzuitoare eficiente oferă niveluri gratuite.
- Personalizare: Asigurați-vă că instrumentul este adaptabil pentru nevoi specifice de răzuire.
- Asistență: Accesul la o comunitate de utilizatori utilă ajută la depanarea și îmbunătățirea.
Alegeți cu înțelepciune pentru o călătorie lină de răzuire.
Sfaturi și trucuri pentru optimizarea paginii dvs. web Scraper
- Utilizați biblioteci eficiente de analiză, cum ar fi BeautifulSoup sau Lxml în Python, pentru o procesare HTML mai rapidă.
- Implementați memorarea în cache pentru a evita re-descărcarea paginilor și pentru a reduce încărcarea pe server.
- Respectați fișierele robots.txt și folosiți limitarea ratei pentru a preveni interzicerea site-ului țintă.
- Rotiți agenții utilizatori și serverele proxy pentru a imita comportamentul uman și pentru a evita detectarea.
- Programați răzuitoare în timpul orelor de vârf pentru a minimiza impactul asupra performanței site-ului.
- Optați pentru punctele finale API, dacă sunt disponibile, deoarece oferă date structurate și sunt în general mai eficiente.
- Evitați eliminarea datelor inutile, fiind selectiv cu interogările dvs., reducând lățimea de bandă și stocarea necesare.
- Actualizați-vă în mod regulat scraper-urile pentru a se adapta la schimbările în structura site-ului web și pentru a menține integritatea datelor.
Gestionarea problemelor obișnuite și depanarea la răzuirea paginilor web
Când lucrează cu răzuitoare de pagini web, începătorii se pot confrunta cu mai multe probleme comune:

- Probleme cu selectorul : Asigurați-vă că selectorii se potrivesc cu structura curentă a paginii web. Instrumente precum instrumentele pentru dezvoltatori de browser pot ajuta la identificarea selectoarelor corecte.
- Conținut dinamic : unele pagini web încarcă conținut dinamic cu JavaScript. În astfel de cazuri, luați în considerare utilizarea browserelor fără cap sau instrumente care redau JavaScript.
- Cereri blocate : site-urile web pot bloca scrapers. Folosiți strategii precum rotația agenților utilizatori, utilizarea proxy-urilor și respectarea robots.txt pentru a atenua blocarea.
- Probleme legate de formatul datelor : este posibil ca datele extrase să necesite curățare sau formatare. Utilizați expresii regulate și manipularea șirurilor pentru a standardiza datele.
Nu uitați să consultați documentația și forumurile comunității pentru îndrumări specifice de depanare.
Concluzie
Începătorii pot acum colecta în mod convenabil date de pe web prin intermediul scraper-ului de pagini web, făcând cercetarea și analiza mai eficiente. Înțelegerea metodelor potrivite, luând în considerare aspectele legale și etice, permite utilizatorilor să valorifice întregul potențial al web scraping. Urmați aceste instrucțiuni pentru o introducere simplă în scraping-ul paginilor web, plină de informații valoroase și luare a deciziilor în cunoștință de cauză.
Întrebări frecvente:
Ce este răzuirea unei pagini?
Web scraping, cunoscut și sub numele de data scraping sau web harvesting, constă în extragerea automată a datelor de pe site-uri web folosind programe de calculator care imită comportamentele umane de navigare. Cu un răzuitor al paginii web, cantități mari de informații pot fi sortate rapid, concentrându-se doar pe secțiuni semnificative, în loc să le compilați manual.
Companiile aplică web scraping pentru funcții precum examinarea costurilor, gestionarea reputației, analiza tendințelor și executarea de analize competitive. Implementarea proiectelor de web scraping garantează verificarea faptului că site-urile web vizitate aprobă acțiunea și respectarea tuturor protocoalelor robots.txt și no-follow relevante.
Cum răzuiesc o pagină întreagă?
Pentru a răzui o pagină web întreagă, aveți nevoie în general de două componente: o modalitate de a localiza datele necesare în pagina web și un mecanism de salvare a acestor date în altă parte. Multe limbaje de programare acceptă web scraping, în special Python și JavaScript.
Există diverse biblioteci open-source pentru ambele, simplificând și mai mult procesul. Unele opțiuni populare printre dezvoltatorii Python includ BeautifulSoup, Requests, LXML și Scrapy. Alternativ, platformele comerciale, cum ar fi ParseHub și Octoparse, permit persoanelor mai puțin tehnice să construiască vizual fluxuri de lucru complexe de web scraping. După instalarea bibliotecilor necesare și înțelegerea conceptelor de bază din spatele selectării elementelor DOM, începeți prin a identifica punctele de date de interes în pagina web țintă.
Utilizați instrumentele pentru dezvoltatori de browser pentru a inspecta etichetele și atributele HTML, apoi traduceți aceste constatări în sintaxa corespunzătoare acceptată de biblioteca sau platforma aleasă. În cele din urmă, specificați preferințele de format de ieșire, fie CSV, Excel, JSON, SQL sau altă opțiune, împreună cu destinațiile în care se află datele salvate.
Cum folosesc Google scraper?
Contrar credinței populare, Google nu oferă în mod direct un instrument public de scraping web în sine, în ciuda faptului că furnizează API-uri și SDK-uri pentru a facilita integrarea perfectă cu mai multe produse. Cu toate acestea, dezvoltatorii calificați au creat soluții terțe construite pe baza tehnologiilor de bază ale Google, extinzând în mod eficient capabilitățile dincolo de funcționalitatea nativă. Exemplele includ SerpApi, care retrage aspectele complicate ale Google Search Console și prezintă o interfață ușor de utilizat pentru urmărirea clasării cuvintelor cheie, estimarea organică a traficului și explorarea backlink-urilor.
Deși sunt distincte din punct de vedere tehnic de web scraping tradițional, aceste modele hibride estompează liniile care separă definițiile convenționale. Alte cazuri prezintă eforturile de inginerie inversă aplicate pentru reconstruirea logicii interne care conduce Google Maps Platform, YouTube Data API v3 sau Google Shopping Services, oferind funcționalități remarcabil de apropiate de omologii inițiali, deși supuse unor grade diferite de riscuri de legalitate și durabilitate. În cele din urmă, aspiranții scrapers de pagini web ar trebui să exploreze diverse opțiuni și să evalueze meritele în raport cu cerințele specifice înainte de a se angaja într-o anumită cale.
Este Facebook scraper legal?
După cum se precizează în Politicile pentru dezvoltatori Facebook, scrapingul web neautorizat constituie o încălcare clară a standardelor comunității lor. Utilizatorii sunt de acord să nu dezvolte sau să opereze aplicații, scripturi sau alte mecanisme concepute pentru a ocoli sau depăși limitele de rată API desemnate și nici nu vor încerca să descifreze, să decompileze sau să facă inginerie inversă a oricărui aspect al Site-ului sau Serviciului. În plus, evidențiază așteptările privind protecția datelor și confidențialitatea, necesitând consimțământul explicit al utilizatorului înainte de a partaja informații de identificare personală în afara contextelor permise.
Orice nerespectare a principiilor evidențiate declanșează escaladarea măsurilor disciplinare, începând cu avertismente și avansând progresiv către accesul restricționat sau revocarea completă a privilegiilor în funcție de nivelurile de severitate. În ciuda excepțiilor stabilite pentru cercetătorii în domeniul securității care operează în cadrul programelor aprobate de recompense pentru erori, consensul general susține evitarea inițiativelor neautorizate de eliminare a Facebook pentru a evita complicațiile inutile. În schimb, luați în considerare urmărirea alternativelor compatibile cu normele și convențiile dominante aprobate de platformă.