
Depășirea provocărilor tehnice în Web Scraping: soluții experte
Publicat: 2024-03-29Web scraping este o practică care vine cu numeroase provocări tehnice, chiar și pentru mineri de date experimentați. Aceasta presupune utilizarea tehnicilor de programare pentru a obține și a prelua date de pe site-uri web, ceea ce nu este întotdeauna ușor din cauza naturii complexe și variate a tehnologiilor web.
În plus, multe site-uri web au măsuri de protecție pentru a preveni colectarea datelor, ceea ce face esențial pentru scrapers să negocieze mecanisme anti-scraping, conținut dinamic și structuri complicate ale site-ului.
În ciuda faptului că obiectivul de a obține informații utile pare rapid simplu, ajungerea acolo necesită depășirea mai multor bariere formidabile, solicitând abilități analitice și tehnice puternice.
Gestionarea conținutului dinamic
Conținutul dinamic, care se referă la informațiile paginii web care se actualizează în funcție de acțiunile utilizatorului sau de încărcările după vizualizarea inițială a paginii, reprezintă de obicei provocări pentru instrumentele de scraping web.
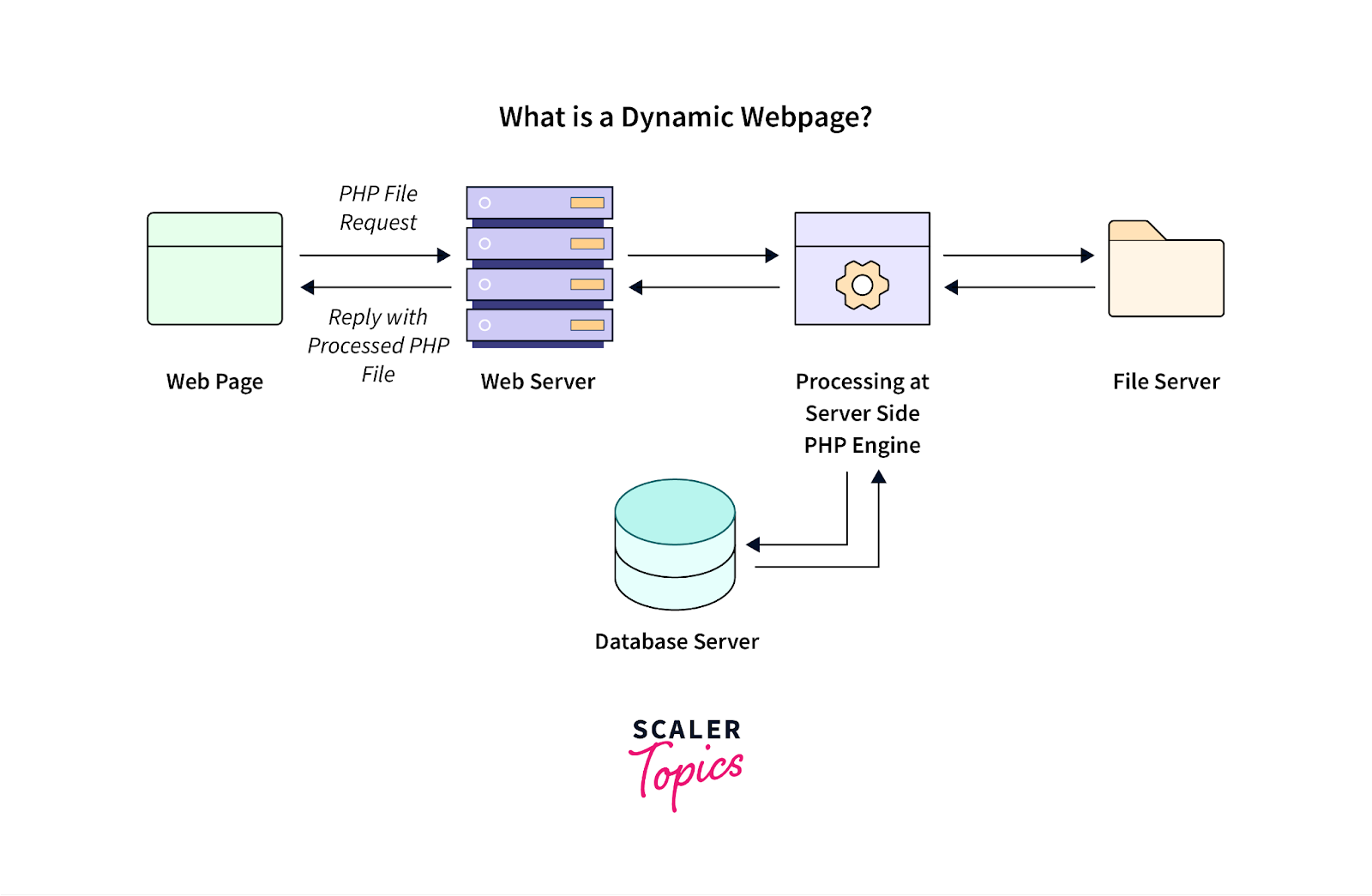
Sursa imagine: https://www.scaler.com/topics/php-tutorial/dynamic-website-in-php/
Un astfel de conținut dinamic este utilizat frecvent în aplicațiile web contemporane construite folosind cadre JavaScript. Pentru a gestiona și a extrage cu succes date dintr-un astfel de conținut generat dinamic, luați în considerare aceste bune practici:
- Luați în considerare utilizarea instrumentelor de automatizare web, cum ar fi Selenium, Puppeteer sau Playwright, care permit scraper-ului dvs. web să se comporte pe pagina web în mod similar cu un utilizator autentic.
- Implementați tehnici de manipulare WebSockets sau AJAX dacă site-ul web utilizează aceste tehnologii pentru a încărca conținut în mod dinamic.
- Așteptați ca elementele să se încarce utilizând așteptări explicite în codul dvs. de scraping pentru a vă asigura că conținutul este încărcat complet înainte de a încerca să-l scraping.
- Explorați folosind browsere fără cap care pot executa JavaScript și pot reda pagina completă, inclusiv conținutul încărcat dinamic.
Prin stăpânirea acestor strategii, scrapers pot extrage în mod eficient date chiar și de pe cele mai interactive și mai dinamice site-uri web în schimbare.
Tehnologii anti-răzuire
Este obișnuit ca dezvoltatorii web să pună în aplicare măsuri menite să prevină răpirea datelor neaprobate pentru a-și proteja site-urile web. Aceste măsuri pot pune provocări semnificative pentru web scrapers. Iată câteva metode și strategii pentru a naviga prin tehnologiile anti-răzuire:

Sursa imagine: https://kinsta.com/knowledgebase/what-is-web-scraping/
- Factoring dinamic : site-urile web pot genera conținut dinamic, ceea ce face mai dificilă prezicerea adreselor URL sau a structurilor HTML. Utilizați instrumente care pot executa JavaScript și gestiona solicitările AJAX.
- Blocare IP : solicitările frecvente de la același IP pot duce la blocări. Utilizați un grup de servere proxy pentru a roti IP-urile și a imita modelele de trafic uman.
- CAPTCHA-uri : acestea sunt concepute pentru a distinge între oameni și roboți. Aplicați serviciile de rezolvare CAPTCHA sau optați pentru introducerea manuală, dacă este posibil.
- Limitarea ratei : pentru a evita limitele ratei de declanșare, reduceți ratele de solicitare și implementați întârzieri aleatorii între solicitări.
- User-Agent : site-urile web ar putea bloca utilizatori-agenti scraper cunoscuți. Rotiți agenții de utilizare pentru a imita diferite browsere sau dispozitive.
Depășirea acestor provocări necesită o abordare sofisticată care respectă termenii și condițiile site-ului, accesând în același timp eficient datele necesare.
Se confruntă cu CAPTCHA și Honeypot Traps
Web scrapers întâmpină adesea provocări CAPTCHA menite să distingă utilizatorii umani de roboți. Pentru a depăși acest lucru necesită:
- Folosind servicii de rezolvare a CAPTCHA care valorifică capabilitățile umane sau AI.
- Implementarea întârzierilor și randomizarea solicitărilor pentru a imita comportamentul uman.
Pentru capcanele honeypot, care sunt invizibile pentru utilizatori, dar capcane scripturi automate:
- Inspectați cu atenție codul site-ului web pentru a evita interacțiunea cu link-uri ascunse.
- Folosind practici de răzuire mai puțin agresive pentru a rămâne sub radar.
Dezvoltatorii trebuie să echilibreze din punct de vedere etic eficacitatea cu respectul pentru termenii site-ului web și experiența utilizatorului.
Eficiența răzuirii și optimizarea vitezei
Procesele de web scraping pot fi îmbunătățite prin optimizarea atât a eficienței, cât și a vitezei. Pentru a depăși provocările din acest domeniu:
- Utilizați multi-threading pentru a permite extragerea simultană a datelor, crescând debitul.
- Folosiți browserele fără cap pentru o execuție mai rapidă, eliminând încărcarea inutilă a conținutului grafic.
- Optimizați codul de scraping pentru a fi executat cu o latență minimă.
- Implementați limitarea corespunzătoare a cererilor pentru a preveni interzicerea IP-ului, menținând în același timp un ritm stabil.
- Memorați în cache conținutul static pentru a evita descărcările repetate, economisind lățimea de bandă și timpul.
- Folosiți tehnici de programare asincronă pentru a optimiza operațiunile I/O ale rețelei.
- Alegeți selectoare eficiente și biblioteci de analiză pentru a reduce costul general al manipulării DOM.
Prin încorporarea acestor strategii, scraper-urile web pot obține performanțe robuste cu sughițuri operaționale minime.

Extragerea și analizarea datelor
Web scraping necesită extragerea și analizarea precisă a datelor, prezentând provocări distincte. Iată modalități de a le aborda:
- Utilizați biblioteci robuste precum BeautifulSoup sau Scrapy, care pot gestiona diferite structuri HTML.
- Implementați expresii regulate cu precauție pentru a viza modele specifice cu precizie.
- Folosiți instrumente de automatizare a browserului, cum ar fi Selenium, pentru a interacționa cu site-uri web cu JavaScript, asigurându-vă că datele sunt redate înainte de extragere.
- Utilizați selectoare XPath sau CSS pentru identificarea precisă a elementelor de date din DOM.
- Gestionați paginarea și derularea infinită prin identificarea și manipularea mecanismului care încarcă conținut nou (de exemplu, actualizarea parametrilor URL sau gestionarea apelurilor AJAX).
Stăpânirea artei Web Scraping
Web scraping este o abilitate neprețuită în lumea bazată pe date. Depășirea provocărilor tehnice, de la conținut dinamic la detectarea botului, necesită perseverență și adaptabilitate. Scraping web de succes implică o combinație a acestor abordări:
- Implementați accesarea cu crawlere inteligentă pentru a respecta resursele site-ului și pentru a naviga fără detectare.
- Utilizați analiza avansată pentru a gestiona conținutul dinamic, asigurându-vă că extragerea datelor este robustă împotriva modificărilor.
- Folosiți strategic servicii de rezolvare a CAPTCHA pentru a menține accesul fără a întrerupe fluxul de date.
- Gestionați cu atenție adresele IP și solicitați anteturi pentru a ascunde activitățile de scraping.
- Gestionați modificările structurii site-ului web prin actualizarea de rutină a scripturilor de analiză.
Prin stăpânirea acestor tehnici, se poate naviga cu abilități în complexitatea accesării cu crawlere pe web și poate debloca depozite vaste de date valoroase.
Gestionarea proiectelor de răzuire la scară largă
Proiectele de web scraping la scară largă necesită un management robust pentru a asigura eficiența și conformitatea. Parteneriatul cu furnizorii de servicii de web scraping oferă mai multe avantaje:

Încredințarea proiectelor de scraping către profesioniști poate optimiza rezultatele și poate minimiza solicitarea tehnică a echipei dumneavoastră interne.
Întrebări frecvente
Care sunt limitările web scraping?
Web scraping se confruntă cu anumite constrângeri pe care trebuie să le ia în considerare înainte de a o încorpora în operațiunile lor. Din punct de vedere legal, unele site-uri web interzic scrapingul prin termeni și condiții sau fișiere robot.txt; ignorarea acestor restricții poate duce la consecințe grave.
Din punct de vedere tehnic, site-urile web pot implementa contramăsuri împotriva scraping-urilor, cum ar fi CAPTCHA-urile, blocurile IP și honey pots, prevenind astfel accesul neautorizat. Precizia datelor extrase poate deveni, de asemenea, o problemă din cauza redării dinamice și a surselor actualizate frecvent. În cele din urmă, web scraping necesită cunoștințe tehnice, investiții în resurse și efort continuu - prezentând provocări, în special pentru persoanele netehnice.
De ce este răzuirea datelor o problemă?
Problemele apar în principal atunci când scraping-ul de date are loc fără permisiunile necesare sau conduită etică. Extragerea informațiilor confidențiale încalcă normele de confidențialitate și încalcă statutele concepute pentru a proteja interesele individuale.
Utilizarea excesivă a tulpinilor de scraping vizează serverele, impactând negativ performanța și disponibilitatea. Furtul de proprietate intelectuală constituie încă o preocupare care decurge din răzuirea ilegală din cauza posibilelor procese de încălcare a drepturilor de autor inițiate de părțile vătămate.
Prin urmare, respectarea prevederilor politicii, respectarea standardelor etice și căutarea consimțământului oriunde este necesar rămâne crucială în timpul îndeplinirii sarcinilor de scraping a datelor.
De ce web scraping poate fi inexact?
Web scraping, care presupune extragerea automată a datelor de pe site-uri web prin intermediul unui software specializat, nu garantează acuratețea completă din cauza diferiților factori. De exemplu, modificările în structura site-ului web ar putea cauza funcționarea defectuoasă a instrumentului scraper sau captarea informațiilor eronate.
În plus, anumite site-uri web implementează măsuri anti-scraping precum teste CAPTCHA, blocări IP sau redare JavaScript, ceea ce duce la pierderea sau distorsionarea datelor. Ocazional, neglijările dezvoltatorilor în timpul creării contribuie și la rezultate suboptime.
Cu toate acestea, parteneriatul cu furnizori de servicii de scraping web competenți poate spori precizia, deoarece aceștia aduc know-how-ul și activele necesare pentru a construi scraper-uri rezistente și agile, capabile să mențină niveluri ridicate de precizie, în ciuda schimbării aspectului site-ului. Experți calificați testează și validează aceste răzuitoare cu meticulozitate înainte de implementare, asigurând corectitudinea pe tot parcursul procesului de extracție.
Scrapingul web este obositor?
Într-adevăr, implicarea în activități de web scraping se poate dovedi laborioasă și solicitantă, în special pentru cei care nu au experiență în codificare sau înțelegere a platformelor digitale. Astfel de sarcini necesită crearea de coduri la comandă, rectificarea scraper-urilor defecte, administrarea arhitecturilor de server și ținerea la curent cu modificările care apar pe site-urile web vizate - toate necesitând abilități tehnice considerabile alături de investiții substanțiale în ceea ce privește cheltuiala de timp.
Extinderea dincolo de întreprinderile de bază de web scraping devine progresiv complicată, având în vedere respectarea reglementărilor, gestionarea lățimii de bandă și implementarea sistemelor de calcul distribuite.
În schimb, optarea pentru servicii profesionale de web scraping reduce substanțial sarcinile asociate prin oferte gata făcute concepute în funcție de cerințele specifice utilizatorului. În consecință, clienții se concentrează în primul rând pe valorificarea datelor culese, în timp ce lasă logistica de colectare echipelor dedicate formate din dezvoltatori calificați și specialiști IT responsabili de optimizarea sistemului, alocarea resurselor și soluționarea întrebărilor legale, reducând astfel considerabil oboseala generală legată de inițiativele de scraping web.