
Python Web Crawler – Tutorial pas cu pas
Publicat: 2023-12-07Crawlerele web sunt instrumente fascinante în lumea culegerii de date și web scraping. Acestea automatizează procesul de navigare pe web pentru a colecta date, care pot fi utilizate în diverse scopuri, cum ar fi indexarea motoarelor de căutare, extragerea datelor sau analiza competitivă. În acest tutorial, ne vom porni într-o călătorie informativă pentru a construi un crawler web de bază folosind Python, un limbaj cunoscut pentru simplitatea și capabilitățile sale puternice în manipularea datelor web.
Python, cu ecosistemul său bogat de biblioteci, oferă o platformă excelentă pentru dezvoltarea crawlerelor web. Indiferent dacă sunteți un dezvoltator în devenire, un pasionat de date sau pur și simplu sunteți curios despre modul în care funcționează crawlerele web, acest ghid pas cu pas este conceput pentru a vă prezenta elementele de bază ale crawlerului web și pentru a vă dota cu abilitățile necesare pentru a vă crea propriul crawler. .
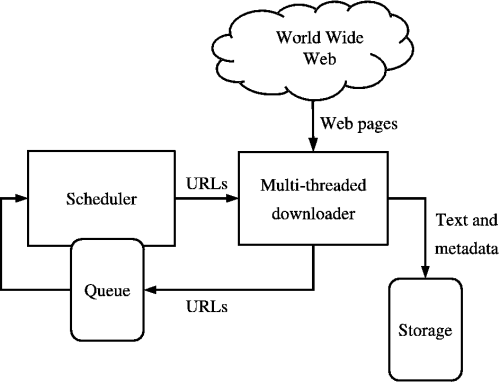
Sursa: https://medium.com/kariyertech/web-crawling-general-perspective-713971e9c659
Python Web Crawler - Cum să construiți un Web Crawler
Pasul 1: Înțelegerea elementelor de bază
Un web crawler, cunoscut și sub numele de spider, este un program care navighează pe World Wide Web într-o manieră metodică și automată. Pentru crawler-ul nostru, vom folosi Python datorită simplității și bibliotecilor puternice.
Pasul 2: Configurați-vă mediul
Instalați Python : Asigurați-vă că aveți instalat Python. Îl puteți descărca de pe python.org.
Instalați biblioteci : veți avea nevoie de solicitări pentru a face cereri HTTP și BeautifulSoup de la bs4 pentru analiza HTML. Instalați-le folosind pip:
solicitări de instalare pip pip install beautifulsoup4
Pasul 3: Scrieți Crawler de bază
Import biblioteci :
cereri de import de la bs4 import BeautifulSoup
Preluați o pagină web :
Aici, vom prelua conținutul unei pagini web. Înlocuiți „URL” cu pagina web pe care doriți să o accesați cu crawlere.
url = 'URL' response = requests.get(url) content = response.content
Analizați conținutul HTML :
supă = BeautifulSoup (conținut, 'html.parser')
Extrage informatii :
De exemplu, pentru a extrage toate hyperlinkurile, puteți face:
pentru link în soup.find_all('a'): print(link.get('href'))
Pasul 4: extindeți crawlerul
Gestionarea adreselor URL relative :
Utilizați urljoin pentru a gestiona adrese URL relative.
din urllib.parse import urljoin
Evitați accesarea cu crawlere a aceleiași pagini de două ori :
Mențineți un set de adrese URL vizitate pentru a evita redundanța.
Adăugarea întârzierilor :
Accesarea cu crawlere respectuoasă include întârzieri între solicitări. Folosește timpul.somn().
Pasul 5: Respectați Robots.txt
Asigurați-vă că crawler-ul dvs. respectă fișierul robots.txt al site-urilor web, care indică ce părți ale site-ului nu trebuie accesate cu crawlere.
Pasul 6: Gestionarea erorilor
Implementați blocuri try-except pentru a gestiona potențialele erori, cum ar fi expirarea timpului de conexiune sau accesul refuzat.
Pasul 7: Mergeți mai adânc
Vă puteți îmbunătăți crawler-ul pentru a gestiona sarcini mai complexe, cum ar fi trimiterile de formulare sau redarea JavaScript. Pentru site-urile web care utilizează JavaScript, luați în considerare utilizarea Selenium.
Pasul 8: Stocați datele
Decideți cum să stocați datele pe care le-ați accesat cu crawlere. Opțiunile includ fișiere simple, baze de date sau chiar trimiterea directă a datelor către un server.
Pasul 9: Fii etic
- Nu supraîncărcați serverele; adăugați întârzieri la solicitările dvs.
- Urmați termenii și condițiile site-ului.
- Nu răzuiți și nu stocați date personale fără permisiune.
Blocarea este o provocare obișnuită atunci când accesați cu crawlere web, mai ales când aveți de-a face cu site-uri web care au măsuri de detectare și blocare a accesului automat. Iată câteva strategii și considerații pentru a vă ajuta să navigați în această problemă în Python:
Înțelegerea de ce ești blocat
Cereri frecvente: solicitările rapide și repetate de la același IP pot declanșa blocarea.
Modele non-umane: roboții manifestă adesea un comportament diferit de tiparele de navigare umane, cum ar fi accesarea paginilor prea rapid sau într-o secvență previzibilă.
Gestionarea greșită a antetelor: anteturile HTTP lipsă sau incorecte pot face cererile dvs. să pară suspecte.
Ignorarea robots.txt: nerespectarea directivelor din fișierul robots.txt al unui site poate duce la blocări.
Strategii pentru a evita blocarea
Respectați robots.txt : verificați și respectați întotdeauna fișierul robots.txt al site-ului web. Este o practică etică și poate preveni blocarea inutilă.
Agenți utilizatori rotativi : site-urile web vă pot identifica prin intermediul agentului dvs. de utilizator. Prin rotirea acestuia, reduceți riscul de a fi semnalat ca bot. Utilizați biblioteca fake_useragent pentru a implementa acest lucru.
din fake_useragent import UserAgent ua = UserAgent() anteturi = {'User-Agent': ua.random}

Adăugarea de întârzieri : implementarea unei întârzieri între solicitări poate imita comportamentul uman. Utilizați time.sleep() pentru a adăuga o întârziere aleatorie sau fixă.
import time time.sleep(3) # Așteaptă 3 secunde
Rotație IP : dacă este posibil, utilizați servicii proxy pentru a vă roti adresa IP. Există atât servicii gratuite, cât și cu plată disponibile pentru aceasta.
Utilizarea sesiunilor : un obiect requests.Session în Python poate ajuta la menținerea unei conexiuni coerente și la partajarea antetelor, cookie-urilor etc., între solicitări, făcând crawler-ul să pară mai mult ca o sesiune obișnuită de browser.
cu requests.Session() ca sesiune: session.headers = {'User-Agent': ua.random} răspuns = session.get(url)
Gestionarea JavaScript : unele site-uri se bazează în mare măsură pe JavaScript pentru a încărca conținut. Instrumente precum Selenium sau Puppeteer pot imita un browser real, inclusiv redarea JavaScript.
Gestionarea erorilor : implementați o gestionare robustă a erorilor pentru a gestiona și a răspunde la blocaje sau alte probleme cu grație.
Considerații etice
- Respectați întotdeauna termenii și condițiile unui site web. Dacă un site interzice în mod explicit web scraping, cel mai bine este să se conformeze.
- Fiți atenți la impactul pe care crawler-ul dvs. îl are asupra resurselor site-ului. Supraîncărcarea unui server poate cauza probleme proprietarului site-ului.
Tehnici avansate
- Web Scraping Frameworks : Luați în considerare utilizarea cadrelor precum Scrapy, care au funcții încorporate pentru a gestiona diverse probleme de crawling.
- Servicii de rezolvare CAPTCHA : pentru site-urile cu provocări CAPTCHA, există servicii care pot rezolva CAPTCHA, deși utilizarea lor ridică preocupări etice.
Cele mai bune practici de crawling pe Web în Python
Angajarea în activități de crawling pe web necesită un echilibru între eficiența tehnică și responsabilitatea etică. Când utilizați Python pentru accesarea cu crawlere pe web, este important să respectați cele mai bune practici care respectă datele și site-urile web de la care provine. Iată câteva considerații cheie și cele mai bune practici pentru accesarea cu crawlere web în Python:
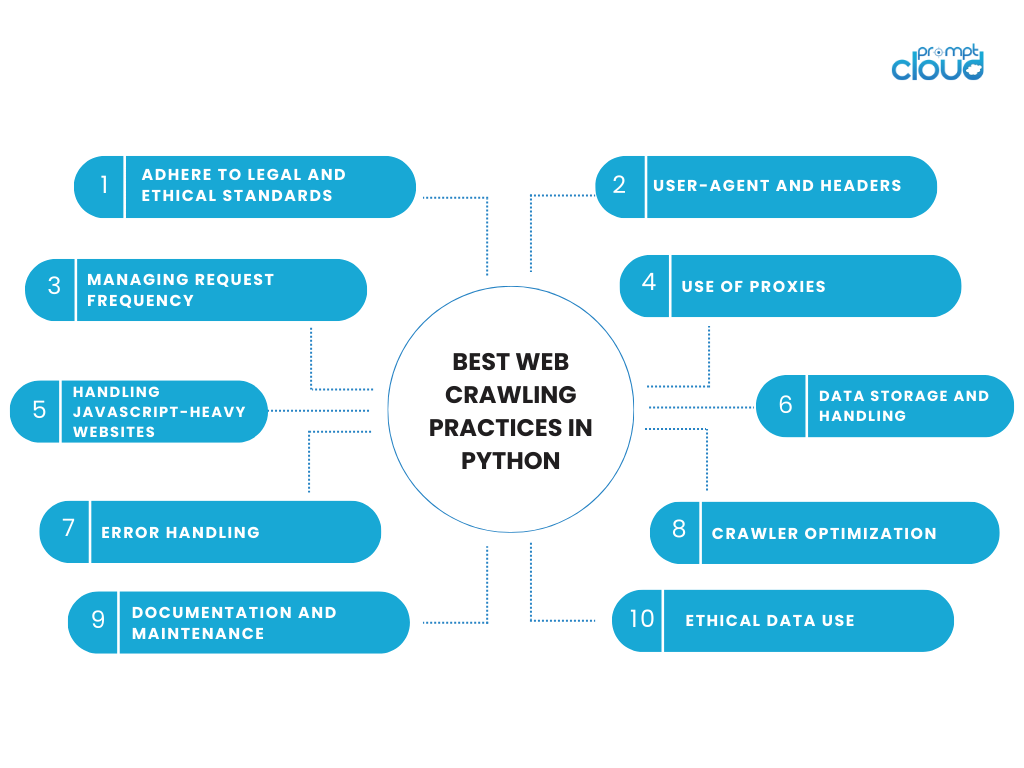
Respectați standardele legale și etice
- Respectați robots.txt: verificați întotdeauna fișierul robots.txt al site-ului web. Acest fișier prezintă zonele site-ului pe care proprietarul site-ului preferă să nu fie accesate cu crawlere.
- Urmați Termenii și condițiile: multe site-uri web includ clauze despre web scraping în termenii și condițiile lor. Respectarea acestor termeni este atât etic, cât și prudent din punct de vedere juridic.
- Evitați supraîncărcarea serverelor: faceți cereri într-un ritm rezonabil pentru a evita încărcarea excesivă a serverului site-ului web.
User-Agent și anteturi
- Identificați-vă: utilizați un șir user-agent care include informațiile dvs. de contact sau scopul accesării cu crawlere. Această transparență poate genera încredere.
- Utilizați în mod corespunzător anteturile: anteturile HTTP bine configurate pot reduce probabilitatea de a fi blocate. Ele pot include informații precum user-agent, accept-language etc.
Gestionarea frecvenței solicitărilor
- Adăugați întârzieri: implementați o întârziere între solicitări pentru a imita modelele de navigare umane. Utilizați funcția time.sleep() de la Python.
- Limitarea ratei: fiți conștienți de câte solicitări trimiteți către un site web într-un anumit interval de timp.
Utilizarea proxy-urilor
- Rotația IP: Utilizarea proxy-urilor pentru a vă roti adresa IP poate ajuta la evitarea blocării bazate pe IP, dar trebuie făcută în mod responsabil și etic.
Gestionarea site-urilor web cu JavaScript-heavy
- Conținut dinamic: pentru site-urile care încarcă conținut dinamic cu JavaScript, instrumente precum Selenium sau Puppeteer (în combinație cu Pyppeteer pentru Python) pot reda paginile ca un browser.
Stocarea și manipularea datelor
- Stocarea datelor: stocați datele accesate cu crawlere în mod responsabil, ținând cont de legile și reglementările privind confidențialitatea datelor.
- Minimizați extragerea datelor: extrageți numai datele de care aveți nevoie. Evitați să colectați informații personale sau sensibile, cu excepția cazului în care este absolut necesar și legal.
Eroare de manipulare
- Gestionare robustă a erorilor: implementați o gestionare completă a erorilor pentru a gestiona probleme precum expirarea timpului, erorile de server sau conținutul care nu se încarcă.
Optimizare crawler
- Scalabilitate: proiectați-vă crawler-ul pentru a face față unei creșteri de scară, atât în ceea ce privește numărul de pagini accesate cu crawlere, cât și cantitatea de date procesate.
- Eficiență: optimizați-vă codul pentru eficiență. Codul eficient reduce sarcina atât pe sistemul dumneavoastră, cât și pe serverul țintă.
Documentare și întreținere
- Păstrați documentația: documentați-vă codul și logica de accesare cu crawlere pentru referințe și întreținere viitoare.
- Actualizări regulate: mențineți codul de accesare cu crawlere actualizat, mai ales dacă structura site-ului țintă se modifică.
Utilizarea etică a datelor
- Utilizare etică: utilizați datele pe care le-ați colectat într-o manieră etică, respectând confidențialitatea utilizatorilor și normele de utilizare a datelor.
În concluzie
În încheierea explorării noastre privind construirea unui crawler web în Python, am parcurs complexitățile colectării automate de date și considerentele etice care vin odată cu aceasta. Acest efort nu numai că ne îmbunătățește abilitățile tehnice, dar ne aprofundează și înțelegerea despre gestionarea responsabilă a datelor în vastul peisaj digital.
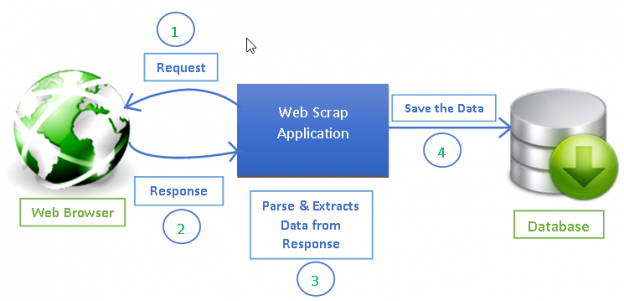
Sursa: https://www.datacamp.com/tutorial/making-web-crawlers-scrapy-python
Cu toate acestea, crearea și întreținerea unui crawler web poate fi o sarcină complexă și consumatoare de timp, în special pentru companiile cu nevoi specifice de date la scară largă. Aici intră în joc serviciile personalizate de web scraping ale PromptCloud. Dacă sunteți în căutarea unei soluții adaptate, eficiente și etice pentru cerințele dvs. de date web, PromptCloud oferă o gamă largă de servicii pentru a se potrivi nevoilor dvs. unice. De la gestionarea site-urilor web complexe până la furnizarea de date curate și structurate, acestea se asigură că proiectele dvs. de web scraping sunt fără probleme și aliniate cu obiectivele dvs. de afaceri.
Pentru companiile și persoanele care nu au timpul sau expertiza tehnică pentru a-și dezvolta și gestiona propriile crawler-uri web, externalizarea acestei sarcini către experți precum PromptCloud poate fi o schimbare. Serviciile lor nu numai că economisesc timp și resurse, dar vă asigură și că obțineți cele mai precise și relevante date, toate respectând standardele legale și etice.
Doriți să aflați mai multe despre modul în care PromptCloud poate răspunde nevoilor dvs. specifice de date? Contactați-i la sales@promptcloud.com pentru mai multe informații și pentru a discuta despre modul în care soluțiile lor personalizate de web scraping vă pot ajuta să vă propulsați afacerea.
În lumea dinamică a datelor web, a avea un partener de încredere precum PromptCloud vă poate împuternici afacerea, oferindu-vă avantaj în luarea deciziilor bazate pe date. Amintiți-vă, în domeniul colectării și analizei datelor, partenerul potrivit face toată diferența.
Vânătoare de date fericită!