
Selectarea și configurarea motoarelor de inferență pentru LLM
Publicat: 2024-04-02Introducere în motoarele de inferență
Există multe tehnici de optimizare dezvoltate pentru a atenua ineficiențele care apar în diferitele etape ale procesului de inferență. Este dificil să scalați inferența la scară cu ajutorul tehnicilor/transformatorului vanilie. Motoarele de inferență împachetează optimizările într-un singur pachet și ne ușurează procesul de inferență.
Pentru un set foarte mic de teste ad-hoc sau referințe rapide, putem folosi codul transformatorului vanilie pentru a face inferența.
Peisajul motoarelor de inferență evoluează rapid, deoarece avem mai multe opțiuni, este important să testăm și să enumeram cele mai bune dintre cele mai bune pentru anumite cazuri de utilizare. Mai jos, sunt câteva experimente cu motoare de inferență pe care le-am făcut și motivele pentru care am aflat de ce a funcționat pentru cazul nostru.
Pentru modelul nostru Vicuna-7B reglat fin, am încercat
- TGI
- vLLM
- Afrodita
- Optimum-Nvidia
- PowerInfer
- LLAMACPP
- Ctranslate2
Am trecut prin pagina github și prin ghidul său de pornire rapidă pentru a configura aceste motoare, PowerInfer, LlaamaCPP, Ctranslate2 nu sunt foarte flexibili și nu acceptă multe tehnici de optimizare, cum ar fi loturi continue, atenție paginată și performanță sub egală în comparație cu alte motoare menționate. .
Pentru a obține un randament mai mare, motorul/serverul de inferență ar trebui să maximizeze memoria și capacitățile de calcul și atât clientul, cât și serverul trebuie să funcționeze într-un mod paralel/asincron de a servi cererile pentru a menține serverul mereu în funcțiune. După cum am menționat mai devreme, fără ajutorul tehnicilor de optimizare precum PagedAttention, Flash Attention, Continuous loturi, va duce întotdeauna la o performanță suboptimă.
TGI, vLLM și Aphrodite sunt candidați mai potriviți în acest sens și, făcând mai multe experimente menționate mai jos, am găsit configurația optimă pentru a strânge performanța maximă din inferență. Tehnici precum Locurile continue și atenția paginată sunt activate în mod implicit, decodificarea speculativă trebuie să fie activată manual în motorul de inferență pentru testele de mai jos.
Analiza comparativă a motoarelor de inferență
TGI
Pentru a folosi TGI, putem trece prin secțiunea „Începeți” a paginii github, aici docker este cel mai simplu mod de a configura și utiliza motorul TGI.
Argumente ale lansatorului de generare de text -> această listă în jos diferite setări pe care le putem folosi pe partea de server. Puține importante,
- –max-input-length : determină lungimea maximă a intrării în model, aceasta necesită modificări în majoritatea cazurilor, deoarece implicit este 1024.
- –max-total-jetoane: max total de jetoane, adică lungimea jetonului de intrare + ieșire.
- –speculate, –quantiz, –max-concurrent-requests -> implicit este doar 128, ceea ce este evident mai mic.
Pentru a începe un model local reglat fin,
docker run –gpus device=1 –shm-size 1g -p 9091:80 -v /path/to/fine_tuned_v1:/model ghcr.io/huggingface/text-generation-inference:1.4.4 –model-id /model – dtype float16 –num-shard 1 –max-input-length 3600 –max-total-tokens 4000 –speculate 2
Pentru a porni un model de la hub,
model=”lmsys/vicuna-7b-v1.5″; volum=$PWD/date; token="<hf_token>"; docker run –gpus all –shm-size 1g -e HUGGING_FACE_HUB_TOKEN=$token -p 9091:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:1.4.4 –model-id $model – dtype float16 –num-shard 1 –max-input-length 3600 –max-total-tokens 4000 –speculate 2
Puteți cere chatGPT să explice comanda de mai sus pentru o înțelegere mai detaliată. Aici pornim serverul de inferență la portul 9091. Și putem folosi un client în orice limbă pentru a posta o solicitare pe server. Text Generation Inference API -> menționează toate punctele finale și parametrii de sarcină utilă pentru solicitare.
De exemplu
sarcină utilă=”<prompt aici>”
curl -XPOST „0.0.0.0:9091/generate” -H „Content-Type: application/json” -d „{“inputs”: $payload, „parameters”: {“max_new_tokens”: 400,”do_sample”:false ,”best_of”: null,”repetition_penalty”: 1,”return_full_text”: false,”seed”: null,”stop_sequences”: null,”temperature”: 0,1,”top_k”: 100,”top_p”: 0,3,” truncate”: null,”typical_p”: null,”watermark”: false,”decoder_input_details”: false}}”
Puține observații,
- Latența crește cu max-token-tokens, ceea ce este evident că, dacă procesăm text lung, atunci timpul general va crește.
- Specularea ajută, dar depinde de cazul de utilizare și de distribuția de intrare-ieșire.
- Cuantizarea Eetq ajută cel mai mult la creșterea debitului.
- Dacă aveți un GPU multiplu, rulați 1 API pe fiecare GPU și având aceste API-uri GPU multiple în spatele unui echilibrator de încărcare are ca rezultat un debit mai mare decât fragmentarea de către TGI însuși.
vLLM
Pentru a porni un server vLLM, putem folosi un server/docker REST API compatibil OpenAI. Este foarte simplu să începeți, urmați Deploying with Docker — vLLM, dacă aveți de gând să utilizați un model local, apoi atașați volumul și utilizați calea ca nume de model,
docker run –runtime nvidia –gpus device=1 –shm-size 1g -v /path/to/fine_tuned_v1:/model -v ~/.cache/ -p 8000:8000 –ipc=host vllm/vllm-openai:latest – model/model
Mai sus va porni un server vLLM pe portul 8000 menționat, ca întotdeauna vă puteți juca cu argumente.
Faceți o cerere de postare cu,
„`cochilie
sarcină utilă=”<prompt aici>”
curl -XPOST -m 1200 „0.0.0.0:8000/v1/completions” -H „Content-Type: application/json” -d „{“prompt”: $payload,”model”:”/model” ,”max_tokens ”: 400,”top_p”: 0,3, “top_k”: 100, „temperatura”: 0,1}”
„`
Afrodita
„`cochilie
pip install aphrodite-engine
python -m aphrodite.endpoints.openai.api_server –model PygmalionAI/pygmalion-2-7b
„`
Sau
„`
docker run -v /path/to/fine_tuned_v1:/model -d -e MODEL_NAME=”/model” -p 2242:7860 –gpus device=1 –ipc host alpindale/aphrodite-engine
„`

Aphrodite oferă atât instalarea pip, cât și instalarea docker, așa cum este menționat în secțiunea de pornire. Docker este, în general, relativ mai ușor de rotit și testat. Opțiunile de utilizare, opțiunile de server ne ajută să facem cereri.
- Aphrodite și vLLM folosesc ambele încărcături utile bazate pe server openAI, astfel încât să puteți verifica documentația acestuia.
- Am încercat deepspeed-mii, deoarece este în stare de tranziție (când am încercat) de la baza de cod moștenită la noua bază de cod, nu pare fiabil și ușor de utilizat.
- Optimum-NVIDIA nu acceptă alte optimizări majore și are ca rezultat o performanță suboptimă, link ref.
- S-a adăugat un esențial, codul pe care l-am folosit pentru a face cererile paralele ad-hoc.
Metrici și măsurători
Vrem să încercăm și să găsim:
- Optimal nr. de fire pentru serverul client/motor de inferență.
- Cum crește debitul în raport cu creșterea memoriei
- Cum crește debitul față de nucleele tensorului.
- Efectul firelor de execuție vs solicitări paralele de către client.
Un mod foarte de bază de a observa utilizarea este să îl urmăriți prin intermediul linux utils nvidia-smi, nvtop, aceasta ne va spune memoria ocupată, utilizarea de calcul, rata de transfer de date etc.
O altă modalitate este să profilați procesul folosind GPU cu nsys.
| S.Nr | GPU | memorie vRAM | Motor de inferență | Fire | Timp (e) | Specula |
| 1 | A6000 | 48 /48GB | TGI | 24 | 664 | – |
| 2 | A6000 | 48 /48GB | TGI | 64 | 561 | – |
| 3 | A6000 | 48 /48GB | TGI | 128 | 554 | – |
| 4 | A6000 | 48 /48GB | TGI | 256 | 568 | – |
Pe baza experimentelor de mai sus, 128/256 fire este mai bună decât numărul mai mic de fire și peste 256 overhead începe să contribuie la reducerea debitului. Se constată că aceasta depinde de CPU și GPU și are nevoie de propriul experiment. | ||||||
| 5 | A6000 | 48 /48GB | TGI | 128 | 596 | 2 |
| 6 | A6000 | 48 /48GB | TGI | 128 | 945 | 8 |
Valoarea speculată mai mare provoacă mai multe respingeri pentru modelul nostru reglat fin și reducând astfel debitul. 1 / 2, deoarece valoarea speculată este în regulă, aceasta este supusă modelului și nu este garantat să funcționeze la fel în toate cazurile de utilizare. Dar concluzia este că decodificarea speculativă îmbunătățește debitul. | ||||||
| 7 | 3090 | 24/24 GB | TGI | 128 | 741 | 2 |
| 7 | 4090 | 24/24 GB | TGI | 128 | 481 | 2 |
4090 are, chiar dacă mai puțină vRAM în comparație cu A6000, depășește datorită numărului mai mare de nuclee tensor și vitezei lățimii de bandă a memoriei. | ||||||
| 8 | A6000 | 24/48 GB | TGI | 128 | 707 | 2 |
| 9 | A6000 | 2 x 24/48 GB | TGI | 128 | 1205 | 2 |
Configurarea și configurarea TGI pentru un randament ridicat
Configurați solicitarea asincronă într-un limbaj de scripting la alegere, cum ar fi python/ruby și folosind același fișier pentru configurare, am găsit:
- Timpul necesar crește față de lungimea maximă de ieșire a generării secvenței.
- Firele de execuție 128/ 256 pe client și server sunt mai bune decât 24, 64, 512. Când se utilizează fire de execuție inferioare, calculul este subutilizat și dincolo de un prag precum 128, suprasarcina devine mai mare și astfel debitul s-a redus.
- Există o îmbunătățire cu 6% atunci când treceți de la cererile asincrone la cererile paralele folosind „GNU paralel” în loc de threading în limbi precum Go, Python/Ruby.
- 4090 are un randament cu 12% mai mare decât A6000. 4090 are, chiar dacă mai puțină vRAM în comparație cu A6000, depășește datorită numărului mai mare de nuclee tensor și vitezei lățimii de bandă a memoriei.
- Deoarece A6000 are 48 GB vRAM, pentru a concluziona dacă RAM suplimentară ajută la îmbunătățirea debitului sau nu, am încercat să folosim fracții de memorie GPU în experimentul 8 din tabel, vedem că RAM suplimentară ajută la îmbunătățire, dar nu liniar. De asemenea, atunci când s-a încercat împărțirea, adică găzduiește 2 API pe același GPU folosind jumătate de memorie pentru fiecare API, se comportă ca 2 API-uri care rulează secvențial, în loc să accepte cereri în paralel.
Observații și metrici
Mai jos sunt grafice pentru unele experimente și timpul necesar pentru a finaliza un set de intrări fixe, mai mic timpul necesar este mai bine.
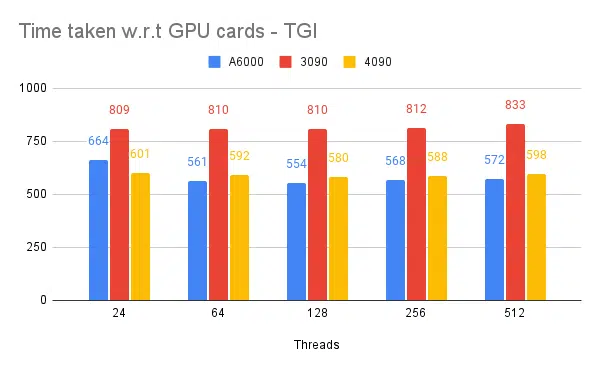
- Se menționează firele din partea clientului. Pe partea de server trebuie să menționăm la pornirea motorului de inferență.
Testare speculată:

Testarea mai multor motoare de inferență:
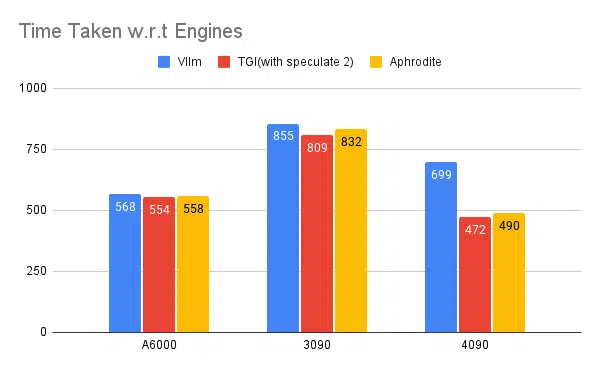
Același tip de experimente făcute cu alte motoare precum vLLM și Aphrodite observăm rezultate similare, la momentul scrierii acestui articol, vLLM și Aphrodite nu acceptă încă decodarea speculativă, ceea ce ne lasă să alegem TGI, deoarece oferă un randament mai mare decât restul datorat. la decodificarea speculativă.
În plus, puteți configura profilere GPU pentru a îmbunătăți observabilitatea, ajutând la identificarea zonelor cu utilizare excesivă a resurselor și optimizând performanța. Citiți mai departe: Instrumente pentru dezvoltatori Nvidia Nsight - Max Katz
Concluzie
Vedem că peisajul generării de inferențe evoluează în mod constant, iar îmbunătățirea ratei de transfer în LLM necesită o bună înțelegere a GPU-ului, a parametrilor de performanță, a tehnicilor de optimizare și a provocărilor asociate sarcinilor de generare a textului. Acest lucru ajută la alegerea instrumentelor potrivite pentru muncă. Înțelegând elementele interne ale GPU-ului și modul în care acestea corespund inferenței LLM, cum ar fi exploatarea nucleelor tensorului și maximizarea lățimii de bandă a memoriei, dezvoltatorii pot alege GPU-ul eficient din punct de vedere al costurilor și pot optimiza performanța în mod eficient.
Diferitele carduri GPU oferă capacități diferite, iar înțelegerea diferențelor este crucială pentru selectarea celui mai potrivit hardware pentru anumite sarcini. Tehnici precum dotarea continuă, atenția paginată, fuziunea nucleului și atenția flash oferă soluții promițătoare pentru a depăși provocările apărute și pentru a îmbunătăți eficiența. TGI pare cea mai bună alegere pentru cazul nostru de utilizare pe baza experimentelor și a rezultatelor pe care le obținem.
Citiți și alte articole legate de modelul lingvistic mare:
Înțelegerea arhitecturii GPU pentru optimizarea inferenței LLM
Tehnici avansate pentru îmbunătățirea randamentului LLM