
Ghid pas cu pas pentru a construi un crawler web
Publicat: 2023-12-05În tapiseria complicată a internetului, unde informațiile sunt împrăștiate pe nenumărate site-uri web, crawlerele web apar ca eroi necunoscuti, lucrând cu sârguință pentru a organiza, indexa și face accesibilă această bogăție de date. Acest articol se lansează într-o explorare a crawlerelor web, aruncând lumină asupra funcționării lor fundamentale, făcând distincție între accesarea cu crawlere web și scrapingul web și oferind informații practice, cum ar fi un ghid pas cu pas pentru crearea unui crawler web simplu bazat pe Python. Pe măsură ce aprofundăm, vom descoperi capabilitățile instrumentelor avansate precum Scrapy și vom descoperi cum PromptCloud ridică accesul cu crawlere web la o scară industrială.
Ce este un web crawler
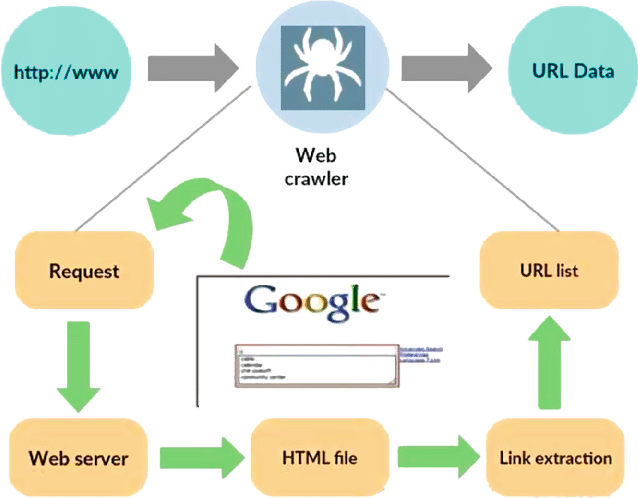
Sursa: https://www.researchgate.net/figure/Working-model-of-web-crawler_fig1_316089973
Un web crawler, cunoscut și sub numele de spider sau bot, este un program specializat conceput pentru a naviga sistematic și autonom în vasta întindere a World Wide Web. Funcția sa principală este de a traversa site-uri web, de a colecta date și de a indexa informații pentru diverse scopuri, cum ar fi optimizarea motoarelor de căutare, indexarea conținutului sau extragerea datelor.
În esență, un crawler web imită acțiunile unui utilizator uman, dar într-un ritm mult mai rapid și mai eficient. Își începe călătoria de la un punct de plecare desemnat, adesea denumit URL de bază, apoi urmează hyperlinkuri de la o pagină web la alta. Acest proces de urmărire a linkurilor este recursiv, permițând crawler-ului să exploreze o parte semnificativă a internetului.
Pe măsură ce crawler-ul vizitează pagini web, extrage și stochează sistematic date relevante, care pot include text, imagini, metadate și multe altele. Datele extrase sunt apoi organizate și indexate, facilitând ca motoarele de căutare să preia și să prezinte informații relevante utilizatorilor atunci când sunt interogați.
Crawlerele web joacă un rol esențial în funcționalitatea motoarelor de căutare precum Google, Bing și Yahoo. Prin accesarea cu crawlere continuă și sistematică pe web, aceștia se asigură că indexurile motoarelor de căutare sunt actualizate, oferind utilizatorilor rezultate de căutare exacte și relevante. În plus, crawlerele web sunt utilizate în diverse alte aplicații, inclusiv agregarea de conținut, monitorizarea site-urilor web și extragerea datelor.
Eficacitatea unui crawler web se bazează pe capacitatea sa de a naviga în diverse structuri de site-uri web, de a gestiona conținutul dinamic și de a respecta regulile stabilite de site-uri web prin fișierul robots.txt, care subliniază ce porțiuni ale unui site pot fi accesate cu crawlere. Înțelegerea modului în care funcționează crawlerele web este fundamentală pentru a aprecia importanța acestora în a face vastul web de informații accesibil și organizat.
Cum funcționează crawlerele web
Crawlerele web, cunoscute și sub numele de păianjeni sau roboți, operează printr-un proces sistematic de navigare pe World Wide Web pentru a culege informații de pe site-uri web. Iată o prezentare generală a modului în care funcționează crawlerele web:
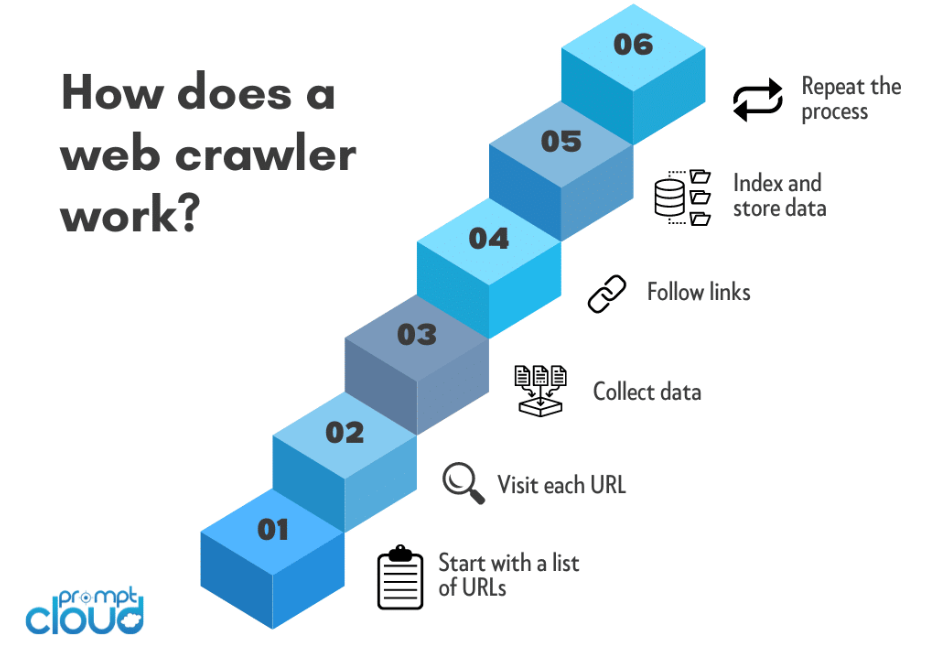
Selectarea URL de bază:
Procesul de accesare cu crawlere web începe de obicei cu o adresă URL de bază. Aceasta este pagina web sau site-ul web inițial de la care își începe călătoria crawler-ul.
Solicitare HTTP:
Crawler-ul trimite o solicitare HTTP către adresa URL de bază pentru a prelua conținutul HTML al paginii web. Această solicitare este similară cu solicitările făcute de browserele web la accesarea unui site web.
Analiza HTML:
Odată ce conținutul HTML este preluat, crawler-ul îl analizează pentru a extrage informații relevante. Aceasta implică descompunerea codului HTML într-un format structurat pe care crawler-ul îl poate naviga și analiza.
Extragere URL:
Crawler-ul identifică și extrage hyperlink-urile (URL-uri) prezente în conținutul HTML. Aceste adrese URL reprezintă linkuri către alte pagini pe care crawlerul le va vizita ulterior.
Coadă și programator:
Adresele URL extrase sunt adăugate la o coadă sau la un planificator. Coada asigură că crawler-ul vizitează adresele URL într-o anumită ordine, prioritând adesea adresele URL noi sau nevizitate.
Recursie:
Crawler-ul urmărește linkurile din coadă, repetând procesul de trimitere a solicitărilor HTTP, analizând conținutul HTML și extragând noi adrese URL. Acest proces recursiv permite crawler-ului să navigheze prin mai multe straturi de pagini web.
Extragerea datelor:
Pe măsură ce crawler-ul traversează web, extrage date relevante din fiecare pagină vizitată. Tipul de date extrase depinde de scopul crawlerului și poate include text, imagini, metadate sau alt conținut specific.
Indexarea conținutului:
Datele colectate sunt organizate și indexate. Indexarea implică crearea unei baze de date structurate care facilitează căutarea, preluarea și prezentarea informațiilor atunci când utilizatorii trimit interogări.
Respectând Robots.txt:
Crawlerele web respectă de obicei regulile specificate în fișierul robots.txt al unui site web. Acest fișier oferă instrucțiuni privind zonele site-ului care pot fi accesate cu crawlere și care ar trebui excluse.
Întârzieri de accesare cu crawlere și politețe:
Pentru a evita supraîncărcarea serverelor și cauzarea de întreruperi, crawlerele încorporează adesea mecanisme pentru întârzierea accesării cu crawlere și politețe. Aceste măsuri asigură că crawler-ul interacționează cu site-urile web într-o manieră respectuoasă și fără perturbări.
Crawlerele web navighează sistematic pe web, urmând link-uri, extragând date și creând un index organizat. Acest proces permite motoarele de căutare să ofere utilizatorilor rezultate precise și relevante pe baza interogărilor lor, făcând crawlerele web o componentă fundamentală a ecosistemului modern al internetului.

Web crawling vs. Web Scraping

Sursa: https://research.aimultiple.com/web-crawling-vs-web-scraping/
În timp ce web crawling și web scraping sunt adesea folosite în mod interschimbabil, ele servesc unor scopuri distincte. Crawling-ul web implică navigarea sistematică pe web pentru a indexa și a colecta informații, în timp ce web scraping se concentrează pe extragerea de date specifice din paginile web. În esență, accesarea cu crawlere web se referă la explorarea și maparea web-ului, în timp ce web scraping se referă la colectarea informațiilor vizate.
Construirea unui crawler web
Construirea unui crawler web simplu în Python implică mai mulți pași, de la configurarea mediului de dezvoltare până la codificarea logicii crawlerului. Mai jos este un ghid detaliat pentru a vă ajuta să creați un crawler web de bază folosind Python, utilizând biblioteca de solicitări pentru a face cereri HTTP și BeautifulSoup pentru analiza HTML.
Pasul 1: Configurați mediul
Asigurați-vă că aveți Python instalat pe sistemul dvs. Îl puteți descărca de pe python.org. În plus, va trebui să instalați bibliotecile necesare:
pip install requests beautifulsoup4
Pasul 2: importați biblioteci
Creați un nou fișier Python (de exemplu, simple_crawler.py) și importați bibliotecile necesare:
import requests from bs4 import BeautifulSoup
Pasul 3: Definiți funcția crawler
Creați o funcție care preia o adresă URL ca intrare, trimite o solicitare HTTP și extrage informații relevante din conținutul HTML:
def simple_crawler(url):
# Send HTTP request to the URL
response = requests.get(url)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Parse HTML content with BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Extract and print relevant information (modify as needed)
title = soup.title.text
print(f'Title: {title}')
# Additional data extraction and processing can be added here
else:
print(f'Error: Failed to fetch {url}')
Pasul 4: Testați crawlerul
Furnizați un exemplu de adresă URL și apelați funcția simple_crawler pentru a testa crawler-ul:
if __name__ == "__main__": sample_url = 'https://example.com' simple_crawler(sample_url)
Pasul 5: Rulați crawlerul
Executați scriptul Python în terminalul sau promptul de comandă:
python simple_crawler.py
Crawler-ul va prelua conținutul HTML al adresei URL furnizate, îl va analiza și va tipări titlul. Puteți extinde crawler-ul adăugând mai multe funcționalități pentru extragerea diferitelor tipuri de date.
Crawling web cu Scrapy
Crawling-ul web cu Scrapy deschide ușa către un cadru puternic și flexibil, conceput special pentru scraping web eficient și scalabil. Scrapy simplifică complexitatea construirii crawlerelor web, oferind un mediu structurat pentru crearea de păianjeni care pot naviga pe site-uri web, extrage date și le stochează într-o manieră sistematică. Iată o privire mai atentă asupra accesării cu crawlere web cu Scrapy:
Instalare:
Înainte de a începe, asigurați-vă că aveți Scrapy instalat. Il poti instala folosind:
pip install scrapy
Crearea unui proiect Scrapy:
Inițiază un proiect Scrapy:
Deschideți un terminal și navigați la directorul în care doriți să vă creați proiectul Scrapy. Rulați următoarea comandă:
scrapy startproject your_project_name
Aceasta creează o structură de bază a proiectului cu fișierele necesare.
Definiți păianjenul:
În directorul proiectului, navigați la folderul spiders și creați un fișier Python pentru spider. Definiți o clasă spider subclasând scrapy.Spider și furnizând detalii esențiale, cum ar fi numele, domeniile permise și adresele URL de pornire.
import scrapy
class YourSpider(scrapy.Spider):
name = 'your_spider'
allowed_domains = ['example.com']
start_urls = ['http://example.com']
def parse(self, response):
# Define parsing logic here
pass
Extragerea datelor:
Utilizarea selectoarelor:
Scrapy utilizează selectoare puternice pentru extragerea datelor din HTML. Puteți defini selectori în metoda de analiză a păianjenului pentru a captura elemente specifice.
def parse(self, response):
title = response.css('title::text').get()
yield {'title': title}
Acest exemplu extrage conținutul text al etichetei <title>.
Următoarele linkuri:
Scrapy simplifică procesul de urmărire a linkurilor. Utilizați următoarea metodă pentru a naviga la alte pagini.
def parse(self, response):
for next_page in response.css('a::attr(href)').getall():
yield response.follow(next_page, self.parse)
Alergarea păianjenului:
Execută-ți spider folosind următoarea comandă din directorul proiectului:
scrapy crawl your_spider
Scrapy va iniția păianjenul, va urma legăturile și va executa logica de parsare definită în metoda parse.
Crawling-ul web cu Scrapy oferă un cadru robust și extensibil pentru gestionarea sarcinilor complexe de scraping. Arhitectura sa modulară și caracteristicile încorporate îl fac o alegere preferată pentru dezvoltatorii care se angajează în proiecte sofisticate de extragere a datelor web.
Accesarea cu crawlere web la scară
Accesarea cu crawlere pe internet la scară prezintă provocări unice, mai ales atunci când aveți de-a face cu o cantitate mare de date răspândite pe numeroase site-uri web. PromptCloud este o platformă specializată concepută pentru a eficientiza și optimiza procesul de crawling la scară. Iată cum PromptCloud poate ajuta la gestionarea inițiativelor de crawling pe internet la scară largă:
- Scalabilitate
- Extragerea și îmbogățirea datelor
- Calitatea și acuratețea datelor
- Managementul infrastructurii
- Ușurință în utilizare
- Conformitate și Etică
- Monitorizare și raportare în timp real
- Suport și întreținere
PromptCloud este o soluție robustă pentru organizațiile și persoanele care doresc să efectueze accesarea cu crawlere pe internet la scară. Prin abordarea provocărilor cheie asociate cu extracția de date pe scară largă, platforma îmbunătățește eficiența, fiabilitatea și gestionabilitatea inițiativelor de crawling pe web.
În concluzie
Crawlerele web sunt eroii necunoscuti în vastul peisaj digital, navigând cu sârguință pe web pentru a indexa, a aduna și a organiza informații. Pe măsură ce amploarea proiectelor de crawling pe web se extinde, PromptCloud intervine ca o soluție, oferind scalabilitate, îmbogățire a datelor și conformitate etică pentru a eficientiza inițiativele la scară largă. Luați legătura cu noi la sales@promptcloud.com