
Înțelegerea arhitecturii GPU pentru optimizarea inferenței LLM
Publicat: 2024-04-02Introducere în LLM și importanța optimizării GPU
În epoca actuală a progreselor procesării limbajului natural (NLP), modelele de limbaj mari (LLM) au apărut ca instrumente puternice pentru o multitudine de sarcini, de la generarea de text până la răspunsuri la întrebări și rezumare. Acestea sunt mai mult decât un următor probabil generator de jetoane. Cu toate acestea, complexitatea și dimensiunea în creștere a acestor modele ridică provocări semnificative în ceea ce privește eficiența și performanța de calcul.
În acest blog, ne aprofundăm în complexitatea arhitecturii GPU, explorând modul în care diferitele componente contribuie la inferența LLM. Vom discuta valorile cheie ale performanței, cum ar fi lățimea de bandă a memoriei și utilizarea nucleului tensorului și vom elucida diferențele dintre diferitele carduri GPU, permițându-vă să luați decizii informate atunci când selectați hardware pentru sarcinile dvs. mari de modele de limbă.
Într-un peisaj în evoluție rapidă în care sarcinile NLP necesită resurse de calcul din ce în ce mai mari, optimizarea debitului de inferență LLM este esențială. Alăturați-vă nouă în această călătorie pentru a debloca întregul potențial al LLM-urilor prin tehnici de optimizare a GPU și pentru a explora diverse instrumente care ne permit să îmbunătățim eficient performanța.
Elemente esențiale ale arhitecturii GPU pentru LLM – Cunoaște-ți elementele interne GPU
Datorită faptului că efectuează calcule paralele extrem de eficiente, GPU-urile devin dispozitivul de alegere pentru a rula toate sarcinile de învățare profundă, așa că este important să înțelegem imaginea de ansamblu la nivel înalt a arhitecturii GPU pentru a înțelege blocajele de bază care apar în timpul etapei de inferență. Cardurile Nvidia sunt preferate datorită CUDA (Compute Unified Device Architecture), o platformă proprie de calcul paralelă și API dezvoltată de NVIDIA, care permite dezvoltatorilor să specifice paralelismul la nivel de fir în limbajul de programare C, oferind acces direct la setul de instrucțiuni virtuale și paralele al GPU-ului. elemente de calcul.
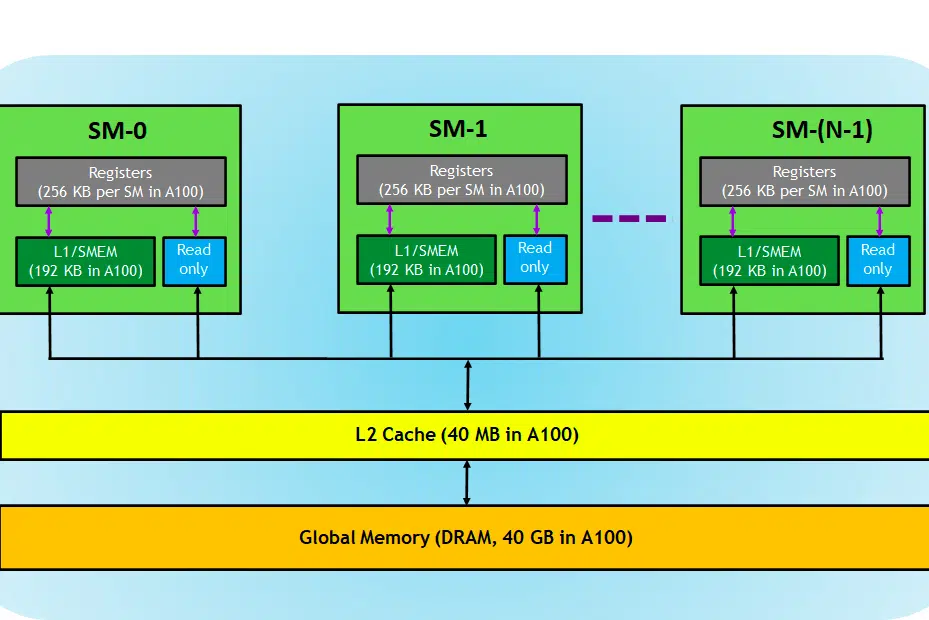
Pentru context, am folosit o placă NVIDIA pentru explicație, deoarece este preferată pe scară largă pentru sarcinile de învățare profundă, așa cum sa menționat deja și câțiva alți termeni precum Tensor Cores sunt aplicabili în acest sens.
Să aruncăm o privire la cardul GPU, aici în imagine, putem vedea trei părți principale și (încă o parte majoră ascunsă) ale unui dispozitiv GPU
- SM (multiprocesoare de streaming)
- cache L2
- Lățimea de bandă a memoriei
- Memorie globală (DRAM)
La fel cum CPU-RAM joacă împreună, RAM fiind locul de reședință a datelor (de exemplu, memorie) și CPU pentru sarcini de procesare (adică proces). Într-un GPU, memoria globală cu lățime de bandă mare (DRAM) deține greutățile modelului (de ex. LLAMA 7B) care sunt încărcate în memorie și, atunci când este necesar, aceste greutăți sunt transferate la unitatea de procesare (adică procesorul SM) pentru calcule.
Multiprocesoare de streaming
Un multiprocesor de streaming sau SM este o colecție de unități de execuție mai mici numite nuclee CUDA (Platformă de calcul paralelă proprie de la NVIDIA), împreună cu unități funcționale suplimentare responsabile de preluarea, decodarea, programarea și expedierea instrucțiunilor. Fiecare SM funcționează independent și conține propriul fișier de registru, memorie partajată, cache L1 și unitate de textură. SM-urile sunt extrem de paralelizate, permițându-le să proceseze mii de fire de execuție simultan, ceea ce este esențial pentru obținerea unui randament ridicat în sarcinile de calcul GPU. Performanța procesorului se măsoară în general în FLOPS, numărul nr. de operatii flotante poate efectua in fiecare sec.
Sarcinile de învățare profundă constau în cea mai mare parte în operații tensoare, adică multiplicarea matricei-matrice, nvidia a introdus nuclee tensoare în GPU-urile de generație mai nouă, care sunt concepute special pentru a efectua aceste operații tensoare într-un mod extrem de eficient. După cum am menționat, nucleele tensor sunt utile atunci când vine vorba de sarcini de învățare profundă și, în loc de nuclee CUDA, trebuie să verificăm nucleele tensor pentru a determina cât de eficient poate un GPU să efectueze antrenamentul/inferența LLM.
Cache L2
Cache-ul L2 este o memorie cu lățime de bandă mare care este partajată între SM-uri, menită să optimizeze accesul la memorie și eficiența transferului de date în cadrul sistemului. Este un tip de memorie mai mic, mai rapid, care se află mai aproape de unitățile de procesare (cum ar fi Streaming Multiprocessors) în comparație cu DRAM. Ajută la îmbunătățirea eficienței generale a accesului la memorie prin reducerea nevoii de a accesa DRAM mai lentă pentru fiecare solicitare de memorie.
Lățimea de bandă a memoriei
Așadar, performanța depinde de cât de repede putem transfera greutățile de la memorie la procesor și cât de eficient și rapid poate procesa procesorul calculele date.
Când capacitatea de calcul este mai mare/mai rapidă decât rata de transfer de date între memorie la SM, SM-ul va lipsi de date pentru procesarea datelor și, astfel, calculul este subutilizat, această situație în care lățimea de bandă a memoriei este mai mică decât rata de consum este cunoscută ca fază legată de memorie. . Acest lucru este foarte important de remarcat, deoarece acesta este blocajul predominant în procesul de inferență.
Dimpotrivă, dacă procesarea durează mai mult timp pentru procesare și dacă mai multe date sunt puse în coadă pentru calcul, această stare este o fază legată de calcul .
Pentru a profita pe deplin de GPU, trebuie să fim într-o stare de calcul, în timp ce efectuăm calculele care apar cât mai eficient posibil.
Memorie DRAM
DRAM servește ca memorie principală într-un GPU, oferind un pool mare de memorie pentru stocarea datelor și instrucțiunilor necesare pentru calcul. Este de obicei organizat într-o ierarhie, cu mai multe bănci de memorie și canale pentru a permite accesul de mare viteză.

Pentru sarcina de inferență, DRAM-ul GPU-ului determină cât de mare putem încărca un model, iar FLOPS-ul de calcul și lățimea de bandă determină debitul pe care îl putem obține.
Compararea cardurilor GPU pentru sarcini LLM
Pentru a obține informații despre numerele nucleelor tensorului, viteza lățimii de bandă, puteți parcurge documentul publicat de producătorul GPU-ului. Iată un exemplu,
| RTX A6000 | RTX 4090 | RTX 3090 | |
| Capacitate de memorie | 48 GB | 24 GB | 24 GB |
| Tip de memorie | GDDR6 | GDDR6X | |
| Lățimea de bandă | 768,0 GB/s | 1008 GB/sec | 936,2 GB/s |
| Nuclee CUDA / GPU | 10752 | 16384 | 10496 |
| Miezuri tensoare | 336 | 512 | 328 |
| Cache L1 | 128 KB (per SM) | 128 KB (per SM) | 128 KB (per SM) |
| FP16 Non-Tensor | 38,71 TFLOPS (1:1) | 82,6 | 35,58 TFLOPS (1:1) |
| FP32 Non-Tensor | 38,71 TFLOPS | 82,6 | 35,58 TFLOPS |
| FP64 Non-Tensor | 1.210 GFLOPS (1:32) | 556,0 GFLOPS (1:64) | |
| Peak FP16 Tensor TFLOPS cu FP16 Accumulate | 154,8/309,6 | 330,3/660,6 | 142/284 |
| Peak FP16 Tensor TFLOPS cu FP32 Accumulate | 154,8/309,6 | 165,2/330,4 | 71/142 |
| Peak BF16 Tensor TFLOPS cu FP32 | 154,8/309,6 | 165,2/330,4 | 71/142 |
| Peak TF32 Tensor TFLOPS | 77,4/154,8 | 82,6/165,2 | 35,6/71 |
| Vârf INT8 Tensor TOPS | 309,7/619,4 | 660,6/1321,2 | 284/568 |
| Vârf INT4 Tensor TOPS | 619,3/1238,6 | 1321.2/2642.4 | 568/1136 |
| Cache L2 | 6 MB | 72 MB | 6 MB |
| Bus de memorie | 384 de biți | 384 de biți | 384 de biți |
| TMU-uri | 336 | 512 | 328 |
| ROP-uri | 112 | 176 | 112 |
| SM Count | 84 | 128 | 82 |
| Miezuri RT | 84 | 128 | 82 |
Aici putem vedea că FLOPS este menționat în mod special pentru operațiunile Tensor, aceste date ne vor ajuta să comparăm diferitele carduri GPU și să o listăm pe cea potrivită pentru cazul nostru de utilizare. Din tabel, deși A6000 are de două ori memoria de 4090, flop-urile tensoare și lățimea de bandă a memoriei de 4090 sunt mai bune ca număr și, prin urmare, mai puternice pentru inferența modelelor mari de limbaj.
Citiți mai departe: Nvidia CUDA în 100 de secunde
Concluzie
În domeniul NLP care progresează rapid, optimizarea modelelor de limbaj mari (LLM) pentru sarcinile de inferență a devenit un domeniu critic de focalizare. După cum am explorat, arhitectura GPU-urilor joacă un rol esențial în atingerea performanței și eficienței ridicate în aceste sarcini. Înțelegerea componentelor interne ale GPU-urilor, cum ar fi Streaming Multiprocessors (SM-uri), cache-ul L2, lățimea de bandă a memoriei și DRAM, este esențială pentru identificarea potențialelor blocaje în procesele de inferență LLM.
Comparația dintre diferitele plăci GPU NVIDIA - RTX A6000, RTX 4090 și RTX 3090 - dezvăluie diferențe semnificative în ceea ce privește dimensiunea memoriei, lățimea de bandă și numărul de nuclee CUDA și Tensor, printre alți factori. Aceste distincții sunt cruciale pentru a lua decizii informate cu privire la care GPU este cel mai potrivit pentru sarcini specifice LLM. De exemplu, în timp ce RTX A6000 oferă o dimensiune de memorie mai mare, RTX 4090 excelează în ceea ce privește Tensor FLOPS și lățimea de bandă a memoriei, făcându-l o alegere mai puternică pentru sarcini de inferență LLM solicitante.
Optimizarea inferenței LLM necesită o abordare echilibrată care să ia în considerare atât capacitatea de calcul a GPU-ului, cât și cerințele specifice ale sarcinii LLM la îndemână. Selectarea GPU-ului potrivit implică înțelegerea compromisurilor dintre capacitatea memoriei, puterea de procesare și lățimea de bandă pentru a se asigura că GPU-ul poate gestiona eficient greutățile modelului și poate efectua calcule fără a deveni un blocaj. Pe măsură ce domeniul NLP continuă să evolueze, rămânerea la curent cu cele mai recente tehnologii GPU și capacitățile acestora va fi esențială pentru cei care doresc să depășească limitele a ceea ce este posibil cu modelele de limbaj mari.
Terminologia folosită
- Debit:
În caz de inferență, debitul este măsura a câte solicitări/ solicitări sunt procesate pentru o anumită perioadă de timp. Debitul este de obicei măsurat în două moduri:
- Cereri pe secundă (RPS) :
- RPS măsoară numărul de solicitări de inferență pe care un model le poate gestiona într-o secundă. O cerere de inferență implică de obicei generarea unui răspuns sau predicție pe baza datelor de intrare.
- Pentru generarea LLM, RPS indică cât de repede poate răspunde modelul la solicitările sau la întrebările primite. Valorile RPS mai mari sugerează o mai bună capacitate de răspuns și scalabilitate pentru aplicații în timp real sau aproape în timp real.
- Atingerea unor valori RPS ridicate necesită adesea strategii eficiente de implementare, cum ar fi gruparea mai multor cereri împreună pentru a amortiza cheltuielile generale și a maximiza utilizarea resurselor de calcul.
- Jetoane pe secundă (TPS) :
- TPS măsoară viteza cu care un model poate procesa și genera simboluri (cuvinte sau subcuvinte) în timpul generării textului.
- În contextul generării LLM, TPS reflectă randamentul modelului în ceea ce privește generarea de text. Indică cât de repede modelul poate produce răspunsuri coerente și semnificative.
- Valorile TPS mai mari implică o generare mai rapidă a textului, permițând modelului să proceseze mai multe date de intrare și să genereze răspunsuri mai lungi într-o anumită perioadă de timp.
- Atingerea unor valori TPS ridicate implică adesea optimizarea arhitecturii modelului, paralelizarea calculelor și utilizarea acceleratoarelor hardware precum GPU-urile pentru a accelera generarea de token-uri.
- Latență:
Latența în LLM se referă la întârzierea dintre intrare și ieșire în timpul inferenței. Minimizarea latenței este esențială pentru îmbunătățirea experienței utilizatorului și pentru a permite interacțiunile în timp real în aplicațiile care folosesc LLM-uri. Este esențial să găsim un echilibru între debit și latență pe baza serviciului pe care trebuie să-l oferim. Latența scăzută este de dorit pentru cazuri, cum ar fi interacțiunea în timp real, chatbot/copilotul, dar nu este necesară pentru cazurile de procesare în masă a datelor, cum ar fi reprocesarea internă a datelor.
Citiți mai multe despre Tehnici avansate pentru îmbunătățirea debitului LLM aici.