
Web crawler - un ghid complet
Publicat: 2023-12-12Crawling pe Web
Web crawling, un proces fundamental în domeniul indexării web și al tehnologiei motoarelor de căutare, se referă la navigarea automată a World Wide Web printr-un program software cunoscut sub numele de web crawler. Aceste crawler-uri, uneori numite păianjeni sau roboți, navighează sistematic pe web pentru a aduna informații de pe site-uri web. Acest proces permite colectarea și indexarea datelor, ceea ce este crucial pentru motoarele de căutare pentru a oferi rezultate de căutare actualizate și relevante.
Funcții cheie ale accesării cu crawlere web:
- Indexarea conținutului : crawlerele web scanează paginile web și le indexează conținutul, făcându-l căutat. Acest proces de indexare implică analiza textului, imaginilor și a altor conținuturi dintr-o pagină pentru a înțelege subiectul acesteia.
- Analiza linkurilor : crawlerele urmăresc linkuri de la o pagină web la alta. Acest lucru ajută nu numai la descoperirea de noi pagini web, ci și la înțelegerea relațiilor și ierarhiei dintre diferitele pagini web.
- Detectarea actualizării conținutului : prin revizuirea periodică a paginilor web, crawlerele pot detecta actualizări și modificări, asigurându-se că conținutul indexat rămâne actual.
Ghidul nostru pas cu pas pentru crearea unui crawler web vă va ajuta să înțelegeți mai multe despre procesul de accesare cu crawlere web.
Ce este un web crawler
Un web crawler, cunoscut și sub numele de spider sau bot, este un program software automat care navighează sistematic pe World Wide Web în scopul indexării web. Funcția sa principală este de a scana și indexa conținutul paginilor web, care include text, imagini și alte medii. Crawlerele web pornesc de la un set cunoscut de pagini web și urmează link-uri de pe aceste pagini pentru a descoperi pagini noi, acționând ca o persoană care navighează pe web. Acest proces permite motoarelor de căutare să adune și să-și actualizeze datele, asigurându-se că utilizatorii primesc rezultate de căutare actuale și cuprinzătoare. Funcționarea eficientă a crawlerelor web este esențială pentru menținerea depozitului vast și în continuă creștere de informații online, accesibil și căutat.
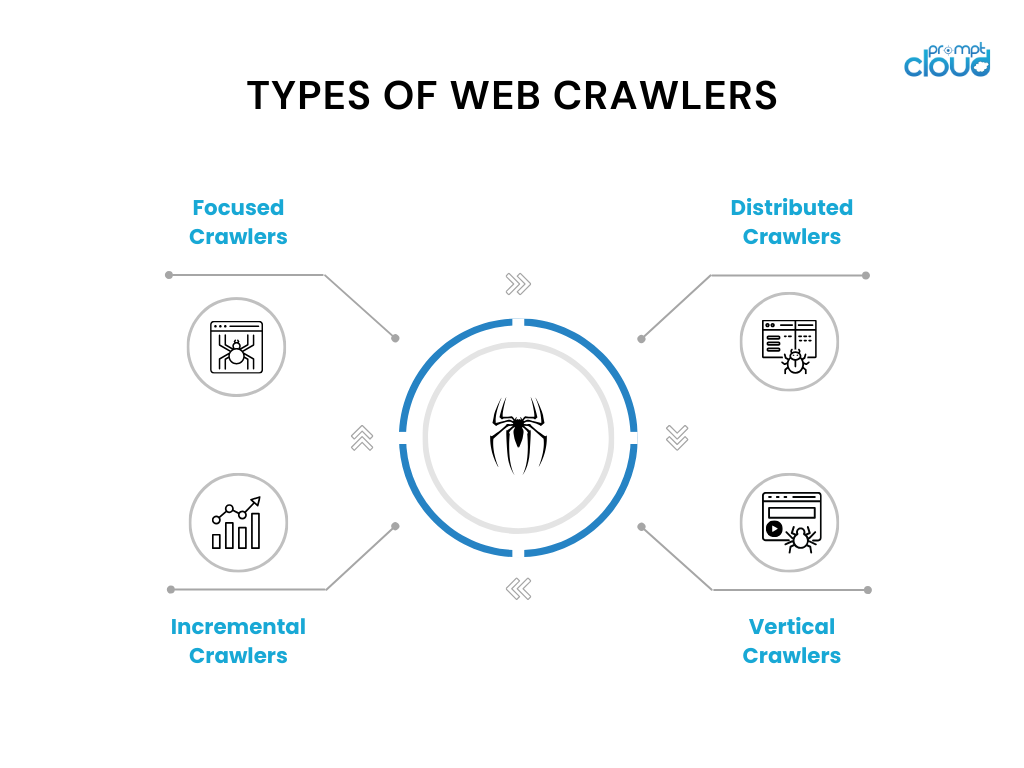
Cum funcționează un crawler web
Crawlerele web funcționează prin navigarea sistematică pe internet pentru a aduna și indexa conținutul site-ului web, un proces crucial pentru motoarele de căutare. Ei pornesc de la un set de adrese URL cunoscute și accesează aceste pagini web pentru a prelua conținut. În timp ce parsează paginile, identifică toate hyperlinkurile și le adaugă la lista de adrese URL de vizitat în continuare, cartografiind în mod eficient structura web-ului. Fiecare pagină vizitată este procesată pentru a extrage informații relevante, cum ar fi text, imagini și metadate, care sunt apoi stocate într-o bază de date. Aceste date devin fundamentul indexului unui motor de căutare, permițându-i acestuia să furnizeze rezultate de căutare rapide și relevante.
Crawlerele web trebuie să funcționeze în cadrul anumitor constrângeri, cum ar fi respectarea regulilor stabilite în fișierele robots.txt de către proprietarii site-urilor web și evitarea supraîncărcării serverelor, asigurând un proces de crawling etic și eficient. Pe măsură ce navighează prin miliarde de pagini web, acești crawler-uri se confruntă cu provocări precum gestionarea conținutului dinamic, gestionarea paginilor duplicate și rămânerea la curent cu cele mai recente tehnologii web, făcând rolul lor în ecosistemul digital atât de complex, cât și de indispensabil. Iată un articol detaliat despre cum funcționează crawlerele web.
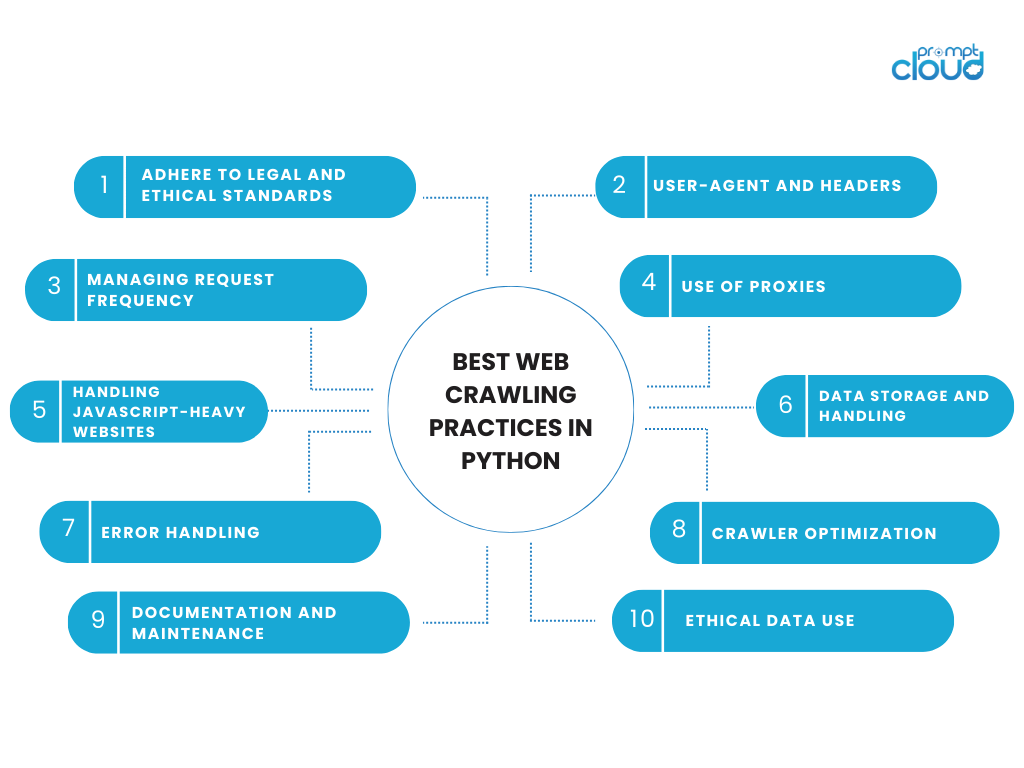
Python Web Crawler
Python, renumit pentru simplitatea și lizibilitatea sa, este un limbaj de programare ideal pentru construirea crawlerelor web. Ecosistemul său bogat de biblioteci și cadre simplifică procesul de scriere a scripturilor care navighează, analizează și extrag date de pe web. Iată aspectele cheie care fac din Python o alegere de preferat pentru accesarea cu crawlere web:
Biblioteci Python cheie pentru crawling web:
- Cereri : această bibliotecă este folosită pentru a face solicitări HTTP către paginile web. Este simplu de utilizat și poate gestiona diverse tipuri de solicitări, esențiale pentru accesarea conținutului paginii web.
- Beautiful Soup : Specializată în analizarea documentelor HTML și XML, Beautiful Soup permite extragerea ușoară a datelor din paginile web, făcând mai simplă navigarea prin structura etichetelor documentului.
- Scrapy : un cadru de crawling web open-source, Scrapy oferă un pachet complet pentru scrierea crawlerelor web. Se ocupă fără probleme de solicitări, parsarea răspunsurilor și extragerea datelor.
Avantajele utilizării Python pentru accesarea cu crawlere web:
- Ușurință în utilizare : sintaxa simplă a lui Python îl face accesibil chiar și celor care sunt începători în programare.
- Asistență solidă pentru comunitate : o comunitate mare și o mulțime de documente care ajută la depanarea și îmbunătățirea funcționalității crawler-ului.
- Flexibilitate și scalabilitate : crawlerele Python pot fi atât de simple sau complexe, cât este necesar, scalând de la proiecte mici la proiecte mari.
Exemplu de crawler web Python de bază:
cereri de import

de la bs4 import BeautifulSoup
# Definiți adresa URL de accesat cu crawlere
url = „http://example.com”
# Trimiteți o solicitare HTTP către adresa URL
răspuns = requests.get(url)
# Analizați conținutul HTML al paginii
supă = BeautifulSoup(response.text, 'html.parser')
# Extrageți și imprimați toate hyperlinkurile
pentru link în soup.find_all('a'):
print(link.get('href'))
Acest script simplu demonstrează funcționarea de bază a unui crawler web Python. Preia conținutul HTML al unei pagini web folosind solicitări, îl analizează cu Beautiful Soup și extrage toate hyperlinkurile.
Crawlerele web Python se remarcă prin ușurința de dezvoltare și eficiența în extragerea datelor.
Fie că este vorba de analiză SEO, data mining sau marketing digital, Python oferă o bază solidă și flexibilă pentru sarcinile de crawling pe web, făcându-l o alegere excelentă atât pentru programatori, cât și pentru oamenii de știință de date.
Cazuri de utilizare pentru accesarea cu crawlere web
Crawling-ul web are o gamă largă de aplicații în diferite industrii, reflectând versatilitatea și importanța sa în era digitală. Iată câteva dintre cazurile cheie de utilizare:
Indexarea motoarelor de căutare
Cea mai cunoscută utilizare a crawlerelor web este de către motoarele de căutare precum Google, Bing și Yahoo pentru a crea un index de căutare al web. Crawlerele scanează paginile web, le indexează conținutul și le clasifică pe baza diferiților algoritmi, făcându-le căutate pentru utilizatori.
Exploatarea și analiza datelor
Companiile folosesc crawlerele web pentru a colecta date despre tendințele pieței, preferințele consumatorilor și concurența. Cercetătorii folosesc crawler-uri pentru a agrega date din mai multe surse pentru studii academice.
Monitorizare SEO
Webmasterii folosesc crawlerele pentru a înțelege modul în care motoarele de căutare își văd site-urile web, ajutând la optimizarea structurii, conținutului și performanței site-ului. Ele sunt, de asemenea, folosite pentru a analiza site-urile web ale concurenților pentru a înțelege strategiile lor SEO.
Agregarea conținutului
Crawlerele sunt folosite de platformele de agregare de știri și conținut pentru a aduna articole și informații din diverse surse. Agregarea conținutului de pe platformele de rețele sociale pentru a urmări tendințele, subiectele populare sau mențiunile specifice.
Comerțul electronic și compararea prețurilor
Crawlerele ajută la urmărirea prețurilor produselor pe diferite platforme de comerț electronic, ajutând la strategiile de prețuri competitive. De asemenea, sunt folosite pentru catalogarea produselor de pe diverse site-uri de comerț electronic într-o singură platformă.
Listări imobiliare
Crawlerele adună liste de proprietăți de pe diverse site-uri web imobiliare pentru a oferi utilizatorilor o vedere consolidată a pieței.
Lista de locuri de munca si recrutare
Agregarea listelor de locuri de muncă de pe diverse site-uri web pentru a oferi o platformă cuprinzătoare de căutare a unui loc de muncă. Unii recrutori folosesc crawler-uri pentru a căuta pe web potențiali candidați cu calificări specifice.
Învățare automată și instruire AI
Crawlerele pot aduna cantități mari de date de pe web, care pot fi folosite pentru a antrena modele de învățare automată în diverse aplicații.
Web Scraping vs Web Crawling
Web scraping și web crawling sunt două tehnici utilizate în mod obișnuit în culegerea de date de pe site-uri web, dar servesc unor scopuri diferite și funcționează în moduri distincte. Înțelegerea diferențelor este cheia pentru oricine implicat în extragerea datelor sau analiza web.
Web Scraping
- Definiție : Web scraping este procesul de extragere a datelor specifice din paginile web. Se concentrează pe transformarea datelor web nestructurate (de obicei în format HTML) în date structurate care pot fi stocate și analizate.
- Extragerea datelor vizate : Scrapingul este adesea folosit pentru a colecta informații specifice de pe site-uri web, cum ar fi prețurile produselor, datele stocurilor, articolele de știri, informațiile de contact etc.
- Instrumente și tehnici : implică utilizarea instrumentelor sau a programării (de multe ori Python, PHP, JavaScript) pentru a solicita o pagină web, a analiza conținutul HTML și a extrage informațiile dorite.
- Cazuri de utilizare : cercetare de piață, monitorizare a prețurilor, generare de clienți potențiali, date pentru modelele de învățare automată etc.
Crawling pe Web
- Definiție : Crawling-ul web, pe de altă parte, este procesul de navigare sistematică pe web pentru a descărca și indexa conținut web. Este asociat în principal cu motoarele de căutare.
- Indexarea și urmărirea legăturilor : crawlerele sau păianjenii sunt folosite pentru a vizita o gamă largă de pagini pentru a înțelege structura și legăturile site-ului. De obicei, ei indexează tot conținutul unei pagini.
- Automatizare și scalare : accesarea cu crawlere web este un proces mai automatizat, capabil să gestioneze extracția de date la scară largă pe multe pagini web sau site-uri web întregi.
- Considerații : crawlerele trebuie să respecte regulile stabilite de site-uri web, cum ar fi cele din fișierele robots.txt, și sunt concepute pentru a naviga fără a supraîncărca serverele web.
Instrumente de accesare cu crawlere web
Instrumentele de crawling pe web sunt instrumente esențiale în setul de instrumente digital al companiilor, cercetătorilor și dezvoltatorilor, oferind o modalitate de a automatiza colectarea datelor de pe diferite site-uri web de pe internet. Aceste instrumente sunt concepute pentru a naviga sistematic în paginile web, a extrage informații utile și a le stoca pentru o utilizare ulterioară. Iată o prezentare generală a instrumentelor de crawling pe web și a semnificației acestora:
Funcționalitate : instrumentele de accesare cu crawlere web sunt programate pentru a naviga prin site-uri web, pentru a identifica informații relevante și pentru a le prelua. Ei imită comportamentul uman de navigare, dar o fac la o scară și o viteză mult mai mare.
Extragerea și indexarea datelor : Aceste instrumente analizează datele de pe paginile web, care pot include text, imagini, link-uri și alte medii, apoi le organizează într-un format structurat. Acest lucru este util în special pentru crearea bazelor de date cu informații care pot fi căutate și analizate cu ușurință.
Personalizare și flexibilitate : multe instrumente de accesare cu crawlere oferă opțiuni de personalizare, permițând utilizatorilor să specifice ce site-uri web să acceseze cu crawlere, cât de adânc să intre în arhitectura site-ului și ce fel de date să extragă.
Cazuri de utilizare : sunt utilizate în diverse scopuri, cum ar fi optimizarea pentru motoarele de căutare (SEO), cercetarea de piață, agregarea conținutului, analiza competitivă și colectarea de date pentru proiecte de învățare automată.
Articolul nostru recent oferă o prezentare detaliată a celor mai importante instrumente de crawling web din 2024. Consultați articolul pentru a afla mai multe. Luați legătura cu noi la [email protected] pentru soluții personalizate de crawling web.