
Ce este etichetarea datelor în învățarea automată și cum funcționează?
Publicat: 2022-04-29Datele reprezintă noua bogăție pentru afacerile de astăzi. Cu tehnologii precum inteligența artificială preluând treptat majoritatea activităților noastre de zi cu zi, utilizarea corectă a oricăror date a influențat în mod pozitiv societatea. Prin segregarea și etichetarea eficientă a datelor, algoritmii ML pot descoperi problemele și pot oferi soluții practice și relevante.
Cu ajutorul etichetării datelor, învățăm mașina diverse tehnici și introducem informațiile în diferite formate pentru ca acestea să se comporte „inteligent”. Știința din spatele etichetării datelor implică o mulțime de teme sub forma adnotării sau etichetării seturilor de date cu mai multe variații ale aceleiași informații. Deși rezultatul final ne surprinde și ne ușurează viața de zi cu zi, munca din spatele acestuia este imensă și dăruirea este lăudabilă.
Ce este etichetarea datelor?
În învățarea automată, calitatea și tipul datelor de intrare determină calitatea și tipul de ieșire. Calitatea datelor utilizate pentru antrenarea mașinii mărește acuratețea modelului dvs. AI.
Cu alte cuvinte, etichetarea datelor este un proces de instruire a unei mașini pentru a găsi diferențele și asemănările dintre seturile de date nestructurate sau structurate prin etichetarea sau adnotarea acestora.
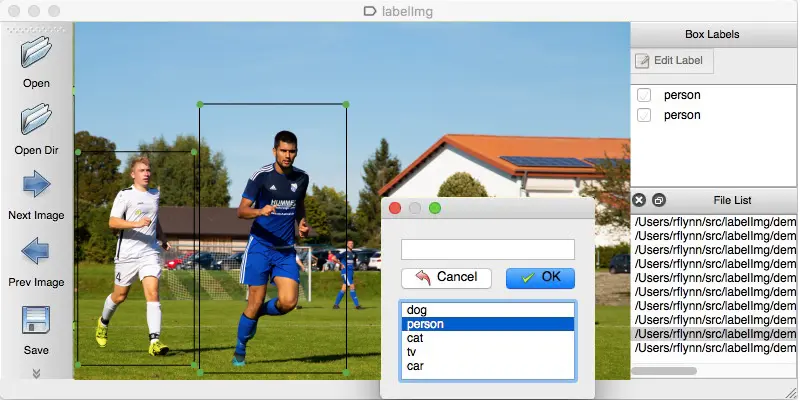
Să înțelegem asta cu un exemplu. Pentru a instrui mașina că lumina roșie este semnul de oprire, trebuie să etichetați toate luminile roșii în diferite imagini pentru ca mașina să înțeleagă semnalul. Pe baza acestui fapt, AI creează un algoritm care va citi lumina roșie ca un semnal de oprire în fiecare scenariu dat. Un alt exemplu este că genurile muzicale pot fi separate cu mai multe seturi de date sub etichetele jazz, pop, rock, clasic și multe altele.
Provocări în etichetarea datelor
Orice noi schimbări/progrese în tehnologie sau structură aduc beneficii și provocări. Nu este diferit pentru etichetarea datelor. În timp ce etichetarea datelor poate reduce drastic timpul de extindere a unei afaceri , aceasta are un cost. Să ne oprim asupra unora dintre provocările pe care le aduce etichetarea datelor.
Cost în termeni de timp și efort
Este o sarcină dificilă în sine să obțineți datele specifice nișei în cantități uriașe. Adăugarea manuală a etichetelor pentru fiecare articol se adaugă doar sarcinii care consumă deja timp. Dacă proiectul este gestionat intern, cea mai mare parte a timpului proiectului este alocat sarcinilor legate de date, cum ar fi colectarea, pregătirea și etichetarea datelor.
Pentru a gestiona aceste sarcini în mod eficient, astfel încât să lucrați corect din prima încercare, veți avea nevoie de etichetatori experți cu această experiență specifică. Aceasta este, de asemenea, o întreprindere costisitoare, ceea ce o face costisitoare, nu doar în termeni de timp, ci și în bani.
Incoerență
Adnotatorii cu expertiză diferită pot avea criterii de etichetare diferite. În consecință, există o mare posibilitate de etichetare inconsecventă. Acestea fiind spuse, atunci când mai multe persoane etichetează același set de date, ratele de acuratețe a datelor vor fi mult mai mari.
Expertiza domeniului
Pentru anumite industrii, veți simți nevoia de a angaja etichetatori cu expertiză în domeniu. De exemplu, pentru a crea o aplicație ML pentru industria de asistență medicală , adnotatorii fără expertiză relevantă în domeniu le va fi foarte dificil să eticheteze elementele corect.
Imperfecțiuni
Orice muncă repetitivă făcută de oameni este predispusă la erori. Indiferent de nivelul de expertiză pe care îl poate avea etichetatorul uman, etichetarea manuală va avea întotdeauna amploarea imperfecțiunii. Asigurarea zero erori este aproape imposibilă, deoarece adnotatorii trebuie să se ocupe de seturi mari de date brute pentru etichetare.
Abordări ale etichetării datelor
După cum s-a menționat mai sus, etichetarea datelor este o sarcină care necesită timp, care necesită atenție la detalii. Pe baza enunțului problemei, a cantității de date care urmează să fie etichetate, a complexității datelor și a stilului, strategia aplicată pentru adnotarea datelor va varia.
Să trecem în revistă diverse abordări pentru care compania ta poate opta în funcție de resursele financiare și timpul disponibil.
Etichetarea internă a datelor
Pe baza tipului de industrie, a timpului disponibil pentru finalizarea proiectului AI dat și a disponibilității resurselor necesare, procesul de etichetare a datelor poate fi efectuat intern de către organizații.
Pro:
- Precizie ridicată
- Calitate superioară
- Urmărire simplificată
Contra:
- Consumatoare de timp/lent
- Necesită resurse extinse
Crowdsourcing
Seturile de date de aprovizionare care sunt etichetate de freelanceri sunt disponibile pe diverse platforme de crowdsourcing. Această metodă poate fi utilizată pentru adnotarea datelor generalizate precum imaginile.
Cel mai faimos exemplu de etichetare a datelor prin crowdsourcing este Recaptcha. Utilizatorului i se cere să identifice anumite tipuri de imagini pentru a dovedi că sunt oameni. Acestea sunt verificate pe baza intrărilor date de alți utilizatori. Aceasta acționează ca o bază de date de etichete pentru o serie de imagini.
Pro:
- Rapid și ușor
- Eficient din punct de vedere al costurilor
Contra:
- Nu poate fi utilizat pentru date care necesită expertiză în domeniu
- Calitatea nu este garantată
externalizarea
Externalizarea poate acționa ca o cale intermediară între etichetarea internă a datelor și crowdsourcing. Angajarea unor organizații terțe sau a unor persoane cu expertiză în domeniu poate ajuta organizațiile cu toate proiectele – pe termen lung și pe termen scurt.
Pro:
- Optim pentru proiecte temporare de nivel înalt
- Companiile terțe de externalizare oferă personal verificat
- Oferă atât instrumente de etichetare a datelor preconstruite, cât și personalizate, conform nevoilor afacerii dvs
- Pot beneficia de opțiunea experților în etichetarea datelor specifice nișei
Contra:
- Gestionarea terței părți poate fi consumatoare de timp
Bazat pe mașină
Una dintre cele mai recente forme de etichetare și adnotare a datelor care este utilizată și acceptată pe scară largă de industrii este adnotarea bazată pe mașini. Automatizarea procesului de etichetare a datelor cu ajutorul software-ului de etichetare a datelor, reduce intervenția umană și crește viteza cu care se poate face etichetarea. Cu tehnica numită învățare activă, datele pot fi etichetate pe baza cărora etichetele pot fi adăugate automat la seturile de date de antrenament.
Pro:
- Procesare și etichetare mai rapidă a datelor
- Implică o intervenție umană mai mică
Contra:
- Deși de mai bună calitate, dar nu la egalitate cu etichetarea umană
- În caz de erori, intervenția umană este totuși necesară

Cum funcționează etichetarea datelor?
Pe baza nevoilor dvs. de afaceri, puteți alege abordarea care se potrivește cel mai bine cerințelor dvs. Cu toate acestea, procesul de etichetare a datelor funcționează în următoarea ordine cronologică.
Colectare de date
Baza oricărui proiect de învățare automată sunt datele. Colectarea cantității potrivite de date brute în diferite formate cuprinde primul pas al etichetării datelor. Colectarea datelor poate fi de două forme – una pe care compania a colectat-o intern și cealaltă, care este colectată din surse externe care sunt disponibile publicului.
Fiind în formă brută, aceste date necesită curățare și procesare înainte de a crea etichetele pentru seturile de date. Aceste date curățate și preprocesate sunt apoi transmise modelului pentru antrenament. Cu cât datele sunt mai mari și mai diversificate, cu atât rezultatele vor fi mai precise.
Adnotarea datelor
Odată ce datele sunt curățate, experții în domeniu parcurg datele și adaugă etichete urmând diverse abordări de etichetare a datelor. Contextul semnificativ este atașat modelului care poate fi folosit ca adevăr de bază Acestea sunt variabilele țintă, cum ar fi imaginile, pe care doriți să le prezică modelul.

Asigurarea calității
Succesul instruirii modelului ML depinde în mare măsură de calitatea datelor care ar trebui să fie fiabile, precise și consecvente. Pentru a asigura aceste etichete de date precise și exacte, trebuie să existe controale regulate de asigurare a calității. Cu ajutorul algoritmilor QA, cum ar fi testul alfa Consensus și Cronbach, poate fi determinată acuratețea acestor adnotări. Verificările regulate de asigurare a calității contribuie în mare măsură la acuratețea rezultatelor.
Antrenament și testare model
Efectuarea tuturor pașilor de mai sus are sens numai dacă datele sunt testate pentru acuratețe. Introducerea setului de date nestructurat pentru a vedea dacă oferă rezultatele așteptate va testa procesul.
Cazuri de utilizare la nivel de industrie pentru etichetarea datelor
Acum că suntem familiarizați cu ce este etichetarea datelor și cum funcționează, să trecem în revistă cele mai importante cazuri de utilizare.
Viziune computerizată (CV)
Acesta este un subset de AI care permite mașinilor să obțină o interpretare semnificativă din intrările furnizate sub formă de imagini și videoclipuri (imagini statice extrase pentru etichetare).
Adnotarea computerizată poate fi utilizată în diverse industrii pentru a implementa beneficiile practice ale AI.
- În industria auto, etichetarea imaginilor și videoclipurilor pentru a segmenta drumuri, clădiri, pietoni și alte obiecte va ajuta vehiculele autonome să facă distincția între aceste entități pentru a evita contactul în viața reală.
- În industria sănătății, simptomele bolii pot fi segmentate într-o scanare cu raze X, RMN și CT. Cu ajutorul imaginilor microscopice, cele mai multe boli critice pot fi diagnosticate într-un stadiu incipient.
- Codurile QR, codurile de bare de etichetă etc. pot fi folosite ca etichete în industria transporturilor și logisticii pentru a urmări mărfurile.
Procesarea limbajului natural (NLP)
Acesta este un subset care permite mașinilor AI să interpreteze limbajul uman și statisticile. Obținând sens din text și vorbire, algoritmul poate analiza diverse aspecte lingvistice.
NLP este din ce în ce mai utilizat în multe soluții de întreprindere .
- Este folosit în mod obișnuit în toate industriile ca asistent de e-mail, funcție de completare automată, verificator ortografic, segregarea e-mailurilor spam și non-spam și multe altele.
- Sub formă de chatbot , întrebările de bază adresate de clienți sunt interpretate și răspunse fără intervenție umană în timp real. Se estimează că 70% din interacțiunile cu clienții vor fi gestionate de chatbot și aplicații de mesagerie mobilă până în anul 2023.
- Înțelegerea polarității negative și pozitive a textului pentru a capta sentimentul clienților se face prin etichetarea datelor în comerțul electronic.
Appinventiv a creat cu succes o aplicație de social media pentru Vyrb , care le permite utilizatorilor să trimită și să primească mesaje audio optimizate pentru purtabile Bluetooth.

Prezentare generală a pieței de etichetare a datelor AI
Etichetarea datelor este o industrie înfloritoare care se naște din tehnologia AI . Întrucât etichetarea datelor depinde în mare măsură de datele exacte care sunt transmise învățării automate, este sigur că va crește în următorii câțiva ani.
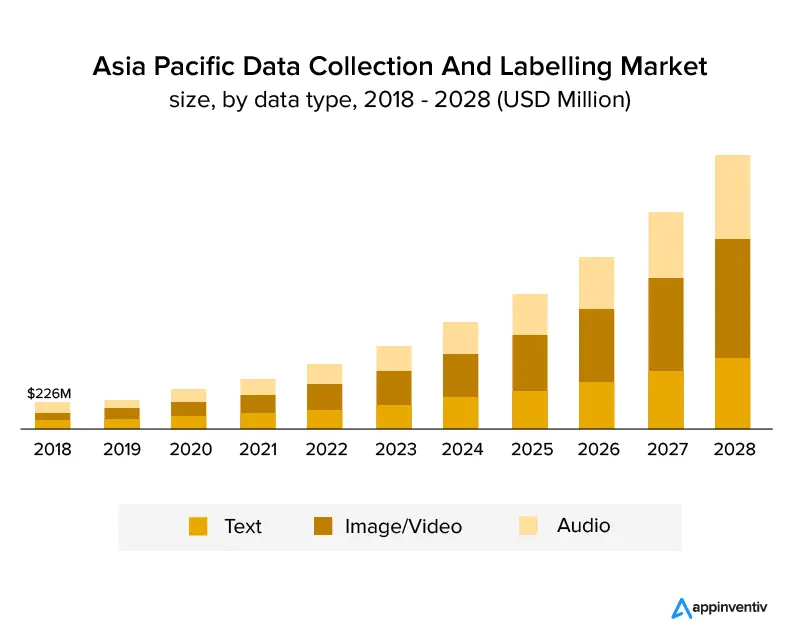
Graficul de mai jos arată clar că industria a crescut și va continua să crească în următorii ani. Este de așteptat să crească cu o creștere anuală compusă de 25,6% și să atingă o dimensiune a pieței de 8,22 miliarde USD până în 2028. Graficul de mai jos arată creșterea în funcție de tipul de date.
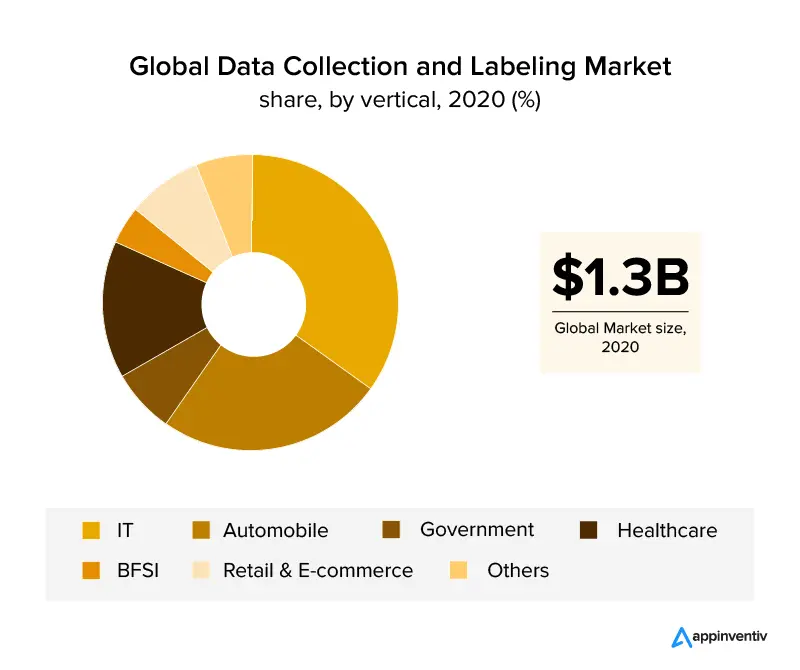
O privire de ansamblu asupra verticalelor de afaceri care au exploatat etichetarea datelor sunt sectoarele IT și auto, care acoperă peste 30% din veniturile globale. Odată cu creșterea industriei de asistență medicală , este de așteptat ca etichetarea datelor să aibă o expansiune din cauza cerințelor de date precise pentru aplicații eficiente bazate pe inteligență artificială din sector. Cu ajutorul etichetării imaginilor, și industria comerțului cu amănuntul și comerțul electronic și-au asigurat o cotă de piață semnificativă în industria de etichetare a datelor.
Etichetarea datelor cu Appinventiv
Strategic, companiile au externalizat serviciile de colectare și etichetare a datelor pentru a construi modele puternice de învățare automată.
Appinventiv este o companie de dezvoltare AI și ML care ajută organizațiile să deblocheze oportunități cu soluții bazate pe AI de mulți ani . Cu aproape un deceniu de experiență în transformarea afacerilor, am livrat cu succes multe proiecte complexe de IA pentru diferite industrii.
De exemplu, Appinventiv a automatizat cu succes procesul bancar pentru o bancă lider din Europa. Procesul de automatizare a ajutat banca să îmbunătățească acuratețea cu 50% și nivelurile de servicii ATM cu 92%.
Un alt exemplu în care Appinventiv a ajutat YouCOMM să construiască o soluție revoluționară pentru transformarea comunicării cu pacientul în spital, oferind acces în timp real la ajutor medical. Cu un sistem de mesaje personalizat pentru pacient, pacienții pot notifica cu ușurință personalul cu privire la nevoile lor prin comenzi vocale și prin utilizarea gesturilor capului.
Cu expertiza noastră și echipa centrată pe clienți, oferim servicii de etichetare a datelor care vă vor ajuta să depășiți provocările, oferindu-vă servicii de etichetare a datelor holistice, bazate pe nevoile și cerințele dumneavoastră specifice.
Prin valorificarea gamei vaste de instrumente necesare pentru etichetare și adnotare a datelor, Appinventiv vă poate îmbunătăți procesele de formare a datelor pentru a simplifica modele complexe. Acest lucru ne permite să depășim în ceea ce privește acuratețea segmentării, clasificării și, ulterior, etichetarea datelor, care va fi rapid și ușor.
Încheierea!
„Puterea inteligenței artificiale este atât de incredibilă, încât va schimba societatea în moduri foarte profunde.” - Bill Gates
Inteligența artificială are potențialul de a ușura viața omului, făcând astfel bine societății. Capacitatea sa de a sorta cantități uriașe de date în instrucțiuni semnificative cu ajutorul etichetării datelor a ajutat industriile să avanseze și să se dezvolte cu un pas.
FAQ
Î. Care sunt cele mai bune practici pentru a perfecționa etichetarea datelor?
A. Pe baza abordării pe care o adoptați pentru etichetarea datelor, există câteva bune practici pe care le puteți urma:
- Asigurați-vă că datele colectate sunt adecvate, curățate și procesate corespunzător.
- În funcție de industrie, atribuiți jobul numai etichetatorilor de date experți în domeniu.
- Asigurați-vă că o abordare uniformă este urmată de echipă, oferindu-le criteriile tehnicilor de adnotare care trebuie urmate.
- Urmați un proces de verificare prin alocarea mai multor adnotatori pentru etichetare încrucișată.
Î. Care sunt beneficiile etichetării datelor?
A. Etichetarea datelor ajută la oferirea unei mai bune clarități cu privire la context, calitate și utilizare pentru a face o predicție precisă a datelor. Acest lucru, la rândul său, ajută la îmbunătățirea gradului de utilizare a datelor variabilelor din model.
Î. Care sunt diferitele elemente de luat în considerare atunci când selectați companiile de etichetare a datelor pe lista scurtă?
R. Există cinci parametri de luat în considerare atunci când alegeți serviciile de etichetare a datelor pentru învățarea automată.
- Scalabilitate a procesului de etichetare a datelor
- Costul serviciului de etichetare a datelor
- Securitatea datelor
- Platforma de etichetare a datelor